Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
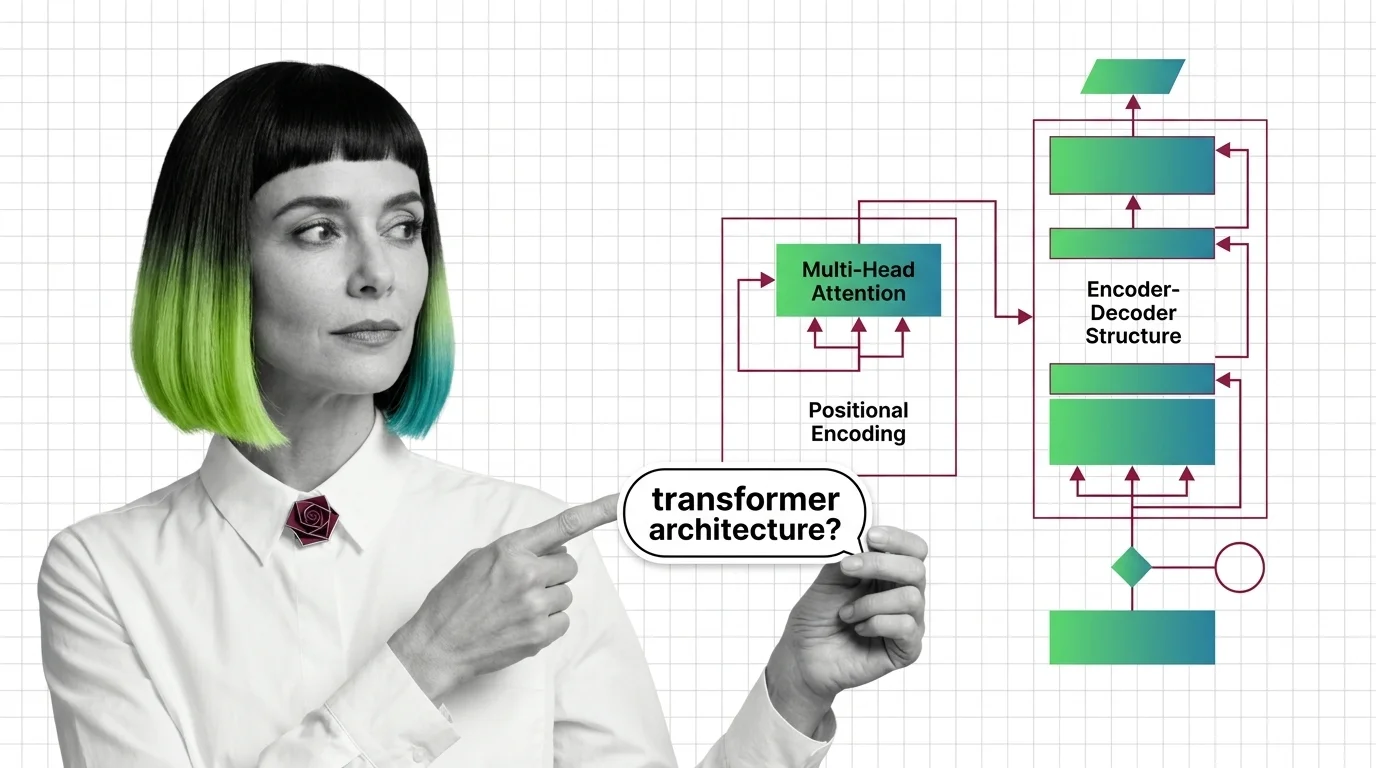
Table of Contents
ELI5
Transformers read all words at once using multi-head attention to find relationships, positional encoding to remember word order, and an encoder-decoder structure to convert input into output.
Here is a strange fact about the most consequential architecture in modern AI: it has no memory. The Transformer Architecture processes every token simultaneously—no left-to-right scanning, no recurrence, no sequential state. Yet it translates between languages, generates coherent paragraphs, and resolves pronouns across thousand-token spans. Something is preserving order without sequence. Something is enabling focus without search. The machinery that pulls this off is less intuitive than you expect, and more geometrically elegant than it has any right to be.
The Geometry of Selective Focus
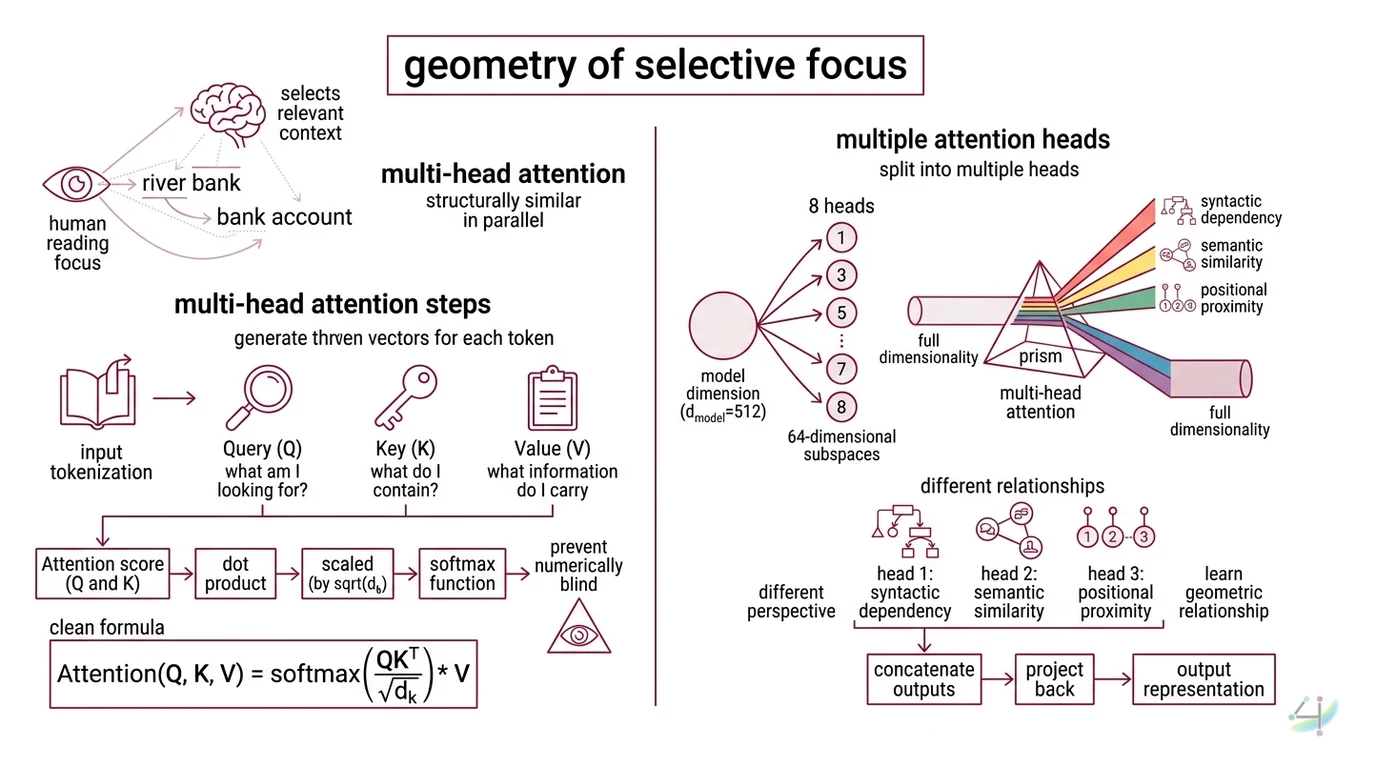
When you read a sentence, your eyes don’t weigh every word equally. The word “bank” in “river bank” pulls different context than “bank” in “bank account.” Your brain selects relevant context on the fly.
Multi Head Attention does something structurally similar—but in vector space, and in parallel.
How does multi-head attention work in transformers?
Every input token—the output of Tokenization, which splits text into discrete numerical units—gets transformed into three vectors: a Query, a Key, and a Value. Think of Query as “what am I looking for?”, Key as “what do I contain?”, and Value as “what information do I carry.” The attention score between two tokens is the dot product of the Query of one and the Key of the other, scaled by the square root of the key dimension.
The formula is clean: Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) * V (Vaswani et al.).
That scaling factor—dividing by sqrt(d_k)—isn’t decorative. Without it, dot products grow large in high-dimensional space, pushing the softmax function into regions where its gradients vanish. The division prevents the model from going numerically blind.
But here is where it gets interesting. A single attention function has one perspective. It can track subject-verb agreement or co-reference, but not both simultaneously. The solution: split the representation into multiple independent heads.
In the original transformer, the model dimension (d_model = 512) is divided across 8 heads, each operating on 64-dimensional subspaces (Vaswani et al.). Each head learns a different geometric relationship. One head might track syntactic dependency. Another might lock onto semantic similarity. A third might follow positional proximity. After attending independently, the outputs are concatenated and projected back into the full dimensionality.
Not a committee. A prism—splitting light into its spectral components, then recombining them.
The Feedforward Network that follows each attention block (a two-layer network with inner dimension d_ff = 2048 in the base model) processes each position independently—a deliberate architectural constraint. Attention handles relationships between tokens; the feedforward layer handles the transformation of each token’s representation in isolation. Division of labor, encoded in the architecture itself.
Why Transformers Remember What Comes First
Strip away Positional Encoding and the transformer sees a bag of tokens. “The cat sat on the mat” becomes indistinguishable from “mat the on sat cat the.” Every permutation produces identical attention patterns, because the attention mechanism is permutation-equivariant by design.
That is not a bug. It is the consequence of processing everything in parallel.
How does positional encoding represent word order in transformers?
The original transformer injects position information by adding a unique vector to each token’s Embedding before it enters the attention layers. These vectors follow a sinusoidal pattern: PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) and PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model)), where pos is the token position and i is the dimension index (Vaswani et al.).
Why sine and cosine? Because for any fixed offset k, PE(pos + k) can be expressed as a linear function of PE(pos). The model can learn to attend to relative positions without ever being taught relative position explicitly. The geometry encodes the relationship.
Each dimension oscillates at a different frequency—low dimensions cycle slowly across the sequence, high dimensions cycle rapidly. Position 1 and position 100 differ in specific, learnable ways across all dimensions simultaneously. The encoding is a unique fingerprint for every position, computable for any sequence length the model has not seen during training.
Modern architectures have moved beyond this approach. Rotary Positional Encoding (RoPE), used in most current transformers including the LLaMA family, encodes position by rotating the Query and Key vectors in 2D subspaces before computing attention (HF Blog). The rotation angle depends on position, so relative distance between two tokens is captured in the angle between their rotated vectors. RoPE handles longer sequences more gracefully and has become the standard in production-scale models.
The principle remains the same: position is geometry, and geometry is learnable.
Two Architectures, One Lineage
The original 2017 paper described a paired system: an encoder that reads, and a decoder that writes. Most developers encounter only one half at a time—GPT is decoder-only, BERT is encoder-only—and lose sight of why the split existed in the first place.
What is the difference between encoder and decoder in transformer architecture?
The encoder processes the entire input sequence with bidirectional attention—every token can attend to every other token, forwards and backwards. This produces a rich contextual representation where “bank” near “river” and “bank” near “account” yield different vectors. The original transformer stacks 6 encoder layers, each containing multi-head attention followed by a feedforward network (Vaswani et al.).
The decoder generates output one token at a time using causal (masked) attention—each token can only attend to previous tokens and itself. It cannot look ahead. This constraint is non-negotiable for generation tasks; allowing the model to see future tokens during training would create information leakage, and the model would learn to cheat rather than to predict.
In the full encoder-decoder architecture, the decoder includes a second attention layer—cross-attention—that attends to the encoder’s output. This is the bridge. The encoder compresses “Le chat est sur le tapis” into a geometric representation; the decoder’s cross-attention queries that representation while generating “The cat is on the mat.”
Each architectural variant optimizes for different information flow (HF Course):
| Variant | Attention Type | Models | Strength |
|---|---|---|---|
| Encoder-only | Bidirectional | BERT, ModernBERT | Classification, NER, search |
| Decoder-only | Causal (left-to-right) | GPT, LLaMA, Gemma, DeepSeek-V3 | Text generation |
| Encoder-decoder | Bidirectional + Causal + Cross | T5, BART, Marian | Translation, summarization |
The decoder-only architecture dominates current large-scale models because it scales more efficiently for generation—the primary use case driving investment. But encoder-decoder models persist where the task explicitly requires compressing one modality and expanding into another.
Not superiority. Task geometry.
What the Architecture Predicts—and Where It Fractures
If you understand these three mechanisms, you can predict failure modes before they appear.
If your model ignores word order in tasks where it matters—scrambled instructions, misordered reasoning steps—the positional encoding is losing signal. This happens predictably with sequences far longer than the training distribution. RoPE mitigates it; it does not eliminate it.
If your model generates plausible but factually contradictory text across long passages, attention heads are failing to maintain long-range coherence. The quadratic cost of self-attention (O(n^2) in sequence length) means that as context grows, the model allocates attention more thinly. Some relationships fall below the threshold of influence.
If Fine Tuning on translation fails to match encoder-decoder quality using a decoder-only model, you are fighting the architecture. Decoder-only models can learn translation, but they lack the dedicated cross-attention bridge that encoder-decoder architectures provide. The architecture encodes an inductive bias about information flow.
Rule of thumb: Match the attention pattern to the task. Bidirectional for understanding, causal for generation, cross-attention for transduction.
When it breaks: Quadratic attention scaling means doubling sequence length quadruples memory and compute. State Space Model architectures like Mamba offer linear-time alternatives and, as of early 2026, show competitive results on certain benchmarks—though their effectiveness on tasks requiring precise long-range token relationships remains an active research question.
Compatibility note:
- Hugging Face Transformers v5: TensorFlow and JAX support has been removed. The library is now PyTorch-only with a Python 3.10+ minimum requirement (HF Transformers). Plan migrations accordingly.
The Data Says
The transformer’s power comes from three interlocking mechanisms: attention that selects relevant context in parallel, positional encoding that injects order into an orderless computation, and an encoder-decoder split that separates comprehension from generation. These components have survived eight years of scaling largely unchanged—not because they are perfect, but because their geometric properties compose well. The architecture that replaced recurrence did not eliminate sequence processing. It replaced time with space.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors