OWASP LLM Top 10, MITRE ATLAS, and the Frameworks That Structure AI Red Teaming

Table of Contents
ELI5
AI red teaming frameworks like OWASP LLM Top 10 and MITRE ATLAS give security teams a structured catalog of known AI vulnerabilities — turning adversarial testing from creative guesswork into systematic coverage.
Two security teams test the same chatbot. One improvises — creative Jailbreak attempts, edge-case inputs, whatever looks interesting. The other opens a numbered vulnerability list and writes targeted tests against each entry. The second team finds the critical flaw in the retrieval pipeline that the first team never thought to probe.
The difference isn’t talent. It’s taxonomy.
The Skeleton Key — What Gives a Framework Its Structure
The instinct is to treat Red Teaming For AI as improvisational performance — find the clever prompt, break the model, post the screenshot. This instinct reliably discovers surface-level failures: rude outputs, trivial bypass exploits, the occasional embarrassing Hallucination.
What it systematically misses are the architectural vulnerabilities — supply chain poisoning, vector database manipulation, unconstrained agent permissions — that live not in the model’s weights but in the system surrounding it. The frameworks exist because adversarial testing without a taxonomy is organized guessing.
What are the main components of an AI red teaming framework?
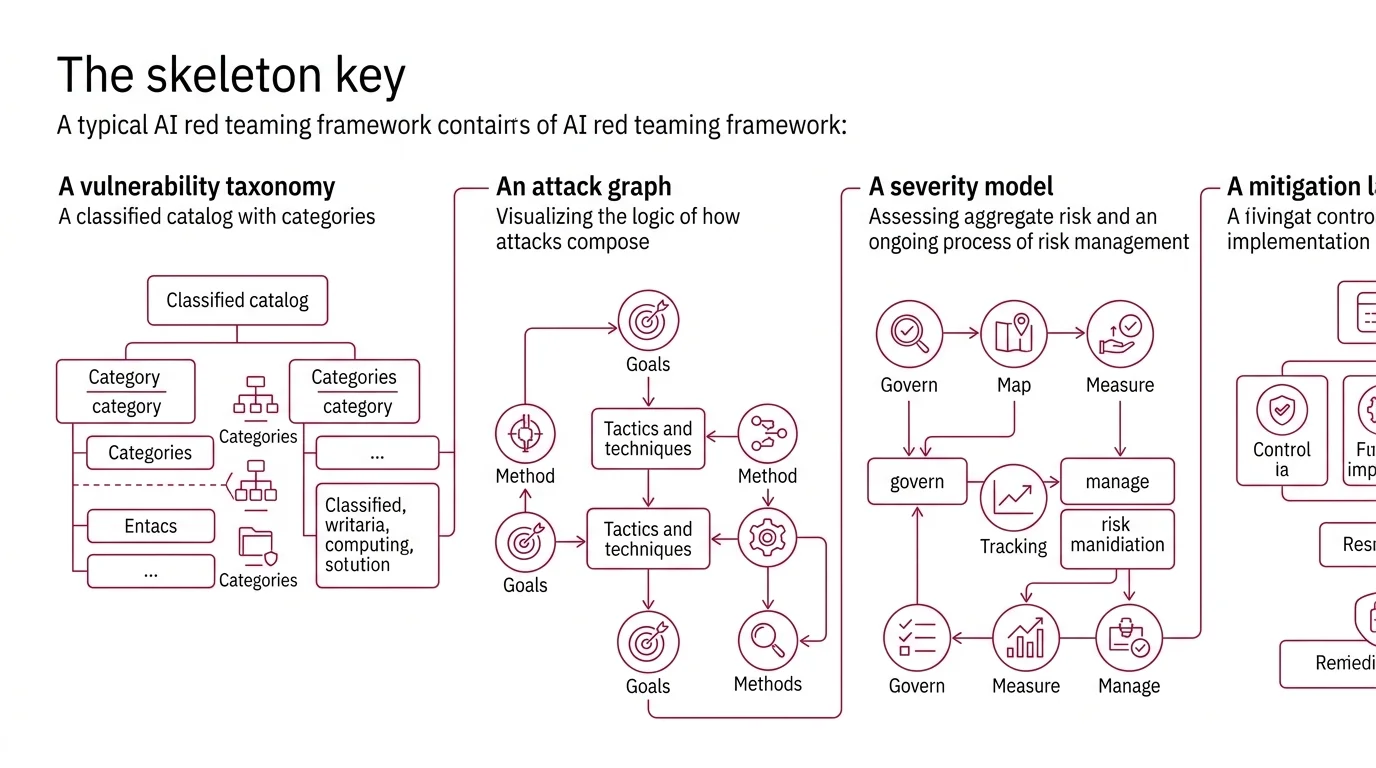
A framework for AI red teaming typically contains four structural layers, each solving a different problem.
A vulnerability taxonomy — a classified catalog of what can go wrong. The Owasp LLM Top 10 provides this as a ranked list of ten vulnerability categories, ordered by aggregate risk. Mitre Atlas offers a finer-grained version: 15 tactics and over 60 techniques that map adversarial behaviors across the full AI lifecycle, from reconnaissance through impact (MITRE ATLAS).
An attack graph — the logic of how attacks compose. MITRE ATLAS inherits this structure from ATT&CK: tactics represent adversarial goals (initial access, persistence, exfiltration), and techniques represent the specific methods used to achieve them. A single red team engagement might chain multiple tactics in sequence, the same way a traditional penetration test chains exploits across network segments.
A severity model — how bad is it? OWASP orders its list by aggregate risk assessment. NIST’s AI Risk Management Framework approaches the same question from a different angle: four core functions — Govern, Map, Measure, Manage — that organize risk as an ongoing process rather than a one-time score (NIST).
A mitigation layer — what to do about what you find. MITRE ATLAS documents 26 mitigations tied to specific techniques. OWASP links each vulnerability to prevention strategies. Without this layer, a framework is a horror movie with no exits.
These four layers determine whether a red team produces a list of broken prompts or a structural risk assessment that an engineering team can act on.
What do you need to understand before starting AI red teaming?
Before engaging a framework, three prerequisites separate productive testing from noise.
First: the system architecture. An LLM embedded in a retrieval-augmented generation pipeline has a fundamentally different attack surface than a standalone chatbot. Prompt Injection takes on a different character when the injected content arrives not from the user but from a poisoned document inside a vector database. Understanding where external data enters the system — and with what trust level — determines which framework categories apply.
Second: the threat model. Not every vulnerability matters equally for every deployment. A customer-facing chatbot prioritizes sensitive information disclosure (OWASP LLM02). An autonomous agent with tool access prioritizes excessive agency (LLM06). The framework provides the full map; the threat model tells you which rooms to search first.
Third: the distinction between model-level and system-level vulnerabilities. Jailbreaks and hallucinations are model behaviors. Supply chain attacks, output handling failures, and unbounded resource consumption are system architecture problems. Confusing the two leads to red teams that test the model exhaustively while the infrastructure connecting it to the world goes untouched.
Not a testing failure. A scoping failure.
Ten Vulnerabilities and the Logic Behind Their Order
OWASP does not organize its list alphabetically or by technical elegance. The ordering reflects aggregate risk — a composite of exploitability, prevalence, and impact severity assessed across real deployments. Understanding the ranking logic matters because it tells you where the community’s collective pain concentrates — and where your red team should spend its first hours.
What attack categories does the OWASP LLM Top 10 cover?
The 2025 edition, published November 2024 and updated April 2025, defines ten categories (OWASP GenAI):
| # | Category | Attack surface |
|---|---|---|
| LLM01 | Prompt Injection | Adversarial input that hijacks model behavior |
| LLM02 | Sensitive Information Disclosure | Unintended leakage of training data or PII |
| LLM03 | Supply Chain | Compromised models, plugins, or training data sources |
| LLM04 | Data and Model Poisoning | Manipulation of training or fine-tuning data |
| LLM05 | Improper Output Handling | Downstream code execution from model output |
| LLM06 | Excessive Agency | Agent actions exceeding intended permissions |
| LLM07 | System Prompt Leakage | Extraction of hidden system instructions |
| LLM08 | Vector and Embedding Weaknesses | Attacks on RAG retrieval and embedding pipelines |
| LLM09 | Misinformation | Model-generated false content treated as fact |
| LLM10 | Unbounded Consumption | Resource exhaustion through crafted inputs |
Two entries are new to the 2025 edition: System Prompt Leakage (LLM07) and Vector and Embedding Weaknesses (LLM08). Their inclusion reflects where real-world attacks have concentrated — attackers increasingly target the retrieval infrastructure, not just the model itself. When your RAG pipeline trusts every document it retrieves, a single poisoned embedding can silently redirect the model’s outputs without triggering any prompt-level defense.
This is the structural insight the list encodes. The most dangerous LLM vulnerabilities in production systems are increasingly system-level, not model-level. Prompt injection holds the top position because it remains both common and readily exploitable. But the categories gaining ground — supply chain, vector weaknesses, excessive agency — describe failures in the architecture around the model, where most teams have less adversarial intuition and fewer established defenses.
What the list deliberately excludes matters too. Traditional web vulnerabilities — SQL injection, XSS, buffer overflows — are absent. The OWASP LLM Top 10 is scoped exclusively to vulnerabilities specific to or amplified by LLM integration. An application using an LLM still needs the original OWASP Top 10 for its conventional attack surface.
From Vulnerability Catalog to Kill Chain — The MITRE ATLAS Approach
Where OWASP asks “what can go wrong?”, MITRE ATLAS asks “how does an adversary get there?”
ATLAS — Adversarial Threat Landscape for Artificial-Intelligence Systems — models adversarial behavior as sequences of tactics and techniques, mirroring the structure of MITRE ATT&CK for traditional cybersecurity. As of early 2026, the framework documents 15 tactics, over 60 techniques, and 33 case studies of real-world adversarial operations (MITRE ATLAS). The exact technique count continues to grow; a 2025 update added 14 techniques focused on agentic AI threats — prompt injection vectors and memory manipulation attacks targeting autonomous agents (Zenity). A 2026 update introduced five more techniques covering AI service APIs, tool credential harvesting, and data destruction via agent tools.
This expansion is not bureaucratic category inflation. Each addition represents a documented attack pattern observed in deployment or demonstrated in structured adversarial research. The OpenClaw investigation in February 2026 alone contributed seven new techniques discovered through systematic probing of agentic systems.
What makes ATLAS structurally different from OWASP is composability. OWASP categories are largely independent — prompt injection and excessive agency exist as separate entries. ATLAS techniques chain: an attacker might exploit prompt injection to achieve initial access, then harvest tool credentials to escalate privileges, then execute data destruction through an agent’s own interfaces. The kill chain is the framework’s explanatory power — not the individual entries, but the paths between them.
NIST’s AI Risk Management Framework occupies a different altitude entirely. Where OWASP and ATLAS model attackers, NIST AI RMF is organizational. Its four functions (Govern, Map, Measure, Manage) structure how an institution identifies, assesses, and responds to AI risk as a continuous process. The GenAI Profile (NIST-AI-600-1, released July 2024) extends this to generative AI. You don’t red team with NIST. You use NIST to decide what to red team — and how to act on what you find.
When the Frameworks Collide With Reality
If your red team tests only model-level vulnerabilities — prompt injection, jailbreaks, hallucination coercion — expect to miss the system-level failures that OWASP categories LLM03 through LLM08 were designed to catch. The frameworks predict this gap; the 2025 edition expanded its scope specifically to address it.
If your organization runs autonomous agents with tool access, the MITRE ATLAS agentic techniques are not optional reading. Excessive agency (LLM06) combined with tool credential harvesting describes a scenario where an agent silently escalates its own permissions — a documented technique category, not a theoretical concern.
If your system uses retrieval-augmented generation, LLM08 demands specific attention: test whether adversarial documents can shift retrieval rankings, whether embedding similarity thresholds reject irrelevant injections, and whether the system trusts retrieval results uniformly regardless of source provenance.
Rule of thumb: Use OWASP to scope what to test. Use ATLAS to model how attacks chain. Use NIST to justify the program and structure the organizational response.
One tool worth noting for execution: Promptfoo covers over 50 vulnerability types including prompt injection, PII leaks, and jailbreaks (Promptfoo Docs). The tool was acquired by OpenAI in March 2026 but remains open-source under the MIT license (The Next Web). Post-acquisition project direction is still evolving, so verify the tool’s current status and roadmap before building a long-term testing workflow around it.
When it breaks: Frameworks catalog known vulnerability categories. They do not predict novel attack vectors. A red team that tests only against the published lists achieves coverage of documented risks — and zero coverage of whatever the next LLM07 turns out to be. The frameworks are a floor, not a ceiling.
The Data Says
AI red teaming frameworks solve the taxonomy problem: they ensure adversarial testing covers the structural categories of failure, not just the creative ones. The shift from OWASP’s ranked vulnerability list to MITRE ATLAS’s composable kill chains reflects a maturing discipline where the question is no longer “can this model be broken?” but “how would an adversary systematically break the system around it?”
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors