Mode Collapse, Training Instability, and the Hard Technical Limits of Generative Adversarial Networks
Table of Contents
ELI5
A generative adversarial network trains two neural networks against each other — one generates, one critiques. The competition produces realistic outputs but suffers from structural failures that no engineering fix has fully eliminated.
In 2014, Ian Goodfellow published a proof that two Neural Network Basics for LLMs, locked in a minimax game, would converge to an equilibrium where the generator perfectly recovers the training data distribution. The math was clean. The experiments were promising. And then practitioners started training GANs on real datasets — and discovered that the elegant theory described a world that finite networks could not reach.
The Helvetica Scenario: When a Generator Forgets the Distribution
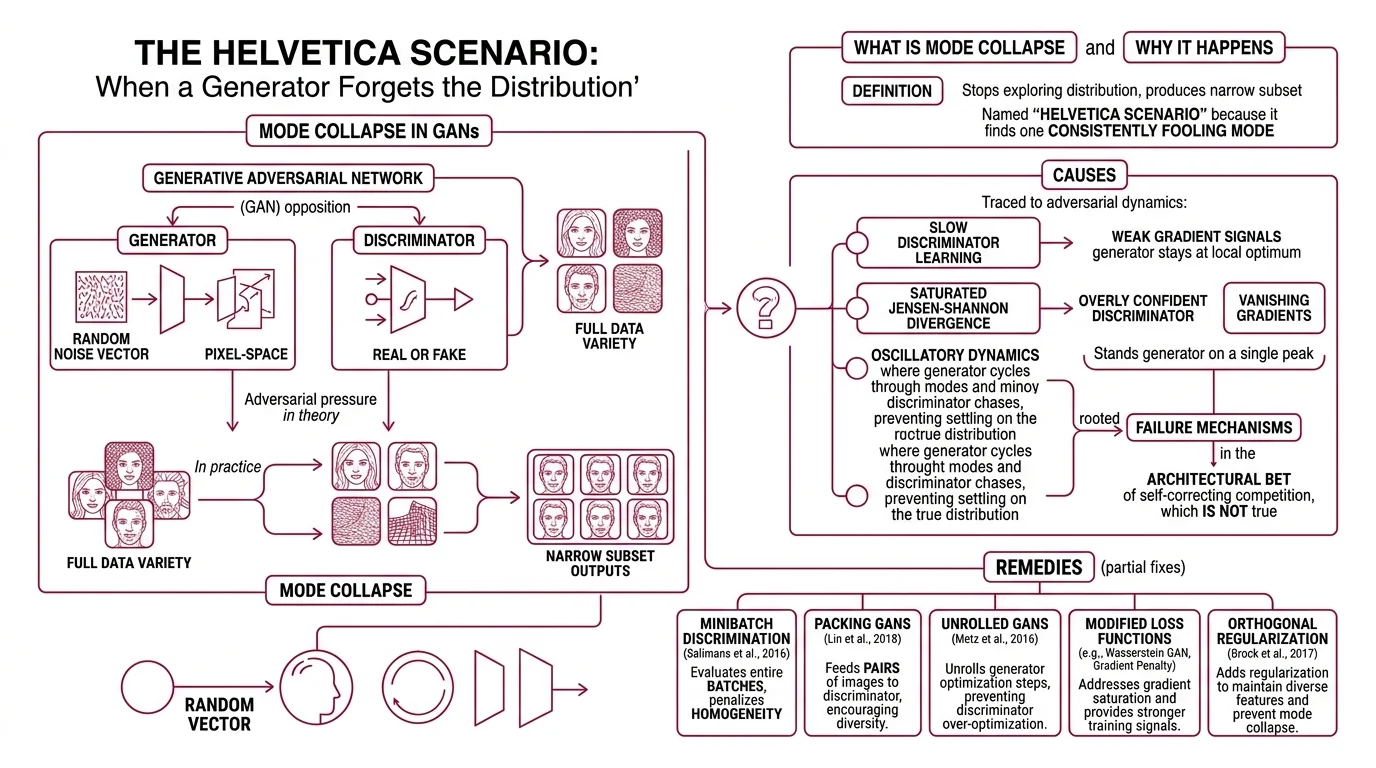
A Generative Adversarial Network works by opposition. The generator — typically built on Convolutional Neural Network layers — maps random noise vectors to pixel-space outputs. The discriminator classifies those outputs as real or fake. In theory, adversarial pressure pushes the generator toward the full variety of faces, textures, objects, and structures contained in the training data.
In practice, the generator finds a shortcut.
What is mode collapse in GANs and why does it happen?
Mode Collapse occurs when the generator stops exploring the data distribution and collapses to producing only a narrow subset of outputs — the same face with minor variations, the same texture rotated slightly, the same structure at every scale. Goodfellow named this failure the “Helvetica scenario” in the original GAN paper (Goodfellow et al.): the generator discovers one mode that consistently fools the discriminator and never leaves it.
The causes trace directly to the adversarial dynamics themselves. When the discriminator learns slowly relative to the generator, gradient signals become too weak to push the generator past its local optimum. The Jensen-Shannon divergence that underlies the original loss function saturates when the discriminator grows overly confident, producing vanishing gradients that strand the generator on a single peak in output space. And oscillatory dynamics — where the generator cycles through modes while the discriminator chases — prevent either network from settling on the true distribution.
Three distinct failure mechanisms, all rooted in the same architectural bet: that competition between two networks would be self-correcting.
It is not.
The remedies read like a catalogue of partial fixes. Minibatch discrimination (Salimans et al., 2016) evaluates entire batches rather than individual samples, penalizing homogeneity across the generator’s outputs. Unrolled GANs (Metz et al., 2016) optimize the generator against projected future states of the discriminator, looking several training steps ahead rather than reacting to the current one. Both improve stability in specific settings; neither eliminates mode collapse as a structural tendency of adversarial training. The failure is not a bug in any particular implementation — it is a property of the formulation.
Chasing an Equilibrium That May Not Exist in Practice
If mode collapse is the generator’s failure, training instability is the system’s failure. The two are related but not identical — a GAN can be unstable without collapsing, oscillating indefinitely between configurations that never converge. Understanding why requires looking at the gap between the theoretical proof and the landscape where actual optimization happens.
Why is GAN training unstable and hard to converge?
The original GAN proof establishes that a unique equilibrium exists: the generator recovers the training data distribution while the discriminator outputs 1/2 everywhere, unable to distinguish real from synthetic (Goodfellow et al.). But that proof assumes networks with arbitrary capacity — infinite parameters, perfect optimization, unlimited training time.
Finite-capacity networks operate under different constraints.
GAN training performs a minimax optimization: the generator minimizes what the discriminator maximizes. In continuous, unconstrained function spaces, this has a well-defined solution. In the parameter space of actual neural networks, it produces saddle points, limit cycles, and divergent trajectories. The dynamics resemble two players adjusting strategies simultaneously in a game where each update reshapes the loss surface the other network is optimizing against — a moving target chasing a moving target.
The Wasserstein GAN offered a structural response by replacing the Jensen-Shannon divergence with the Earth Mover distance, providing gradients that remain informative even when the discriminator reaches optimality (Arjovsky et al.). This was a genuine advance. But neither WGAN nor WGAN-GP nor DRAGAN converges reliably on simple examples when the number of discriminator updates per generator step is fixed — a finding that reframes the convergence problem as deeper than any single loss function can address (Mescheder et al.).
What does converge locally? Instance noise and zero-centered gradient penalties (Mescheder et al.). These techniques stabilize training not by changing the adversarial game but by smoothing the loss surface — adding friction to a system that would otherwise oscillate without bound.
The pattern is telling. Every successful stabilization technique works by constraining the adversarial dynamics; by making the game less adversarial. The architecture’s defining principle — competition as a training signal — is simultaneously its source of expressive power and its fundamental ceiling.
Speed Against Diversity: The Architectural Fork in Generative AI
The structural failures of GAN training did not unfold in isolation. They occurred alongside the rise of diffusion models — an alternative paradigm that made a fundamentally different set of trade-offs. Comparing the two architectures reveals what each one actually optimizes for, and what it gives up.
How do GANs compare to diffusion models in image quality and inference speed?
Unlike Recurrent Neural Network architectures that generate outputs token by token, a GAN produces its entire image in a single forward pass through the generator. Inference at this speed — milliseconds per image — makes GANs viable for real-time applications: super-resolution in gaming, augmented reality filters, live video enhancement. Real-ESRGAN, a practical super-resolution GAN still active as a research baseline as of 2025, demonstrates exactly this: fast, high-quality upscaling in a single pass without iterative refinement.
Diffusion models take a fundamentally different path. Starting from pure noise, they iteratively denoise across twenty to a thousand steps, each pass refining the image toward the target distribution (Sapien). The result — as of 2025 — is higher sample diversity and better perceived quality across most evaluation criteria. But the cost is latency: where a GAN generates in one pass, a diffusion model needs orders of magnitude more computation per sample.
The tension has a formal characterization. High quality, mode coverage, and fast sampling cannot all be maximized by a single architecture — a constraint described as the generative learning trilemma (NVIDIA Blog). GANs historically chose speed and quality while sacrificing diversity — and mode collapse is precisely that sacrifice made visible. Diffusion models chose quality and diversity while accepting slow sampling. Neither architecture escapes the trilemma; they occupy different vertices of the same constraint space.
Not a contest. A partition of the possible.
As of 2025, diffusion architectures dominate mainstream image generation — Stable Diffusion, DALL-E 3, Midjourney all run on diffusion-based pipelines. GANs retain relevance where latency is the binding constraint: real-time super-resolution, AR/VR pipelines, and specialized domains where Stylegan variants still produce high-fidelity outputs for constrained distributions like face synthesis — though StyleGAN3, released by NVIDIA in 2021, has not seen a major successor, and NVIDIA’s own research focus has shifted toward diffusion approaches. Hybrid architectures combining GAN-speed generators with diffusion-quality training signals represent an emerging research direction, though no established solution has yet resolved the trilemma.
What the Failure Modes Predict
The structural limits of GANs are not just historical curiosities — they generate testable predictions about when GAN-based systems will succeed and when they will break.
If your task requires generating diverse outputs across a broad distribution — many styles, many subjects, many compositions — expect mode collapse to surface regardless of the stabilization technique applied. The adversarial formulation rewards fooling the discriminator, not covering the distribution. If your application tolerates narrow output variety (face generation from a constrained dataset, texture synthesis, single-domain super-resolution), GANs remain competitive on both speed and output quality.
If training stability matters — if you cannot afford to babysit hyperparameters through hundreds of failed runs — diffusion models offer a more predictable optimization trajectory. GAN training requires expertise that diffusion training simply does not; the sensitivity to learning rates, discriminator-generator update ratios, and architecture choices is not incidental but inherent to the minimax formulation.
If real-time generation is the binding constraint — gaming, live video, AR overlays — GANs still outperform on inference latency by an order of magnitude.
When it breaks: GAN-based systems fail most reliably when asked to generate high diversity across complex, multi-modal distributions — precisely the scenario where mode collapse is hardest to suppress and where diffusion models hold the clearest advantage.
The Data Says
The hard limits of adversarial training are not engineering problems waiting for better hyperparameters. They are structural consequences of the minimax formulation — the gap between the theoretical equilibrium in infinite-capacity function spaces and the finite networks that must approximate it. Mode collapse, training instability, and the generative trilemma are three faces of the same constraint. Understanding them does not make GANs obsolete; it makes the choice between generative architectures a decision grounded in physics rather than fashion.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors