Opaque Defaults and Locked Knobs: The Ethics of Who Controls LLM Sampling Parameters
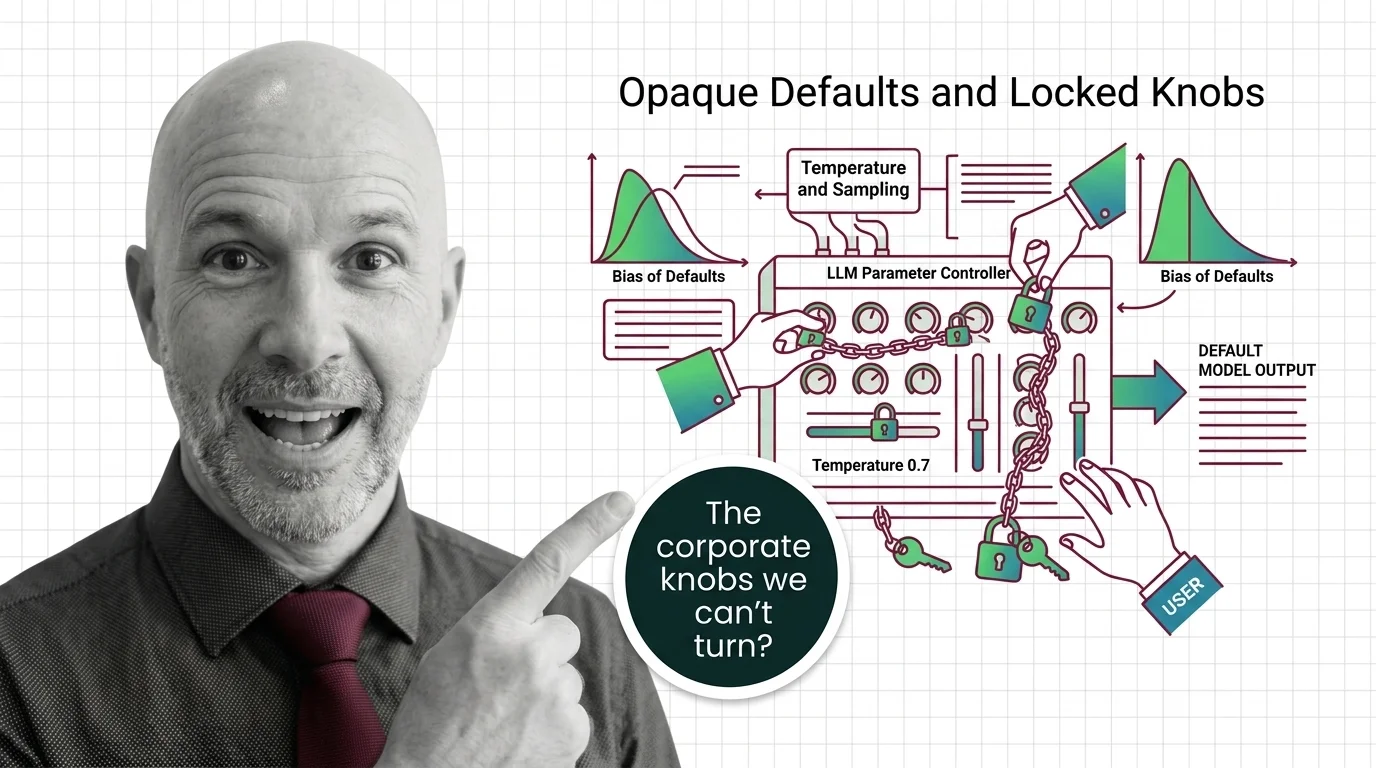
Table of Contents
The Hard Truth
Imagine an instrument with a hundred knobs, each one shaping the sound. Now imagine the manufacturer welds most of them in place and tells you the settings are “optimal.” You can still play. But whose music are you making?
When OpenAI released its GPT-5 reasoning models, something quietly disappeared from the API. Temperature And Sampling — the parameter that governs how much randomness a model injects into its outputs — was locked at 1.0. Not deprecated, not hidden behind a flag. Actively blocked, along with top_p, presence_penalty, and frequency_penalty (OpenAI Community). Anthropic’s Claude now returns an error if you try to set temperature and Top P Sampling simultaneously (Anthropic Docs). Google’s Gemini documentation “strongly recommends” leaving temperature at 1.0, warning that lowering it may cause looping or degraded reasoning (Google Cloud Docs). Three companies, three different mechanisms, one shared direction: the user has less control than they did a year ago.
The Defaults Nobody Chose
Every commercial LLM ships with default sampling parameters — temperature, top_p, Min P Sampling, penalties for repetition. These defaults determine how a model distributes probability across its output tokens, shaping everything from creative variation to factual consistency. They are, in effect, the editorial policy of the system. They decide how much the model is allowed to surprise you.
And yet these values are chosen behind closed doors. OpenAI sets temperature to 1.0 with a range of 0 to 2. Anthropic sets it to 1.0 with a range of 0 to 1. Google sets it to 1.0 and warns you not to change it. The numbers sound similar, but the ranges tell different stories about what each company considers acceptable variation. No public reasoning accompanies these choices. No external body audits them. The defaults arrive as facts — not proposals.
Who decides the default sampling parameters in commercial LLM APIs, and what biases do those defaults encode? The question sounds technical. It is not. It is a question about whose judgment we are importing every time a model generates a response, and whether the people on the receiving end — developers, enterprises, end users — have any meaningful way to interrogate that judgment.
The Reasonable Case for Guardrails
It would be dishonest to pretend there is no rationale for restricting access. The engineers who locked GPT-5’s temperature had a defensible reason: multi-pass reasoning architectures break when users force deterministic paths. Collapsing the distribution eliminates the search space the model needs to reason through, producing worse outputs, not better ones (OpenAI Community). There is an engineering argument — a strong one — that some parameters are not “preferences” but load-bearing components of the system’s cognitive architecture.
Anthropic’s mutual exclusion constraint follows a similar logic. When two sampling methods interact in unpredictable ways, restricting one to make the other reliable is a reasonable trade-off. Google’s recommendation against changing Gemini’s temperature is framed as guidance, not a hard lock, which at least preserves the form of choice.
The steelman goes further. Most users do not understand what Logits are, do not grasp the difference between Greedy Decoding and nucleus sampling, and would produce worse outcomes with unrestricted access. If the goal is to maximize output quality for the broadest population, then sensible defaults — even enforced ones — serve that goal. This is not a new argument. It is the same argument that justifies seatbelt laws, building codes, and pharmaceutical dosing standards.
The Assumption Inside the Lock
But there is an assumption nested inside that logic, and it deserves examination. The assumption is that the provider’s judgment about “optimal” is transferable — that what is best for the median user is acceptable for every user. That Inference quality can be defined once and applied universally without context.
This assumption collapses in high-stakes environments. A healthcare company building an AI assistant cannot demonstrate deterministic behavior to regulatory auditors when the model’s sampling parameters are locked — variance in generation can, as one analysis noted, “hallucinate drug dosages” (Swept AI). A legal team running document analysis needs reproducibility. A research lab running controlled experiments needs to isolate variables. For these users, locked parameters are not guardrails. They are walls between them and the accountability their work demands.
The deeper issue is not whether locking parameters is sometimes justified. It is that the justification is invisible. When a provider decides what users can and cannot control, that decision is a form of governance. And governance without transparency is just authority.
A History of “Trust Us”
This pattern has precedent. When broadcast radio emerged in the early twentieth century, regulators argued that the electromagnetic spectrum was a public resource requiring centralized management. That argument was technically sound — uncoordinated broadcasting causes interference. But centralized control over broadcast parameters also determined who could speak, what could be said, and which communities received service. The technical rationale was real. So was the power it concentrated.
The analogy is imperfect, but the structure rhymes. LLM providers control the parameters that shape AI-generated speech — not through censorship of content, but through the quieter mechanism of constraining the generation process itself. A temperature lock does not silence a topic. It shapes how confidently the system speaks about every topic. And the people affected — the developers building on these APIs, the enterprises depending on reproducibility, the researchers studying model behavior — had no seat at the table when the decision was made.
The Stanford Foundation Model Transparency Index scored the industry at an average of 40 out of 100 in its 2025 assessment, down from 58 the previous year — an average that, it is worth noting, masks wide variance across individual companies (Stanford CRFM). But the overall direction is unmistakable: the industry is growing more opaque, not less, even as the systems become more consequential.
Opacity as Governance
Thesis (one sentence, required): When providers lock or constrain sampling parameters without publishing their reasoning, they exercise a form of governance over AI behavior that operates without the accountability we demand of any other institution shaping public outcomes.
This is not a call to throw open every knob. It is a call to treat parameter decisions with the seriousness they deserve. The EU AI Act’s Article 50, enforceable from August 2026, requires transparency about AI interactions and labeling of synthetic content (EU AI Act). National and international frameworks — NIST’s AI risk profiles, model card standards, emerging audit protocols — are converging on the same principle: that disclosure should be the norm, not the exception. Yet none of these instruments directly addresses the specific question of sampling parameter governance — the decisions about how a model generates, not just what it generates.
Should users have full control over LLM sampling, or do safety-motivated constraints justify restricting access? The honest answer is that the question itself is malformed. It presents a binary where the real answer is conditional: it depends on the user, the context, the stakes, and the availability of informed consent. A Quantization-aware researcher and a first-time chatbot user have different needs and different risk profiles. Treating them identically — by locking parameters for everyone or unlocking them for everyone — serves neither well.
The Questions That Follow
What would responsible parameter governance look like? Not full deregulation — that solves nothing. And not the current regime of silent defaults — that concentrates power without accountability. Something in between: published rationales for parameter constraints, tiered access models that distinguish between casual and expert users, independent audit mechanisms that verify whether defaults serve users or merely reduce support tickets.
The harder question is whether the companies building these systems have any incentive to move in that direction. Transparency is expensive. It invites scrutiny. It creates surface area for criticism. The path of least resistance is the one we are already on — opaque defaults, locked parameters, and documentation that tells you what but never why.
Where This Argument Is Weakest
The most honest objection is practical. Most users genuinely do not need parameter access, and the cognitive burden of managing Continuous Batching strategies, sampling distributions, and penalty coefficients would degrade their experience. If transparency means overwhelming non-expert users with controls they cannot interpret, the cure is worse than the disease. It is also possible that providers are quietly iterating toward better defaults faster than any external governance body could — that the lock is temporary, a bridge to an adaptive system that tunes parameters per context automatically. If the next generation of models ships with context-aware parameter tuning that outperforms any manual setting, this entire argument becomes a relic of the transition period.
The Question That Remains
We have spent years arguing about what AI systems should and should not say. The quieter question — the one embedded in every API call, every default configuration, every locked parameter — is who controls how they think. And whether we will demand the same accountability for that question as we do for any other form of power exercised without consent.
Disclaimer
This article is for educational purposes only and does not constitute professional advice. Consult qualified professionals for decisions in your specific situation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors