Lost in the Middle, 1,250x Cost: The Limits of Long-Context vs RAG

Table of Contents
ELI5
Long-context windows read everything at once but lose the middle, run slow, and cost orders of magnitude more per query. RAG retrieves the relevant fragments first. They are complements with different failure modes — not competitors.
A recurring claim drifts through engineering Slack channels every quarter: the million-token window has arrived, retrieval is obsolete, just dump the corpus into the prompt. The benchmarks tell a less dramatic story. Models that advertise 128K, 200K, or a million tokens routinely collapse on multi-fact recall well below those numbers, and the per-query economics for full-context inference are not on the same chart as a vector lookup followed by generation. The interesting failure is not whether long-context “works.” It is the geometry of how it fails.
Why “RAG Is Dead” Was Always a Shape Mistake
The “RAG is dead” framing treats Long Context Vs RAG as a winner-take-all decision: long-context wins on simplicity, RAG wins on cost, eventually one displaces the other. The decision shape is wrong. RAG and long-context are not two implementations of the same retrieval contract. They are two different retrievers with different failure surfaces.
A long-context model retrieves by attending — it fans the entire input across attention heads and lets the softmax decide which tokens to weight. A RAG pipeline retrieves by selecting — it filters the corpus down to a small set of likely-relevant chunks before the model sees anything. Both produce a context for generation. Only one produces a context the model has any hope of attending to faithfully when the input gets long.
That asymmetry is the whole article.
Position Bias and the Geometry of Attention
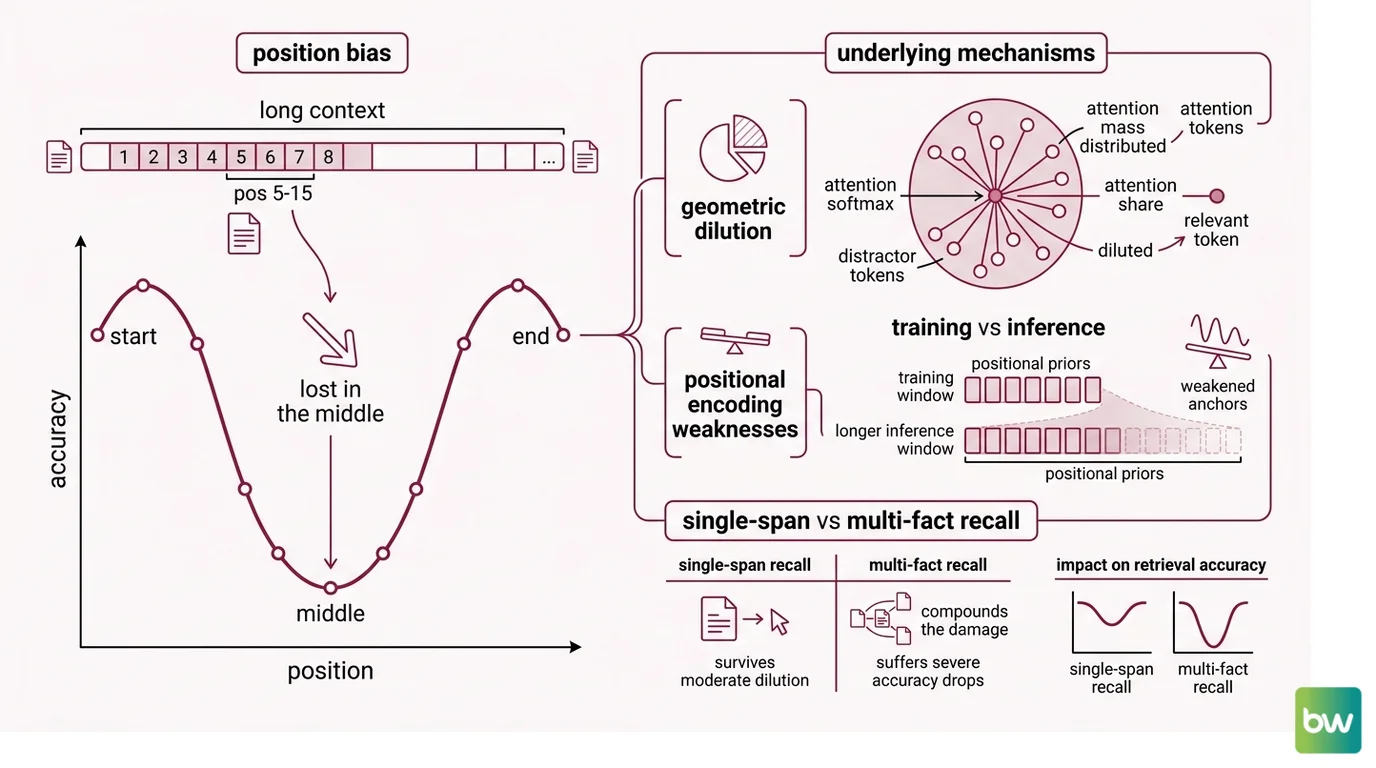
The first failure mode has a name. Liu et al. (2023) gave it that name in “Lost in the Middle,” published on arXiv in July 2023 and later in TACL 2024. They placed a target document at varying positions inside a long context and measured retrieval accuracy. The result was not a smooth degradation. It was a U-shape: highest accuracy at the start and end, lowest in the middle.
That U-shape is not a quirk of one model. Chroma’s 2025 reproduction across eighteen frontier models — including GPT-4.1, Claude Opus 4, Gemini 2.5 Pro, and Qwen3-235B — found that every single model degrades as input length grows, and the position effect was substantial. When the relevant document was placed at positions 5 through 15 of a twenty-document context, accuracy dropped roughly thirty points or more compared to position 1 or 20 (Chroma Context Rot Report).
Why does long-context accuracy drop on multi-fact recall compared to RAG?
The mechanism is not mysterious — it is geometric. Attention in a transformer is a softmax over inner products. As the number of tokens grows, the softmax distributes its mass across more competitors. If the relevant token has to compete against tens of thousands of plausibly-related distractors, its share of the attention budget shrinks. The model does not “lose interest” in the middle. The middle has been mathematically diluted.
A second mechanism layers on top: positional encoding schemes — RoPE, ALiBi, and their variants — were trained on shorter contexts. At inference time, models extrapolate to windows longer than they ever saw during training. The positional priors that anchor “where in the input is this token” weaken as you push past those training distributions, and the model preferentially attends to positions whose encodings it has seen most often: the very beginning and the very end.
Multi-fact recall compounds the damage. Single-span retrieval — find one paragraph — survives moderate dilution because one strong token-level match still wins. Multi-hop recall requires the model to bind several facts scattered across the context. HotpotQA-style multi-hop tasks degrade roughly twice as fast as single-span SQuAD at equivalent context expansion (Atlan analysis). Each additional hop is another softmax that has to land cleanly.
NoLiMa makes the mechanism explicit. The benchmark, introduced by Modarressi et al. (2025), extends Needle-in-a-Haystack with “needles” that share no lexical overlap with the query — forcing the model to do latent reasoning rather than literal token matching. The result was sobering: eleven of thirteen models claiming at least 128K context dropped below half their short-context baseline by 32K tokens. Even GPT-4o, the strongest tested model, fell from 99.3% accuracy at short context to 69.7% at long context.
Not a bug in any individual model. A property of attention at scale.
A RAG Evaluation pipeline avoids most of this geometry not by being smarter, but by retrieving fewer tokens before the softmax runs. When the input is two paragraphs instead of two thousand, position bias has nowhere to act.
How Effective Context Trails the Marketed Number
If there is a single number to remember from the 2025–2026 evaluation literature, it is not a context length. It is the gap between advertised and effective context. BABILong (Kuratov et al. 2024) tested popular LLMs on multi-fact reasoning at length and found that models effectively use only ten to twenty percent of their advertised context — the rest is window dressing the model cannot reliably attend to.
Chroma’s report puts it in production terms: a 200K-token window can show significant degradation at 50K tokens, and a 1M-token window still exhibits context rot at 50K (Chroma Research). The marketed number describes what the model will accept as input. It does not describe what the model will reliably retrieve from that input.
There is a stranger finding inside the same report. Across all eighteen models tested, performance was higher on shuffled haystacks than on logically coherent documents. Structural coherence — paragraphs that follow naturally — actively hurts attention, presumably because coherent text concentrates semantically similar tokens that compete with the target. The implication runs against intuition: a well-organized prompt may be a worse prompt than a randomized one for some retrieval tasks.
NIAH alone — vanilla Needle-in-a-Haystack tests — is no longer a useful measure. NoLiMa and RULER replaced it because models had learned to exploit the literal-match shortcut. RULER, NVIDIA’s effective-context benchmark, runs thirteen task configurations across four categories: NIAH variants, multi-hop tracing, aggregation, and QA built on SQuAD and HotpotQA (NVIDIA RULER). Of frontier models claiming at least 32K context, only about half clear the qualitative threshold at that length.
If you are evaluating a model’s real context window, NIAH pass-rates are not evidence. RULER and NoLiMa are.
Where the Math of Cost and Latency Stops Being a Choice
The accuracy story would be enough on its own. Cost makes the decision crisper.
What are the technical limitations of long-context windows and RAG retrieval at scale?
Elasticsearch Labs ran the experiment that gets cited most often. They took a corpus of 303 articles totaling about a million tokens and answered the same queries two ways: by stuffing the entire corpus into a Gemini 2.0 Flash prompt, and by running RAG with sparse and dense retrieval feeding a small subset to the model. The full-context approach cost about ten cents per query and took roughly forty-five seconds. The RAG approach cost about eight thousandths of a cent per query and returned in about a second. The cost ratio worked out to roughly 1,250×; the latency ratio, roughly 45× (Elasticsearch Labs).
Those exact multiples are not universal constants — they describe one experiment on one model with one corpus. The order of magnitude is the point. Long-context inference grows with input size; RAG inference grows with the size of the retrieved subset, which is bounded by design. As corpora scale to hundreds of millions of tokens, the divergence stops being a tuning question and becomes an asymptotic one.
The limitation list runs in both directions. Long-context windows are bounded by quadratic attention cost in many architectures, by positional-encoding extrapolation limits, by the effective-context gap above, and by per-query economics that scale linearly with input length. RAG pipelines are bounded by retriever quality — if the chunk does not surface, the model cannot reason about it — by chunking strategy choices that affect recall, by index freshness and ingestion cost, and by the Sparse Retrieval versus dense-retrieval trade-off that hybrid stacks now resolve at the engine layer.
Neither is the winner. Each is a different shape of constraint.
The current frontier illustrates the architectural pause. Claude Opus 4.7, released April 16, 2026, ships with a 1M-token context and 128K max output (Anthropic Docs). Anthropic moved 1M context to general availability at standard pricing on Opus and Sonnet 4.6 on March 13, 2026 — older articles quoting premium tiers above 200K are stale. Gemini 2.5 Pro is 1M tokens generally available; the marketed 2M expansion was forthcoming but had not shipped as of April 2026 (Google Cloud Vertex AI Docs). Only the older Gemini 1.5 Pro shipped a verified 2M window. The advertised lengths are real. The effective-context numbers behind them are the ones to plan against.
What the Geometry Predicts
The mechanism is most useful as a generator of testable predictions for your own corpus.
- If your queries require binding three or more facts scattered across the input, expect long-context accuracy to fall faster than your context length grows. Multi-hop is where the U-shape bites hardest.
- If you increase context length and observe accuracy stalling or dropping, you have found your effective-context limit. That number is almost always smaller than the advertised one.
- If shuffling your input improves results, the corpus you are passing in is too coherent — semantically similar paragraphs are competing for attention with the target paragraph.
- If your RAG pipeline degrades on paraphrastic queries, the issue is upstream of long-context — your retriever, not your model, is the bottleneck.
Rule of thumb: Use long-context for tasks where the relevant information is short, near the start or end of the input, and the per-query cost at scale is acceptable. Use RAG when the corpus is large, queries are paraphrastic, multi-fact recall matters, or per-query economics are non-trivial. Most production systems eventually use both, with RAG Guardrails And Grounding catching what neither retriever alone gets right.
When it breaks: Long-context fails silently when relevant content lands in the dilution zone — there is no error message, just a confidently wrong answer. RAG fails silently when the retriever does not surface the chunk that contains the answer — the model then either hallucinates or correctly says it does not know. Both failure modes are invisible without an evaluation set that probes positional, multi-hop, and out-of-corpus behavior.
Compatibility notes:
- Gemini 2.5 Pro context (WARNING): Generally available at 1M tokens as of May 2026. The marketed 2M expansion has not shipped — code or articles assuming a 2M window will fail on 2.5 Pro. For 2M-token workloads, route to the older Gemini 1.5 Pro.
- Claude long-context pricing (INFO): 1M context is GA at standard pricing on Opus/Sonnet 4.6 and Opus 4.7 since March 13, 2026. Older blog posts quoting premium tiers above 200K are stale.
- NIAH-only benchmarks (WARNING): Vanilla Needle-in-a-Haystack is no longer informative as evidence of long-context capability. Replace with NoLiMa (lexical-resistant) or RULER (multi-task) when evaluating effective context.
The Data Says
The 2025–2026 evaluation literature converges on one finding: every frontier model degrades as input length grows, the gap between advertised and effective context is roughly an order of magnitude, and the cost asymmetry between full-context inference and RAG retrieval is not closing. RAG and long-context are complements with different failure surfaces, not competitors heading toward a single winner. Plan against the effective-context number, not the marketed one.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors