Model Collapse, Fidelity Gaps, and Re-Identification: The Technical Limits of Synthetic Data
ELI5
Synthetic data is artificially generated to mimic real data. It has three hard limits: models trained on their own output decay (model collapse), realism trades off against privacy, and rare records can still be re-identified.
Train a generator on real data and it learns to produce convincing fakes — convincing enough to pass the statistical tests you throw at it. Train the next generation on those fakes, then the one after that on the generation before, and something quiet happens: the model stops representing rare events. Nobody deletes the outliers. The model simply samples them less often, generation after generation, until the tails of the distribution flatten into noise.
That decay has a name, and it is the first of three places where Synthetic Data Generation runs into a wall the marketing rarely mentions. The pitch is seductive: data that is fake, so it carries no privacy risk, and generated, so you can make an infinite supply. Both halves of that sentence are wrong, and the math explains why.
When a Model Eats Its Own Output
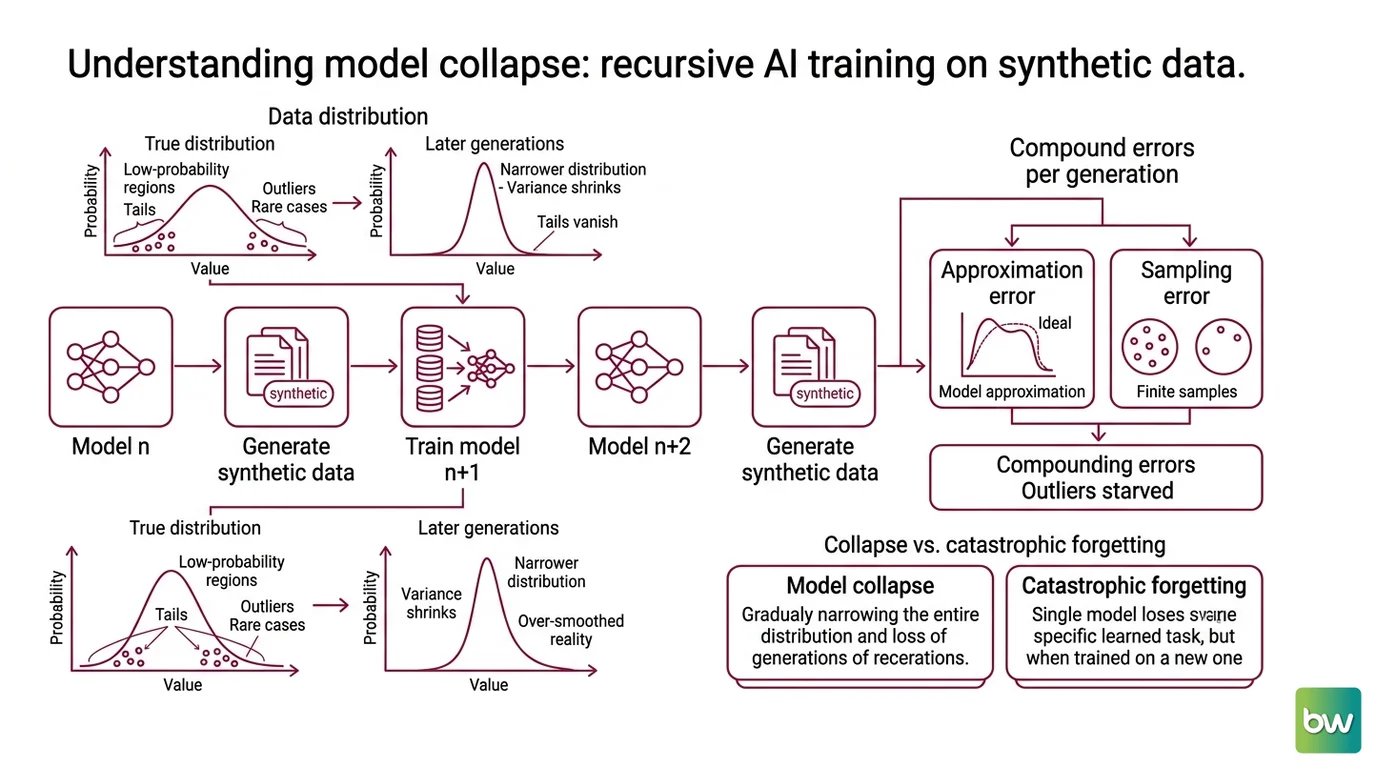
Make a photocopy of a photocopy of a photocopy. Each pass looks fine on its own, but stack twenty of them and the fine lines are gone, the contrast has collapsed, and the page drifts toward a gray average. Recursive training on generated data does the same thing to a probability distribution — and the casualties are the edges first.
What is model collapse from training AI on synthetic data?
Model collapse is the degenerative process in which a model trained on data produced by earlier models progressively loses the low-probability regions of the original distribution. The seminal demonstration appeared in Nature, where recursive training across language models, variational autoencoders, and Gaussian mixture models all showed the same pattern: the tails vanish first, the variance shrinks, and later generations converge toward a narrow, over-smoothed version of reality (Nature). The same research team had raised the alarm a year earlier, framing recursive training as a trap in which models gradually forget their own rare cases.
The mechanism is statistical, not mystical. Every generative model is an approximation of the true distribution, and every sample it draws is finite. Finite sampling under-represents low-probability events by construction — a rare category that shows up in only a handful of real records may not appear at all in a synthetic batch. Train the next model on that batch and the rare category is now genuinely absent from its world. Each generation compounds two errors: the approximation error baked into the model and the sampling error of drawing a finite set. Stack them across generations and the distribution narrows toward its own mean.
Not deletion. Starvation. The outliers are not removed by any step; they are simply never fed forward, so the model that learns from the previous model’s output never tastes them.
One distinction matters here, because the vocabulary collides. Model collapse happens across generations of recursive training. Mode Collapse is a different failure that happens within a single Generative Adversarial Network, where the generator learns to produce only a few output types to fool the discriminator. Same word, different scale, different cause — and confusing them leads to the wrong fix.
The Realism You Can’t Afford
A generator can be tuned to maximize how closely its output matches the real data, or to maximize how little it reveals about any individual in that data. It cannot freely maximize both, and the gap between them is where most synthetic-data projects quietly fail. This is a three-way tension between fidelity, privacy, and downstream utility — push hard on any corner and at least one of the others gives.
What are the fidelity and validity tradeoffs of synthetic data?
Fidelity measures how well synthetic data reproduces the statistical structure of the original — its distributions, and crucially the correlations between columns. Validity asks a stricter question: does the synthetic record obey the real-world constraints the data must satisfy? High marginal fidelity with broken joint structure is a common and dangerous combination. Each column can look perfectly realistic on its own while the relationships between them — the correlations a downstream model actually learns from — quietly fall apart.
The privacy lever makes the tradeoff concrete. Differential Privacy bounds how much any single individual can influence the output, controlled by a privacy budget written as epsilon. Lower epsilon means stronger privacy, which means more injected noise, which means lower statistical fidelity and weaker downstream model accuracy; training a generator under such a budget systematically disrupts the correlation structure between variables (Patterns). The magnitude of that loss is not a fixed percentage — it depends heavily on the dataset and the epsilon you choose — so treat any vendor’s single fidelity number with suspicion.
It helps to separate two things often sold under one banner. Faker produces format-realistic but statistically meaningless values — plausible names, addresses, and IDs with no relationship to any real distribution (Faker Docs). That is useful for filling a test database, and useless for training a model that needs to learn real correlations. Distribution-faithful generators are a different animal: CTGAN, a conditional GAN for tabular data introduced at NeurIPS 2019 and maintained inside the open-source Synthetic Data Vault, tries to preserve the joint structure (SDV’s CTGAN repo). The commercial tooling around this has been consolidating — Gretel is now part of NVIDIA after a reported 2025 acquisition (TechCrunch), and MOSTLY AI now operates as MOSTLY AI, powered by Syntho (Syntho) — but the underlying constraint binds every tool regardless of who owns it.
The Records That Stay Findable
The most common defense of synthetic data is that it breaks the link to real people: no real row survives, so no real person is exposed. That intuition holds for the average record and fails precisely where it matters. A generator that learns the distribution well enough to be useful has, by definition, learned something about the individuals who shaped its rarest regions.
Can synthetic data leak private information from the real dataset?
Yes — and the leak concentrates on outliers. The most rigorous study of this, presented at USENIX Security, framed it as an anonymization “groundhog day”: synthetic data generators either fail to prevent inference attacks or they protect privacy only by destroying the statistical utility that justified using them in the first place; records that are outliers in the real data remain identifiable in the synthetic output, and several differential-privacy implementations were found to violate their own stated guarantees (USENIX Security 2022). The attack that exposes this is membership inference — asking, of a given real record, whether it was part of the training set. For a typical record buried in a dense cluster, the answer is noisy. For an outlier with a unique combination of attributes, the synthetic distribution still bends around where that record used to be, and the answer becomes readable.
The records hardest to model are the records hardest to hide. A patient with a rare combination of conditions, a household that is the only one of its kind in a region — these are simultaneously the points a faithful generator must represent and the points whose presence is easiest to detect. Memorization is the extreme case: a generator that has overfit can reproduce near-copies of training rows outright, but you do not need full memorization for a leak. A statistical lean toward an outlier’s neighborhood is enough.
Not anonymous. Just rearranged. Synthetic generation moves the information around; it does not automatically destroy it.
What the Three Limits Predict
The value of understanding the mechanism is that it turns into predictions you can act on before the failure shows up. Read these as if/then statements about your own pipeline.
- If you retrain a generator mostly on its own previous outputs, expect the rare categories to disappear first — minority classes, edge cases, long-tail events — while the bulk of the distribution still looks healthy.
- If you tighten the privacy budget by lowering epsilon, expect the correlations between columns to weaken and any downstream model’s accuracy to drop, even when each column’s individual distribution still looks correct.
- If your dataset contains genuine outliers, expect them to stay the most exposed to membership-inference attacks after synthesis — the same uniqueness that makes them hard to model makes them easy to detect.
Notice the through-line: all three failures live at the tail. The center of the distribution — the common, well-represented cases — survives recursive training, tolerates noise, and hides easily in a crowd. The edges do none of those things.
Rule of thumb: treat synthetic data as a lossy compression of the real distribution — it preserves the bulk and sacrifices the edges.
When it breaks: synthetic data fails hardest exactly where you need it most — on rare events and outliers. The same records that are too sparse to model faithfully are also the ones most exposed to re-identification, so fidelity and privacy degrade together at the tail rather than trading off cleanly.
Why Synthetic Data Isn’t Doomed
The picture above is a description of naive recursive training, not a death sentence — and the distinction is the whole game. The Nature result drew a strong reaction, and follow-up work, along with a later correction to the original paper, clarified that collapse is avoidable when synthetic data accumulates alongside real data rather than replacing it. Keep a fixed anchor of real records in every training round and the distribution has something to hold its tails against.
Knowledge Distillation is the controlled cousin that proves the point. A student model trained on a teacher’s generated outputs works well precisely because the teacher stays fixed — there is no recursive loop of a model learning from its own degrading copies. The dividing line between productive synthetic data and collapse is not whether the data is generated. It is whether the real signal stays in the loop.
The Data Says
Synthetic data is a lossy model of reality, not a free copy of it, and its limits cluster at the tail: recursive training erases rare events, stronger privacy erodes fidelity, and outliers stay re-identifiable. The center holds; the edges do not. Use it to augment real data, not to replace it — the moment the real signal leaves the loop, the math turns against you.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors