Memory Walls, Quadratic Context Costs, and the Hard Engineering Limits of LLM Inference in 2026
Table of Contents
ELI5
LLM inference is bottlenecked by GPU memory and quadratic attention costs — every longer prompt multiplies the work. Engineers counter with caching tricks, compression, and speculative decoding, but the wall itself has not moved.
GPT-3-class Inference cost $60 per million tokens in 2021. By 2024, the same workload cost six cents — a thousand-fold collapse in three years (a16z). The natural conclusion is that the hard problem is solved, that inference is cheap now and will only get cheaper.
The math disagrees. Those gains came from engineering around a physical constraint, not from removing it. The constraint is memory, and it scales in a direction that no amount of cleverness fully reverses.
The Invisible Budget That Governs Every Token
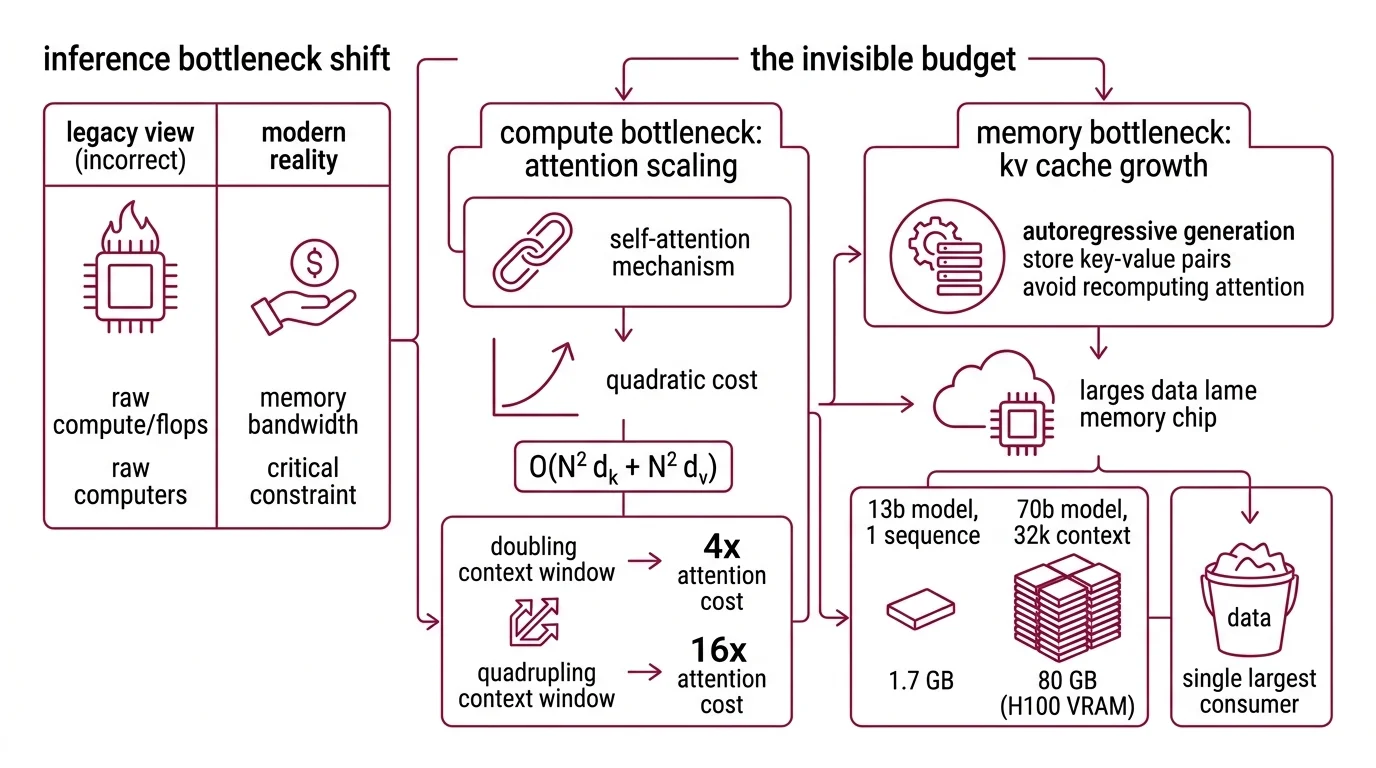
Most discussions of inference cost fixate on FLOPs — floating-point operations per second, the raw compute. This framing is almost exactly backwards for modern transformer inference. The dominant bottleneck, the one that determines whether a serving stack survives or starves, is not how fast the GPU can multiply. It is how fast data can move from memory to the arithmetic units that need it.
What are the memory and compute bottlenecks that limit LLM inference at scale?
The self-attention mechanism at the heart of every transformer requires each token in a sequence to attend to every other token. Compute scales as O(N² d_k + N² d_v) — quadratic in sequence length N (Vaswani et al.). Double the context window and attention alone costs four times as much. Quadruple it, and you are paying sixteen times the original price for the same architectural decision.
But the compute cost is not what kills production systems first. The KV cache does.
During autoregressive generation — the token-by-token process behind every chatbot response you have ever read — the model stores key-value pairs for every previously processed token so it does not recompute attention from scratch for each new token. An elegant optimization with an inelegant consequence: a single sequence on a 13-billion parameter model like LLaMA-13B can consume up to 1.7 GB of GPU memory just for its KV cache (vLLM Blog). Scale to a 70-billion parameter model at 32,000 tokens of context, and the cache demands roughly 80 GB — the entire VRAM capacity of an H100, consumed by one sequence’s history.
Now multiply by batch size. A production API serving hundreds of concurrent requests does not allocate one H100 per conversation. The KV cache becomes the single largest consumer of GPU memory, and before the recent wave of optimizations, most serving frameworks managed it with an approach best described as hopeful pre-allocation — reserving contiguous memory blocks for each sequence’s maximum possible length, whether the sequence used that length or not. The result: 60 to 80 percent of allocated KV cache memory sat unused, fragmented into gaps too small to reclaim.
Not a compute shortage. A memory management failure.
The bandwidth constraint compounds the damage. During the decoding phase, when the model generates tokens one at a time, the GPU spends most of its time fetching model weights and KV cache entries from high-bandwidth memory. The arithmetic intensity drops so low that the GPU’s tensor cores sit idle, waiting for data to arrive from memory they already requested. This is the memory-bandwidth bottleneck — the reason a GPU that computes twice as fast but reads memory at the same speed produces tokens at nearly the same rate. The bottleneck is the bus, not the processor.
Quadratic Costs and the Engineers Who Refuse to Pay Them
The O(N²) scaling of attention is a mathematical fact. But mathematical facts, in the hands of systems engineers, tend to become problems with approximate solutions — solutions that sacrifice theoretical elegance for practical survival. The last three years have produced an entire taxonomy of workarounds, each attacking a different face of the quadratic wall.
Why does inference cost grow quadratically with context length and what are the 2026 workarounds?
The quadratic cost has two faces. The compute face: attention requires N² dot products for a sequence of length N, and no architectural shortcut changes that arithmetic. The memory face: the KV cache grows linearly per layer, but total memory pressure scales with the product of batch size, layer count, and sequence length — all of it resident in GPU memory simultaneously. When context length grows, both faces squeeze harder, and the memory face usually bites first.
PagedAttention: virtual memory for the KV cache. vLLM introduced PagedAttention (Kwon et al., SOSP 2023), borrowing the operating system’s concept of paged virtual memory. Instead of pre-allocating contiguous blocks, the KV cache is stored in non-contiguous pages mapped through a page table — exactly the trick that solved memory fragmentation in operating systems decades ago. Memory waste drops from 60–80 percent to under 4 percent, and throughput climbs up to 24x compared to baseline serving (vLLM Blog). SGLang takes a related path with RadixAttention, reporting a 25x performance improvement on GB300 NVL72 hardware as of February 2026.
FlashAttention: tiling the attention matrix. FlashAttention does not reduce the asymptotic O(N²) compute; it restructures the computation to minimize memory traffic. By tiling the attention matrix into blocks and computing each block entirely in on-chip SRAM — fast, small, and close to the arithmetic units — rather than repeatedly shuttling intermediate results to and from HBM, FlashAttention-3 achieves up to 740 TFLOPs/s on H100 GPUs in FP16, roughly 75 percent hardware utilization (PyTorch Blog). FlashAttention-4, targeting NVIDIA’s Blackwell architecture, is in development; published details remain sparse as of early 2026.
KV cache Quantization and compression. Rather than storing full-precision key-value pairs, quantization reduces the bit-width of cached values, trading a controlled amount of precision for a large reduction in memory footprint. Google’s TurboQuant, announced March 24, 2026, claims 6x KV cache compression and 8x faster inference with no accuracy loss — though the code is not yet open-source, and no independent team has reproduced the results. NVIDIA’s KVTC reportedly achieves 20x compression with less than one percentage point of accuracy degradation, though this figure comes from secondary reporting and lacks primary NVIDIA verification.
Speculative decoding: trading parallelism for speed. Instead of generating one token at a time, a small, fast draft model proposes several candidate tokens, then the full model verifies them in a single parallel forward pass. The original technique (Leviathan, Kalman, Matias, 2022) demonstrated roughly 2–3x speedup while mathematically guaranteeing that the output distribution remains identical to standard autoregressive decoding (Google Research). TensorRT-LLM integrates EAGLE-3 speculative decoding alongside FP8/NVFP4 quantization in its current release.
Continuous Batching: filling every GPU cycle. Static batching waits for a full batch before processing, padding shorter sequences and wasting compute on empty tokens. Continuous batching inserts and removes individual sequences at the iteration level — no padding, no idle cycles. The approach achieves up to 23x throughput improvement and measurably reduces Time To First Token through iteration-level scheduling.
Purpose-built silicon. Groq’s LPU architecture takes a different approach entirely: replacing HBM with massive on-chip SRAM to eliminate the bandwidth wall at the hardware level. The Groq 3 LPU, unveiled at GTC in March 2026 following NVIDIA’s acquisition of Groq in December 2025, claims 150 TB/s SRAM bandwidth — roughly 7x the bandwidth of NVIDIA’s Rubin GPU (Tom’s Hardware). Production availability is expected Q3 2026; all published benchmarks remain manufacturer claims.
Compatibility notes:
- vLLM V0 engine: Deprecated mid-2026; V1 is now the default. Older tutorials and integrations referencing V0 APIs may break.
- TensorRT-LLM: PyTorch promoted to default backend; C++ TRTLLM sampler now default; several build CLI arguments removed in recent releases.
What the Memory Budget Predicts
If you are choosing an inference stack in 2026, the decision tree reduces to one variable: where your workload sits on the bandwidth-compute spectrum.
Short-context, high-throughput workloads — chatbots, classification, structured extraction — are bandwidth-bound during decoding. PagedAttention and continuous batching yield the largest gains. A serving engine like vLLM or SGLang with FlashAttention-3 on Hopper-class hardware is the current production baseline. If your median prompt fits in 4K tokens, most of the quadratic cost is manageable; the engineering effort should focus on batching efficiency and memory scheduling.
Long-context workloads — document analysis, retrieval-augmented generation with large context windows, multi-turn agents holding conversation history — hit the quadratic wall proportionally harder. KV cache compression and quantization matter more than raw throughput scheduling. If sequences regularly exceed 32K tokens, the KV cache alone can exhaust an H100’s memory for a single request, before batching enters the picture at all.
Latency-sensitive workloads sit in between. Speculative decoding reduces time-to-first-token by front-loading computation, but it introduces draft-model selection and maintenance as an operational concern.
Rule of thumb: If your median sequence length doubled tomorrow, would your serving stack survive without adding GPUs? If the answer takes more than a moment, the quadratic wall is closer than you assume.
When it breaks: The workarounds are not free. Speculative decoding adds draft-model tuning and maintenance overhead. Aggressive KV cache quantization can degrade quality on tasks requiring precise long-range retrieval — the very tasks where long context matters most. And purpose-built silicon like the Groq 3 LPU is not yet in production; the bandwidth figures are projections, not field measurements. Every workaround trades one constraint for another; the engineering discipline is knowing which trade-off your workload can absorb.
The Data Says
Inference cost has dropped a thousand-fold in three years, and every major workaround — PagedAttention, FlashAttention, speculative decoding, KV cache compression — attacks a different face of the same quadratic wall. The wall has not moved. The engineers have learned to build closer to it, and the remaining distance is measured in bytes of memory that no one can afford to waste.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors