Patch Embeddings, Class Tokens, and 2D Positional Encoding: Inside the Vision Transformer
ELI5
A Vision Transformer cuts an image into small square patches, turns each into a token, prepends a learnable summary token, and lets self-attention compare every patch with every other — the same machinery that drives text models, now pointed at pixels.
For almost a decade, image models converged on the same recipe: stacks of convolutions that slid small filters over pixels, feature by feature, layer by layer. Then in 2020 a Google Brain team tried something that felt almost irresponsible — they deleted the convolutions, cut the image into a grid of 16×16 tiles, and fed the tiles to a plain Transformer that had no built-in notion of adjacency. With enough data, the network matched convolutional state of the art on ImageNet. The question is not whether this works. The question is why.
From Pixels to a Sequence the Transformer Can Read
The Vision Transformer (ViT) treats an image as a short ordered sequence. Before a single attention head fires, three small modules prepare that sequence: a patch embedder, a class token, and a position embedder. Every accuracy number, every fine-tuning trick, every multimodal alignment story lives downstream of how well these three pieces hand off to the encoder.
What are the main components of a Vision Transformer architecture?
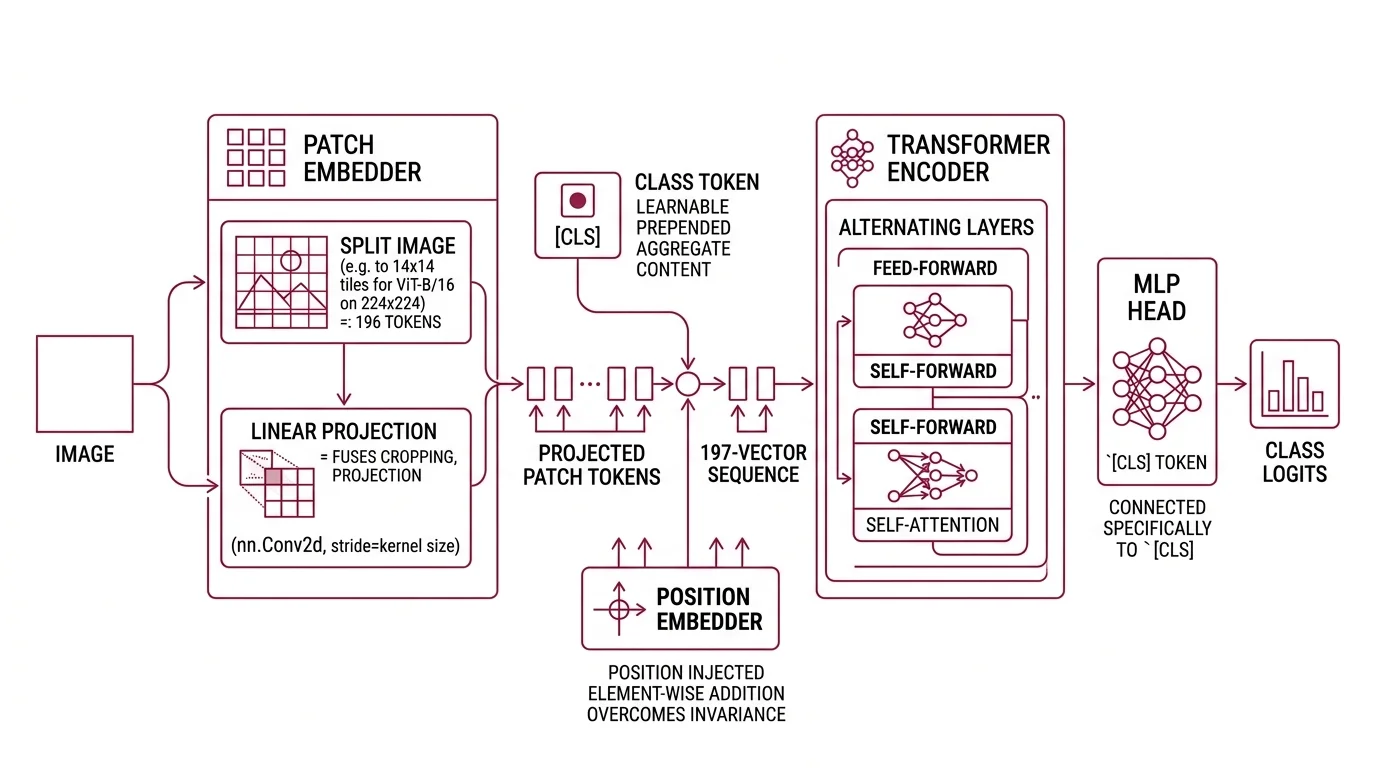
A ViT has five pieces that fit together like a pipeline.
First, the patch embedder splits the image into non-overlapping square tiles and linearly projects each tile into a D-dimensional vector. In practice, that “linear projection” is implemented with a single nn.Conv2d layer whose kernel_size and stride both equal the patch size — a shortcut that fuses cropping and projection into one op (Hugging Face Docs). For the canonical ViT-B/16 on a 224×224 image, the grid becomes 14×14 = 196 tokens (arXiv 2010.11929).
Second, a learnable [CLS] token is prepended to the sequence. It carries no image content; its job is to aggregate everything that follows.
Third, a positional embedding is added element-wise to every token. Self-attention is permutation-invariant — it has no intrinsic idea whether a patch came from the top-left or the bottom-right — so position has to be injected separately.
Fourth, the resulting 197-vector sequence flows into a standard Transformer encoder: alternating multi-head self-attention and feed-forward layers, identical in spirit to the Transformer Architecture used in text models.
Finally, an MLP head reads the final hidden state of the [CLS] token and produces class logits.
Not a redesign. A re-parameterisation.
The convolution at the front is easy to misread. Because stride = kernel_size, there is no overlap between patches and no pooling propagating locality through depth. The operation is algebraically equivalent to flattening each patch and multiplying by one weight matrix. ViTs therefore lack the translation equivariance and locality priors that CNNs build in at every layer, and they compensate with scale — more data, more compute, or a strong self-supervised objective. The
Patch Embedding step is the moment where pixel geometry is exchanged for raw sequence capacity.
The [CLS] Token: A Learnable Summary Slot
The class token is one of the quiet pieces of engineering that holds ViT together. It is a single D-dimensional vector learned from scratch, prepended to every input sequence. It has no associated patch. It sees every patch.
What is the CLS token in ViT and why is it used for classification?
Inside each Transformer block, the
Class Token hidden state is computed by attending to all patch tokens and itself. Because self-attention is a weighted sum over the entire sequence, the [CLS] slot ends each layer as a content-aware mixture of the patches it found most informative. After the final block, its hidden state is passed to the classification MLP head — no pooling, no flattening, no tricks (Hugging Face Docs). The network learns, by gradient descent, what a “whole image summary vector” should look like for the given task.
Why not just average the patch tokens? You can. And several successor architectures do. But the [CLS] slot has a property average pooling does not: it is a dedicated channel whose only job is aggregation. Attention weights flowing into the [CLS] token can specialise across layers without corrupting patch-level representations that later heads might still need.
The failure mode is equally informative. When a [CLS]-based ViT is confused, the failure rarely looks like noise — it looks geometric. The model over-attends to a dominant texture, and the [CLS] summary drifts with it. Probing experiments have shown that [CLS] attention maps cluster around salient objects, which is useful, and around high-contrast edges, which is sometimes not.
One clarification matters for anyone reading recent vision papers: the [CLS] token is not universal across Vision Transformers.
DINOv2 uses the class token as a self-distillation target rather than a classifier input. Several configurations of the
Masked Autoencoder (MAE) skip [CLS] entirely and take a global average over patch tokens during fine-tuning (arXiv 2111.06377). “ViT-style classification uses the [CLS] token” is precise; “all vision transformers use a [CLS] token” is not.
Positional Encoding: What the Original Paper Actually Did
This is where headlines get the mechanism wrong. The ViT paper is routinely credited with “2D positional encoding” because an image is obviously two-dimensional, so surely the position vectors must be too. That reading is tidy. It is also inaccurate.
How does 2D positional encoding work for image patches in ViT?
In the original paper, the Positional Encoding is a 1D learnable absolute embedding: a table of 197 vectors (one per token), each D-dimensional, added element-wise to the patch embeddings. The authors explicitly tested 2D-aware variants — sinusoidal 2D, factorised row/column, learned 2D grids — and reported no meaningful accuracy gain over the 1D baseline (arXiv 2010.11929). The model learned 2D structure from scratch, implicitly, via the gradient signal of the classification loss.
Not a design failure. A surprising empirical finding.
What people usually mean by “2D positional encoding in ViT” is one of two things, and they belong to different eras.
The first is an inference-time trick. When you fine-tune a ViT pre-trained at 224×224 on higher-resolution inputs — say 384×384 — the patch grid changes from 14×14 to 24×24. The pre-trained position table no longer matches the new sequence length. The standard fix is 2D bicubic interpolation: reshape the learned 1D embeddings into their original 2D grid, upsample to the new grid, flatten back to 1D, and continue training (Hugging Face Docs). That is a 2D operation on 1D embeddings — a detail, not a paradigm.
The second is a genuinely 2D scheme used by modern backbones. RoPE-ViT, introduced at ECCV 2024, adapts rotary position embedding — originally designed for text — to 2D image coordinates via two variants called Axial 2D RoPE and RoPE-Mixed. The overhead is roughly 0.01% of a ViT-B forward pass, a rounding error (arXiv 2403.13298). Google’s Gemma 4 vision encoder extends the same idea with spatial 2D RoPE, aligning image tokens with text tokens in the same multimodal stream.
So: 2D positional encoding in vision transformers is real, but it is largely a 2024–2026 development, not a 2020 one. The original ViT made its 2D world legible to a 1D position table and let optimisation fill in the rest.
What the Mechanism Predicts
Once you can see patches, [CLS], and positions as three small modules with distinct jobs, a useful set of priors falls out about when a Vision Transformer will and will not behave.
- If you change the patch size, you change both the sequence length and the receptive field of each token. Smaller patches (14×14 instead of 16×16) give longer sequences and finer-grained features; compute scales quadratically with sequence length at every attention layer.
- If you fine-tune at a higher resolution without interpolating the position embeddings, training loss tends to plateau and validation accuracy falls — not because the features are wrong, but because positions no longer correspond to anything the model saw in pre-training.
- If you swap the
[CLS]head for global average pooling without re-tuning, expect a small accuracy shift — typically down on ImageNet-style classification, often up on dense prediction tasks where patch-level features matter more than a summary vector. - If you feed a pure ViT trained on ImageNet-1K only to a high-resolution dense-prediction task, expect a hierarchical Swin Transformer or a convolutional backbone to beat it. Swin’s 87.3% top-1 on ImageNet-1K at release came directly from its hierarchical-windows insight (arXiv 2103.14030).
Rule of thumb: the more your task depends on fine spatial detail, the more you should pay attention to patch size and positional encoding — and the less you should rely on a single summary vector to hold everything.
When it breaks: ViTs trained from scratch on small datasets (a few hundred thousand to a few million images) consistently underperform CNNs of comparable size. The missing convolutional priors — translation equivariance, locality at every layer — have to be recovered from data, and without sufficient scale or a strong self-supervised objective, the model generalises poorly.
Security & compatibility notes:
- Hugging Face Transformers RCE (CVE-2026-1839): Training code that loads RNG state from untrusted checkpoints can be exploited via an unsafe
torch.load()call withoutweights_only=Truein_load_rng_state. Pin to a patchedtransformersrelease and load checkpoints withweights_only=True.- Transformers v5 API: The v5 major release removed long-standing v4 deprecations and refactored internals. Audit any v4-only helpers in your ViT pipeline before upgrading.
The Modern Line: Where the Three Pieces Are Going
None of the three ideas is fixed. Each is under active revision.
Patch handling is getting hierarchical. The Swin Transformer replaces global self-attention with shifted local windows and a patch-merging stage, trading expressivity for linear complexity in image size. The [CLS] token is being repurposed or replaced. DINOv3 (Meta, 2025) is a 7B-parameter ViT trained on 1.7B images that relies on self-distillation objectives over patch tokens, and at release it beat DINOv2,
SigLIP 2, and Meta’s Perception Encoder on most dense-prediction benchmarks (Meta AI Blog). Position encoding is moving from addition to rotation, from 1D to 2D.
Meanwhile, image–text systems built on the CLIP Model family still use standard patch embeddings under the hood — the same sequence geometry, connected by contrastive learning to a text encoder. As of April 2026, NVIDIA’s C-RADIOv4 distils SigLIP 2, DINOv3, and SAM 3 into a single ViT student, which tells you where the bet is: the Transformer backbone is not going away, but the three small modules at its front door are where most of the new work is being done.
The Data Says
The Vision Transformer works because a short sequence of patch tokens, a single learnable summary slot, and a 1D position table turned out to be enough for attention to rediscover spatial structure from scratch — given sufficient data. The shift to 2D rotary position encoding and self-distilled patch representations is not a repudiation of that design; it is a refinement of where the inductive bias should live.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors