MMLU's 6.5% Label Error Rate, Score Saturation, and the Prerequisites for Understanding LLM Benchmarks

Table of Contents
ELI5
The MMLU Benchmark tests language models on 15,908 multiple-choice questions across 57 subjects — but roughly 1 in 15 answer labels is wrong, and top models now score so similarly the benchmark cannot separate them.
Imagine grading a medical exam and discovering that the answer key marked the wrong choice for more than half the virology questions. Not a thought experiment — that is a published finding about the most widely cited language model evaluation in the field. The benchmark everyone references has a measurement floor that is noisier than the differences it claims to detect, and the models it was designed to rank have all arrived at the same ceiling. What follows is the anatomy of that problem, the math that explains it, and the successor that attempts to fix it.
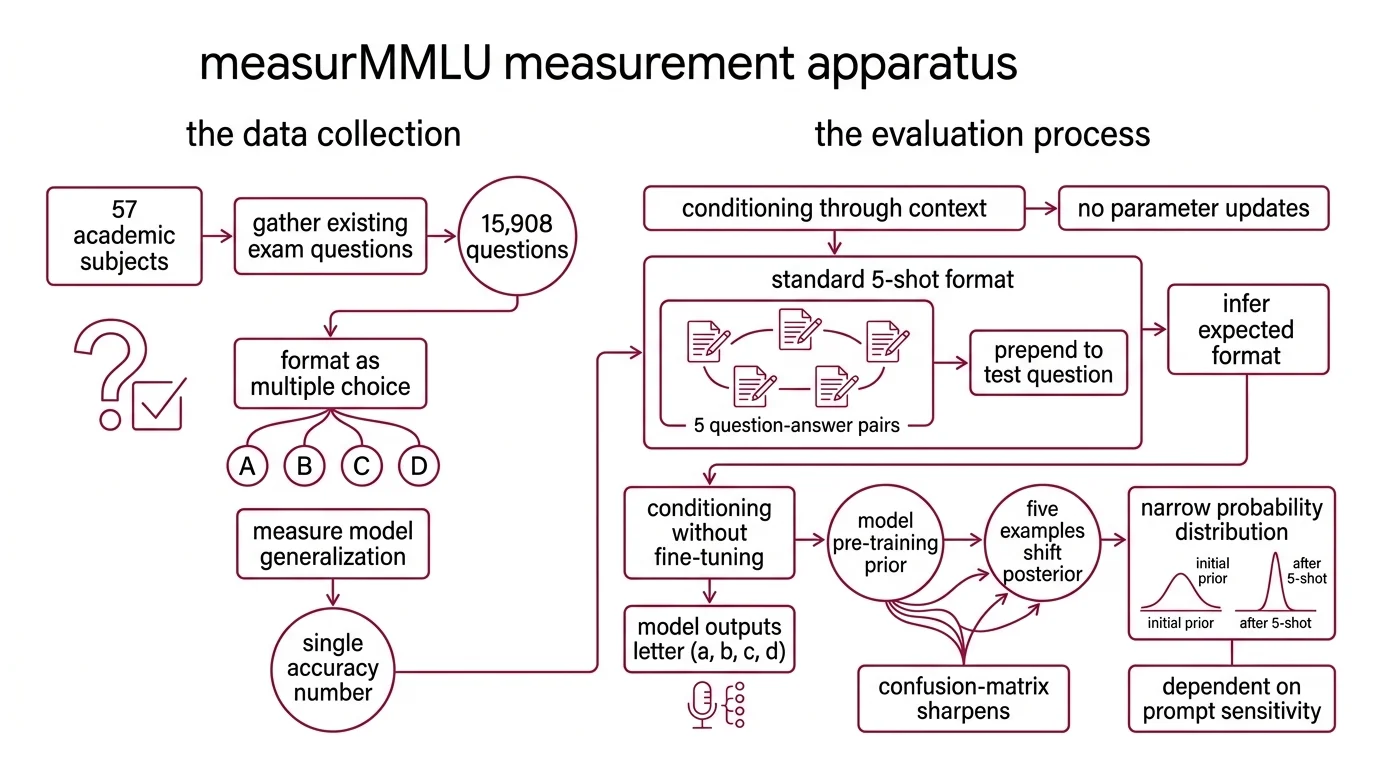
The Measurement Apparatus — 15,908 Questions and a Borrowed Exam Format
MMLU — Massive Multitask Language Understanding — arrived in September 2020 and was published at ICLR 2021 (Hendrycks et al.). The premise was deceptively straightforward: gather existing exam questions across 57 academic and professional subjects, from abstract algebra to world religions, format them as four-option multiple choice, and measure how well a model generalizes across all of them. 15,908 questions. One correct answer each. A single accuracy number as the output.
The breadth was the innovation. The fragility hid in the details — specifically, in how models encounter those questions and in what the answer key assumes.
What is few-shot evaluation and how does MMLU use it to test language models
Few-Shot Learning evaluation gives a model a handful of worked examples before posing a new problem — no parameter updates, no fine-tuning, just conditioning through context.
MMLU uses a standard 5-shot format: five question-and-answer pairs from the same subject are prepended to the test question, and the model outputs a single letter — A, B, C, or D (Hendrycks et al.). The model never trains on those demonstrations; it uses them to infer the expected format and domain-appropriate reasoning patterns.
Think of it as Bayesian inference without weight updates. The prior is everything the model absorbed during pre-training — billions of tokens of distributional knowledge. The five examples shift the posterior, narrowing the probability distribution over possible answer formats. When the examples are well-chosen, the model’s Confusion Matrix sharpens around correct answers. When they are ambiguous, the model follows the wrong statistical gravity.
The 5-shot format was not arbitrary. It balanced performance gains against the context window constraints of 2020-era models. But it introduced a dependency that would haunt the benchmark: prompt sensitivity of 4-5 percentage points. Reorder the five examples, rephrase a stem, swap one demonstration — and the same model’s score shifts by more than the gap between competing frontier systems.
That alone should give pause. But it was not the worst problem.
When the Answer Key Itself Is Wrong
A benchmark is only as reliable as its ground truth labels. MMLU inherited its questions from existing exams — standardized tests, practice problems, textbook exercises. No published audit checked all 15,908 labels for correctness before release.
In 2024, a team of researchers finally ran that audit on a substantial subset, and what they found reframed every MMLU score ever reported.
How many errors are in the MMLU benchmark ground truth answer labels
Gema et al. manually re-annotated 5,700 questions across all 57 subjects and estimated that 6.49% of MMLU questions contain errors. The error taxonomy breaks into three categories: incorrect answer labels account for 33% of the errors, unclear or ambiguous questions for 14%, and questions with multiple defensible answers among A through D for 4% (Gema et al.).
Those percentages sound contained until you look at the subject-level distribution. In virology, 57% of the analysed questions were flagged as erroneous (Gema et al.).
Not a rounding issue. A structural defect.
The implication is straightforward but uncomfortable. If you compare two models and one scores three points higher in a subject where a quarter of the answer labels are wrong, you are not measuring capability. You are measuring which model happens to agree with the mistakes. Model Evaluation under those conditions tests coincidence, not intelligence.
The corrected subset — MMLU-Redux, those 5,700 re-annotated questions — now exists as a reference. But the original 15,908-question benchmark, errors included, remains the version most leaderboards report. The scoreboard everyone reads is still graded against an answer key that nobody fully trusts.
From Four Choices to Ten — and Why That Changes the Signal
MMLU’s multiple-choice design inherited the constraints of standardized testing circa 2020. Four options. Letter output. A format simple enough that models could sometimes score well through elimination or shallow pattern matching rather than multi-step reasoning. The question was whether a harder format would separate genuine understanding from surface-level retrieval.
What is the difference between MMLU and MMLU-Pro benchmarks
MMLU Pro rewrites the evaluation contract. Published by Wang et al. and accepted at NeurIPS 2024, it expands the answer set from 4 options to 10 across 12,000+ questions in 14 disciplines. The random-guessing baseline drops from 25% to 10%, which means every correct answer carries substantially more signal.
The results confirmed the design worked. The same models that scored in the high 80s on MMLU dropped 16-33 percentage points on MMLU-Pro (Wang et al.). That gap is not noise — it is the distance between a test where shallow retrieval earns partial credit and one where it does not.
Two additional properties matter for engineers who design evaluation pipelines using Precision, Recall, and F1 Score metrics. First, chain-of-thought reasoning improves performance on MMLU-Pro but shows no benefit on the original MMLU (Wang et al.) — evidence that the original benchmark’s questions were largely answerable without multi-step reasoning. Second, prompt sensitivity dropped from 4-5% variance to 2%, making MMLU-Pro scores more reproducible across evaluation setups.
The question of Benchmark Contamination received a separate treatment. Microsoft Research released MMLU-CF, a contamination-free variant with 10,000 closed-source test questions and 10,000 open-source validation items. When tested on MMLU-CF, GPT-4o dropped from 88.0% on standard MMLU to 73.4% in the 5-shot setting (Microsoft Research).
Not generalization. Memorization — at least for that 14.6-point gap.
A separate meta-analysis estimated a 13.8% overall contamination rate across major LLM benchmarks, rising to 18.1% in STEM and reaching 66.7% in philosophy; contaminated models showed an average 7.0 percentage point accuracy advantage over rewording-tested baselines (LXT Research). The methodology and scope differ from MMLU-CF’s direct testing approach, but the direction is consistent: benchmark scores partly reflect memorization, not capability.
When 90% Stops Meaning Anything
Score saturation is not a theoretical concern. It is a measurement wall that the field has already hit, and understanding where it comes from determines whether you can trust any MMLU-derived comparison in a model selection decision.
Why are MMLU scores no longer meaningful for distinguishing top AI models in 2026
As of April 2026, the MMLU leaderboard shows GLM 5 Thinking at 91.7%, DeepSeek R1 0528 at 90.5%, Grok 3 Mini Beta at 89.2%, and o3 Mini at 88.9% (PricePerToken). Four frontier models within 2.8 points of each other — a spread that falls inside the benchmark’s own prompt sensitivity range. Scores vary further depending on the evaluation harness used; results from HuggingFace, HELM, and custom implementations are not perfectly comparable.
MMLU-Pro tells a different story. As of the same period, Gemini 3 Pro Preview leads at 89.8%, followed by Claude Opus 4.5 Thinking at 89.5%, Gemini 3 Flash Preview Thinking at 89.0%, and GPT-5.2 Pro at 87.4% (PricePerToken). The spread is wider, the ordering diverges from MMLU’s, and the scores carry more information because the underlying test is harder to game through memorization or elimination.
The saturation pattern is diagnostic. When a benchmark’s ceiling is bounded by its own label error rate and prompt sensitivity — both of which exceed the performance differences between top models — the benchmark has stopped measuring the thing it was designed to measure. It has become a filter for the middle of the distribution, not the frontier.
Rule of thumb: if two models fall within the range of MMLU’s known prompt sensitivity and error rate, the score difference is statistically indistinguishable. Use MMLU-Pro or domain-specific evaluations for meaningful comparisons at the frontier.
When it breaks: MMLU fails as a differentiator precisely when you need it most — at the top of the leaderboard. Models scoring above 88% are in the noise floor of the benchmark itself. For any high-stakes model selection, MMLU alone is insufficient; cross-reference with MMLU-Pro, contamination-controlled variants like MMLU-CF, and task-specific evaluations matched to your actual use case.
The Data Says
MMLU measured something real in 2021 — the gap between models that could generalize across academic domains and those that could not. That measurement reached its useful ceiling somewhere around 2024, when frontier models began clustering within the benchmark’s own error margin. The 6.49% label error rate, estimated from a 5,700-question re-annotation sample, means the answer key is noisier than the score differences it is supposed to adjudicate. MMLU-Pro — with ten options, lower prompt sensitivity, and chain-of-thought differentiation — is where meaningful model evaluation has moved.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors