Oversmoothing, Scalability Walls, and the Hard Technical Limits of Graph Neural Networks
ELI5
Graph neural networks blur node features as layers deepen — each message-passing round averages signals until every node looks the same, and scaling up makes fixing this prohibitively expensive.
In almost every deep learning architecture, adding layers means adding capacity. More depth, more abstraction, more representational power. Graph Neural Network architectures invert this expectation. Stack too many layers on a graph, and the model does not learn more — it forgets what made each node different in the first place. That inversion is not a bug in a particular implementation. It is a mathematical property of how information moves through graph structure, and it imposes a ceiling that no amount of hyperparameter tuning can raise.
The Averaging Machine Inside Every Layer
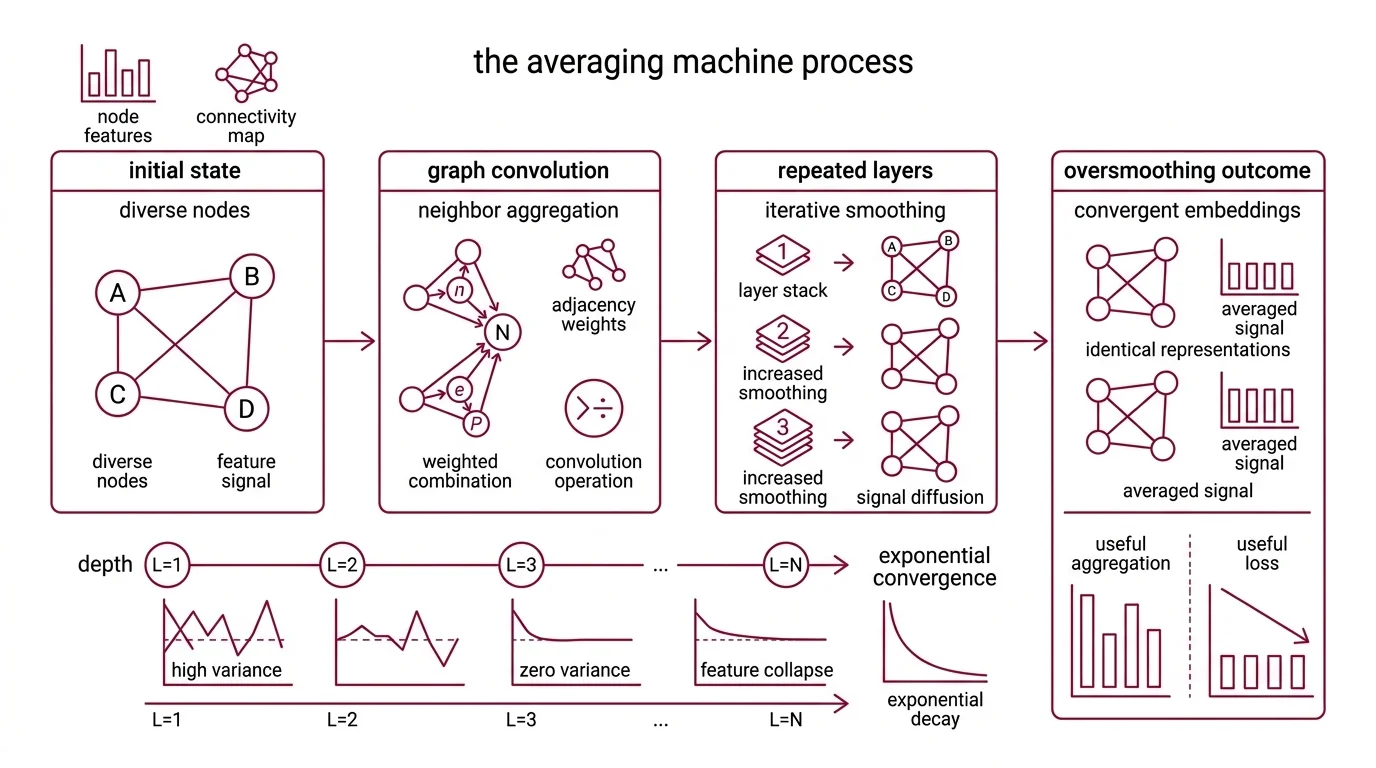
Every Graph Convolution operation performs a deceptively simple act: it replaces each node’s representation with a weighted combination of its neighbors’ representations. The weights come from the Adjacency Matrix — the graph’s own connectivity structure. One round of this looks like useful information aggregation. The question that determines everything is what happens when the operation repeats.
What is oversmoothing in graph neural networks and why does depth make it worse?
Oversmoothing is what happens when graph convolutions are applied iteratively: every node’s Node Embedding converges toward the same point in feature space. Li et al. formalized this in 2018, demonstrating that a Graph Convolutional Network is mathematically equivalent to a special form of Laplacian smoothing (Li et al.). Each layer applies the smoothing operator once. Stack enough layers, and every node in the graph carries an almost identical representation.
The mechanism is geometric. Imagine a signal on a graph — some nodes are “hot,” others are “cold.” One round of neighbor-averaging cools the extremes slightly, the way heat diffuses across a metal surface. Two rounds diffuse further. After several layers, the temperature is uniform everywhere. The signal that once distinguished node A from node B has been averaged out of existence.
Rusch et al. gave this a formal characterization in 2023: node feature similarity converges exponentially with depth (Rusch et al.). Not linearly — exponentially. The useful signal does not degrade gracefully; it collapses at a rate that makes additional layers actively destructive past a shallow threshold. The exact depth at which performance degrades varies by architecture and dataset — there is no universal number — but the direction is consistent.
Spectral Graph Theory clarifies why. Graph convolution operates as a low-pass filter on the graph’s spectral domain — preserving slow-varying components (global structure) while suppressing fast-varying ones (local distinctions between nearby nodes). A low-pass filter applied once extracts useful information. Applied iteratively, it eliminates everything except the graph’s dominant eigenvector. All nodes converge to one point.
Can attention mechanisms fix this? Graph Attention Network architectures assign learned weights to different neighbors rather than treating them equally — a more selective aggregation. Wu et al. tested this directly at NeurIPS 2023, and the answer is no; attention mechanisms cannot prevent oversmoothing (Wu et al.). The convergence is driven by the iterative aggregation structure itself, not by how individual steps are weighted. Different weights slow the collapse but do not halt it.
Not a tuning problem. A structural limit.
The Neighbor Explosion and the Price of Reaching Further
The Message Passing framework defines how most GNNs operate: each node sends messages to neighbors, receives messages in return, and updates its own state. One layer equals one hop of communication. Two layers, two hops. To let distant nodes influence each other, you need more layers — which, as established above, destroys the signal you are trying to propagate. This creates an architectural tension with no clean resolution within the standard MPNN framework.
Why do graph neural networks struggle with long-range dependencies and large-scale graphs?
Two failure modes emerge from the same design decision — local message passing — and they compound each other.
The first is the depth-range trap. MPNNs capture only k-hop local neighborhoods (Shehzad et al.). If task-relevant nodes are separated by more hops than the model has layers, no message can travel between them. But adding enough layers to bridge that distance will have oversmoothed the features into noise long before the message arrives. Information has a finite travel distance before it dissolves.
The second is the neighbor explosion. Even if oversmoothing were somehow solved, scale imposes its own wall. Training on large graphs requires sampling neighborhoods for mini-batches, and the number of nodes in those neighborhoods grows exponentially with the number of layers — the primary computational bottleneck in GNN training (GNN Scalability Book). Graphsage addressed this with sampling-based aggregation: randomly selecting a fixed number of neighbors per layer to control growth. The trade-off is information loss — you approximate the full neighborhood with a sample, and that approximation degrades as graphs grow larger and sparser.
For Knowledge Graph applications, where meaningful relationships routinely span many hops, this combination is especially punishing. The model either oversmoothes trying to reach distant nodes, or truncates its receptive field and misses the relationship entirely.
Graph transformers attempt to sidestep both problems by replacing local message passing with self-attention over all nodes — any node can attend to any other regardless of graph distance. But this trades one scalability constraint for another: self-attention is quadratic in the number of nodes. As of 2026, graph transformer scalability remains an active research area with no settled consensus on the right balance between range and computational cost.
Where the Ceiling Meets the Floor
The practical implications split along two axes, and the right response depends on which side of the divide your problem sits.
If task-relevant information is local — within a few hops — standard GNN architectures remain effective. The oversmoothing ceiling does not matter because you never approach it. Most node classification benchmarks fall into this category, which explains why GNNs look powerful in the literature.
If the task requires long-range reasoning — predicting molecular properties that depend on distant atom interactions, detecting fraud rings that span multiple intermediary accounts, or answering multi-hop knowledge graph queries — the message-passing paradigm becomes the constraint. Adding depth does not help; it hurts. Adding width (more features per layer) delays the problem without resolving it.
A few heuristics survive the math:
- If the task is local, a shallow GNN with residual connections handles it well. Depth should be treated as a parameter with diminishing — and eventually negative — returns.
- If the task demands long-range context, evaluate whether a graph transformer or a hybrid architecture fits within your compute budget before defaulting to a deeper MPNN.
- If the graph contains millions of nodes, sampling-based methods become necessary — with the understanding that you trade completeness for tractability.
Rule of thumb: The optimal GNN depth is nearly always shallower than intuition from convolutional or transformer architectures suggests.
When it breaks: The hard ceiling appears when a task demands both long-range dependencies and large-scale graphs simultaneously. No current architecture handles this combination without significant approximation; graph transformers solve range but not scale, while sampling-based MPNNs solve scale but not range.
Compatibility note:
- DGL (Deep Graph Library): NVIDIA is discontinuing DGL containers after the 25.08 release and recommends migration to PyTorch Geometric (NVIDIA Docs). The last DGL release was v2.4.0 in September 2024 (DGL GitHub). Evaluate migration timelines if your training pipeline depends on DGL.
The Data Says
Graph neural networks carry a ceiling written into their mathematics: the aggregation mechanism that makes them powerful on local structure is the same mechanism that destroys their ability to reason over distance. Oversmoothing is not a failure of specific models — it is a property of iterative neighbor averaging, and scalability walls compound the limitation by making deeper or wider alternatives prohibitively expensive. The hardest problems in graph learning sit in the gap between what local message passing can reach and what global attention can afford.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors