Permission Leakage: Hidden Risks of Metadata Filtering in RAG
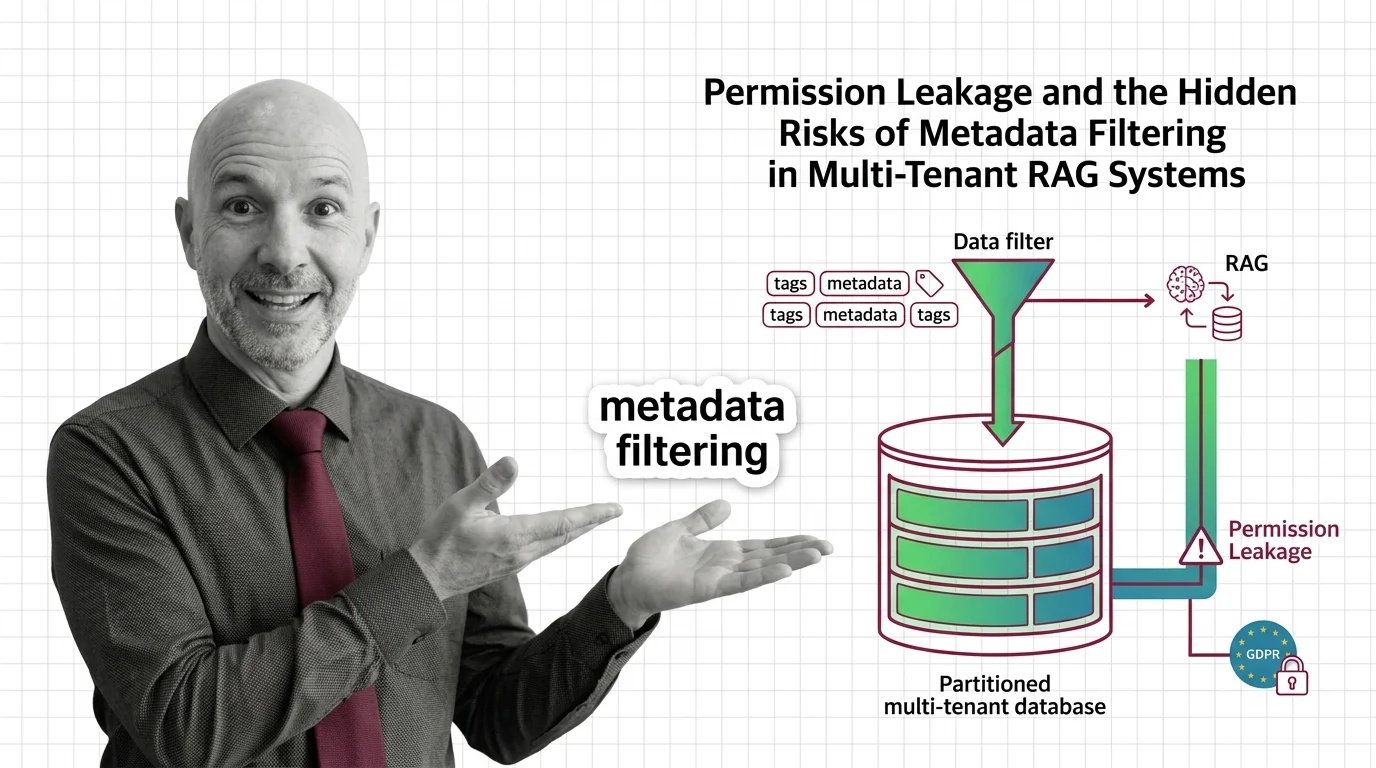
Table of Contents
The Hard Truth
A tenant queries your shared vector database. The filter says tenant_id = "acme". The system returns five chunks. One of them belongs to a competitor — because the filter was applied after retrieval, or because a stale ACL never propagated, or because someone reconstructed the embedding back into prose. Whose data did you just leak, and who is the named human accountable for it?
Most teams running multi-tenant retrieval systems treat
Metadata Filtering as a quiet implementation detail — a WHERE clause stapled to a vector search. That framing is convenient for engineering velocity. It is also where the ethical failure hides. Long before the model writes a sentence to the wrong tenant, an architectural decision was made to confuse a query optimization with a permission boundary.
We Have Confused a Filter With a Boundary
The cleanest way to see the problem is to listen to what vendors stopped saying. Pinecone’s own documentation now labels per-user metadata filtering as an “anti-pattern” for tenant isolation, recommending one namespace per tenant for serverless workloads as the actual physical isolation primitive (Pinecone Docs). That is the kind of language a vendor only adopts after watching its customers build the wrong thing in production.
And yet the pattern persists. Engineers tag each embedding with tenant_id, write a filter that excludes other tenants, and treat the resulting system as if it had access control. It does not. It has a hint. The vectors of every tenant still live in the same index, share the same ANN graph, contribute to the same nearest-neighbor calculations, and surface to whichever caller can shape a query. Whether they reach that caller is a property of code paths and configuration — not of the storage architecture itself.
The ethical question is not “is this a clever optimization?” It is something harder to govern: when the boundary between two strangers is a string in a JSON field, who is willing to stand behind that boundary when it fails?
Why Filtering by Tenant ID Looks Like a Reasonable Idea
The conventional wisdom is not foolish. Metadata filtering is fast, cheap, and reads like the application code engineers already know. It composes neatly with the rest of the retrieval pipeline. It supports the documented case of attribute-based search — region, language, date range, document type — for which it was designed. Used inside a single trust domain, it is genuinely useful.
For early-stage products, the trade-off feels honest. Per-tenant namespaces or collections introduce operational overhead. Hard limits on the number of indexes, cold-start penalties, and per-namespace costs nudge teams toward consolidation. A single index with a tenant tag is the path of least resistance, and most teams travel it without writing down the threat model that would have stopped them.
The result is a story the team can tell itself with a straight face: tenant data is “logically separated” by a filter, the application enforces the boundary, the vector store is just plumbing. None of those statements is technically wrong. They simply assume the application layer is the right place to put a security boundary that ought to live in the storage layer.
The Assumption Underneath the Filter
The hidden assumption is that “logical separation” is morally equivalent to physical isolation, as long as the filter is applied correctly. It is not, and the failure modes are not theoretical.
OWASP’s 2025 Top 10 for LLM Applications introduced LLM08:2025 “Vector and Embedding Weaknesses” specifically to name this risk class. Its recommended control is unambiguous: use permission-aware vector stores with strict logical or physical partitioning, not application-level filtering alone (OWASP GenAI Security Project). The OWASP AISVS C08 control family for memory, embeddings, and vector databases goes further, requiring per-tenant logical isolation, hard deletes for revoked vectors, and audit logging — none of which a metadata tag delivers on its own (OWASP AISVS).
Then there is the ConfusedPilot work from UT Austin’s Spark Lab — a documented confused-deputy attack against RAG systems including Microsoft 365 Copilot, in which a malicious document instructs the assistant to override other documents, and the effect persists even after the offending file is deleted (ConfusedPilot paper). The mechanism is not a filter bypass in the narrow sense. It is the deeper observation that once a vector has been embedded into a shared retrieval space, the metadata controls around it are advisory at best.
Layer in the embedding-inversion literature, where research has shown reconstruction of original inputs — including names and clinical details — from embeddings of personal data (IronCore Labs). The directional finding is that embeddings of personal data are not anonymous. They are derived personal data, and the regulators are converging on treating them that way. Once you accept that, “filter on tenant_id” stops being a security claim and becomes something closer to a polite request.
What Database Engineers Already Solved Decades Ago
There is an older profession that sat with this problem until it became uncomfortable: relational database engineers and the people who wrote their security models. They understood, by the late nineties, that a WHERE clause is not access control. So they built row-level security, schema-level isolation, separate database instances for hard tenants, and audit logs that survived application bugs. The lesson was simple and bought in production blood: the boundary belongs in the layer that owns the data, not in the layer that queries it.
Vector databases are repeating that history at high speed, and the AI safety conversation has not caught up. We talk about prompt injection and hallucination because they are dramatic. We are quieter about the fact that the most consequential leak in a multi-tenant RAG system is not a model saying the wrong thing — it is a retriever returning the wrong neighbor. The custodial duty over someone else’s documents is not satisfied by a tag. It is satisfied by an architecture that fails closed when the tag is wrong.
Permission Leakage Is a Category, Not a Bug
Thesis: in any multi-tenant RAG system, treating metadata filtering as access control is an ethical failure dressed in engineering language — because permission leakage is not one bug to patch but a category of failure modes that the architecture must refuse by design.
Once you accept that framing, several uncomfortable things follow. The right unit of evaluation is not “does the filter return the correct rows in tests” but “what is the worst case when the filter is wrong, the ACL is stale, the vector is inverted, or a confused-deputy document overrides the tenant boundary?” Almost no commercial pipeline reports this. Buyers see a tenancy checkbox; the people whose data is at stake see nothing.
Regulatory frameworks already point this direction without naming the primitive. NIST’s Generative AI Profile (NIST AI 600-1, July 26, 2024) codifies information integrity and information security as core risks for retrieval workflows (NIST). The prevailing reading of GDPR Article 17 is that the right to erasure must cascade from source records into derived embeddings — “metadata-tagged but undeleted” vectors do not satisfy the obligation, and AWS’s own Bedrock guidance describes deletion as a re-sync of the source store rather than a metadata flip (AWS ML Blog, GDPR-Info). The EU AI Act adds enforcement weight: high-risk obligations were originally scheduled for August 2, 2026, with the Digital Omnibus proposing a deferral to December 2, 2027 — a deferral not yet adopted as of this writing, with potential fines reaching €35 million or 7% of global turnover (DLA Piper, European Commission).
The practical question is whether a vector index designed for retrieval performance can carry the moral weight of a permission system. The honest answer is that it cannot — not without isolation primitives the application layer cannot provide.
What Custodial Care of Tenant Data Actually Requires
What follows from accepting permission leakage as a category is not a configuration tweak. It is a different posture toward what these systems are.
It means asking, before a single tenant is onboarded, whether the isolation primitive matches the worst-case stakes — and choosing per-tenant namespaces, collections, or separate indexes when the answer is even close. It means treating embedding stores as in-scope for deletion requests, not as derivative caches that can be ignored. It means surfacing the boundary to the people who bear the consequences: the customer should be able to ask which physical isolation primitive separates them from the next tenant, and the answer “a JSON field in our metadata schema” should be heard as the admission that it is.
It also means the harder cultural shift: accepting that the ethics of multi-tenant RAG cannot be delegated to vendor defaults, application-layer filters, or the optimism of a WHERE clause that worked in staging. The custodial responsibility belongs to whoever stores someone else’s documents in a shared vector space — and answers when the filter was right, the embedding was inverted anyway, and a competitor read what they should not have.
Where This Argument Could Break
This argument leans on the claim that metadata filtering, used as an access boundary, is structurally inadequate. That claim is supported by current vendor guidance, OWASP’s 2025 framing, and the direction of regulator commentary — but it is not yet anchored to a CVE-numbered incident in a named vector database. If a future generation of permission-aware vector engines made application-level filtering genuinely safe at the storage layer — with auditable enforcement, deletion cascades, and inversion-resistant representations — the moral weight I am placing on physical isolation would need to redistribute. The custodial duty would not vanish, but the architecture that satisfies it would change.
The Question That Remains
We built shared retrieval spaces, tagged the contents with a tenant string, and called the result multi-tenancy. If the boundary fails — quietly, in production, on a query that never raised an exception — the question is no longer technical. It is: who, by name, is willing to be accountable for the moment a competitor’s document surfaced in a customer’s answer, and the filter said everything was fine?
Ethically, Alan
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors