Negative Prompts, Weights, Seeds: Image Prompting Limits 2026
ELI5
Negative prompts, weight syntax, and fixed seeds reproduce reliably only inside a single model version, on a single tool, on a single GPU. Change any of those three and the same prompt produces a different image — sometimes a structurally different one.
You wrote a
Prompt Engineering For Image Generation prompt last year. It worked. You ran it again this morning — same seed, same wording, same (masterpiece:1.3) brackets — and the model handed you a stranger. Nothing about your input changed. Everything about what surrounded the input did.
The tempting conclusion is that the model “drifted.” The accurate one is harder: prompts were never a portable language. They were always an interface to one specific architecture, one specific tool, one specific scheduler — and that surface keeps shifting underneath them.
What “Weight Syntax” Actually Is — And Where It Lives
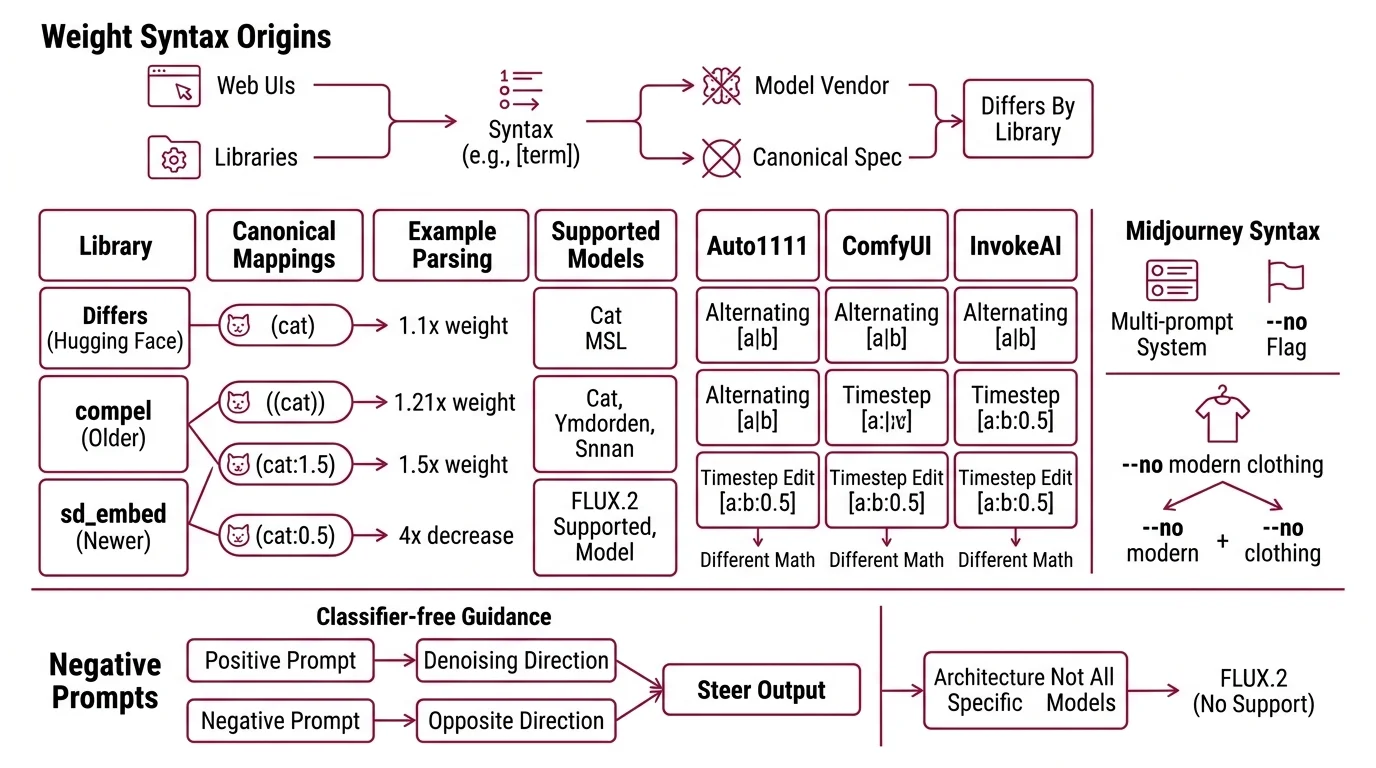
There is no canonical specification for prompt weighting. The widely shared (term:1.3) and [term] notations did not come from a model paper or from a model vendor — they emerged from web UIs and from conditioning libraries, and each one parses them slightly differently. The math is real, but the math is local.
In Diffusers — the Hugging Face library that most production pipelines for
Diffusion Models sit on top of — the canonical mapping is (cat) = 1.1×, ((cat)) = 1.21×, (cat:1.5) = 1.5×, and (cat:0.5) decreases the weight by 4× (Hugging Face Diffusers Docs). The recommended library for parsing this in 2026 is sd_embed, which replaced the older compel package and supports SD, SDXL, SD3, Stable Cascade, and Flux. Auto1111 webui uses a different parser with extensions like [a|b] for alternating prompts and [a:b:0.5] for prompt-editing across timesteps. ComfyUI and InvokeAI parse those extensions differently again. Same brackets. Different math.
Midjourney avoids the bracket convention entirely. Its --no flag is documented as equivalent to weighting a term at -0.5 in its multi-prompt system (Midjourney Docs). The parser is also positional and word-by-word: --no modern clothing is read as --no modern plus --no clothing, not as a single negated phrase. That kind of detail is invisible at the prompt-string level and decisive at the output-image level.
Negative prompts are an architectural feature, not a universal one
The phrase “negative prompt” sounds like a generic capability. Mechanically, it is a second conditioning input fed into classifier-free guidance: the model computes one denoising direction toward the positive prompt and one away from the negative, then steers between them. That requires the architecture to expose two separate text-conditioning streams.
Not every architecture does. FLUX.2 documents this explicitly: “FLUX.2 does not support negative prompts. Focus on describing what you want, not what you don’t want” (Black Forest Labs Docs). The OpenAI GPT Image 2 API exposes only quality, size, format, compression, and n — no seed, no negative_prompt (OpenAI API Docs). The Diffusers maintainers add a relevant note: “Prompt weighting doesn’t necessarily help for newer models like Flux which already has very good prompt adherence” (Hugging Face Diffusers Docs).
So a workflow built around negative prompts on SDXL is not portable forward. It’s not that the syntax broke — there is no syntax to break. Not a deprecated feature. A missing architectural slot.
The Reproducibility Illusion
If weight syntax is parser-local, the seed is hardware-local. The Diffusers documentation puts it bluntly: “you can try to limit randomness, but it is not guaranteed even with an identical seed” (Hugging Face Diffusers Docs).
The reasons are mechanical, not mysterious. The GPU and the CPU use different random number generators, so the same integer seed produces different initial noise tensors depending on which device samples it. Diffusers recommends instantiating torch.Generator on CPU specifically to make seeds portable across machines. Even that is not enough on its own — full determinism requires enable_full_determinism(), which sets CUBLAS_WORKSPACE_CONFIG=:16:8, disables cudnn.benchmark, and disables TF32, at the cost of throughput. And the Generator object itself carries state: once consumed, the same Generator produces different results in subsequent calls because its internal counter has advanced.
Resolution is the other invisible variable. Changing image dimensions by a single pixel generates a different latent and a different image even with identical seed and prompt (getimg.ai Seed Guide). The latent is shaped by output dimensions; the seed only initializes noise within that shape.
Why do prompts produce different results across model versions in 2026?
The honest answer is that “the same prompt” is a fiction at the model boundary. Different image models use different text encoders — CLIP variants in older Stable Diffusion, T5 in Flux, a multimodal LLM in GPT Image. The string "a calico cat on a windowsill" becomes a different conditioning vector inside each one before any noise schedule is applied. From the model’s point of view, you are not running the same prompt; you are running structurally different inputs that happen to share an English surface form.
Within a single model family, the same problem appears at smaller scale across versions. The Auto1111 webui wiki documents a long list of breaking changes that affect seeds between September 2022 and January 2024 — zero-terminal-SNR introduced in 1.8.0, prompt-editing timeline reworked in 1.6.0, the LoRA weight method changed, DPM++ SDE batching changed, Karras sigma values changed, the emphasis parser changed (Auto1111 webui Wiki). Each of those moves the noise schedule or the conditioning math. None of them changes the seed integer. All of them change the output.
The current image-arena leaderboard (Artificial Analysis, scanned April 2026) makes the architectural fragmentation visible. As of April 2026, the top ELO leaders — GPT Image 2, GPT Image 1.5, Nano Banana 2, and Nano Banana Pro — are autoregressive or multimodal systems where seed control and weight syntax do not apply uniformly. The diffusion-family models, where these levers actually exist, sit lower on the same leaderboard. The practitioner choice is no longer between “good prompt” and “bad prompt” — it is between models where prompts are levers and models where prompts are descriptions.
What This Predicts You Will See
If the mechanism is parser-local syntax plus version-local seed plus architecture-specific conditioning, certain failure patterns are predictable rather than surprising:
- If you upgrade Auto1111 webui across a documented breaking change, expect identical seed plus identical prompt to render a different image. The Wiki tells you which versions broke which path.
- If you change resolution to fit a new aspect ratio — even by a single pixel — expect a structurally different image. The seed initializes noise inside the latent shape, not outside it.
- If you migrate a prompt library from SD 1.5 or SDXL to FLUX.2, expect every negative-prompt incantation to silently do nothing. The conditioning input no longer exists.
- If you A/B-test prompts across GPT Image 2, Flux, and Stable Diffusion, expect that you are not measuring “prompt quality” — you are measuring how each text encoder maps your sentence into its own latent geometry. The comparisons rarely transfer.
This is also where LoRA for Image Generation and AI Image Editing pipelines hit the same wall: a LoRA trained against one base model’s text encoder produces different — usually worse — conditioning when stapled to a different base, even when the file format technically loads. Downstream tools like Image Upscaling and AI Background Removal inherit whatever instability lives upstream; they cannot rescue a render whose latent has already drifted.
Rule of thumb: Treat your prompt library as code that depends on three pinned versions — the model, the tool, and the GPU class. If any of those three change, the library is not portable; it is a starting point.
When it breaks: Across model versions and across architectures, identical seeds and identical syntax do not preserve identical outputs. Reproducibility is a within-version, within-hardware property at best — and often only inside a single session of a single Generator object.
The Data Says
Image prompt syntax was reverse-engineered from web UIs, not specified by model architects — so it parses one way in Diffusers, another way in Auto1111, another in Midjourney, and not at all in FLUX.2 or GPT Image 2. Seed reproducibility is bounded by the same surfaces: tool version, hardware RNG, output resolution, scheduler implementation. The most useful mental model is that a prompt is not a sentence — it is a configuration tuple, and one of those configurations changes more often than people realize.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors