LoRA vs. QLoRA vs. Full Fine-Tuning: Methods, Trade-Offs, and What You Need to Know First
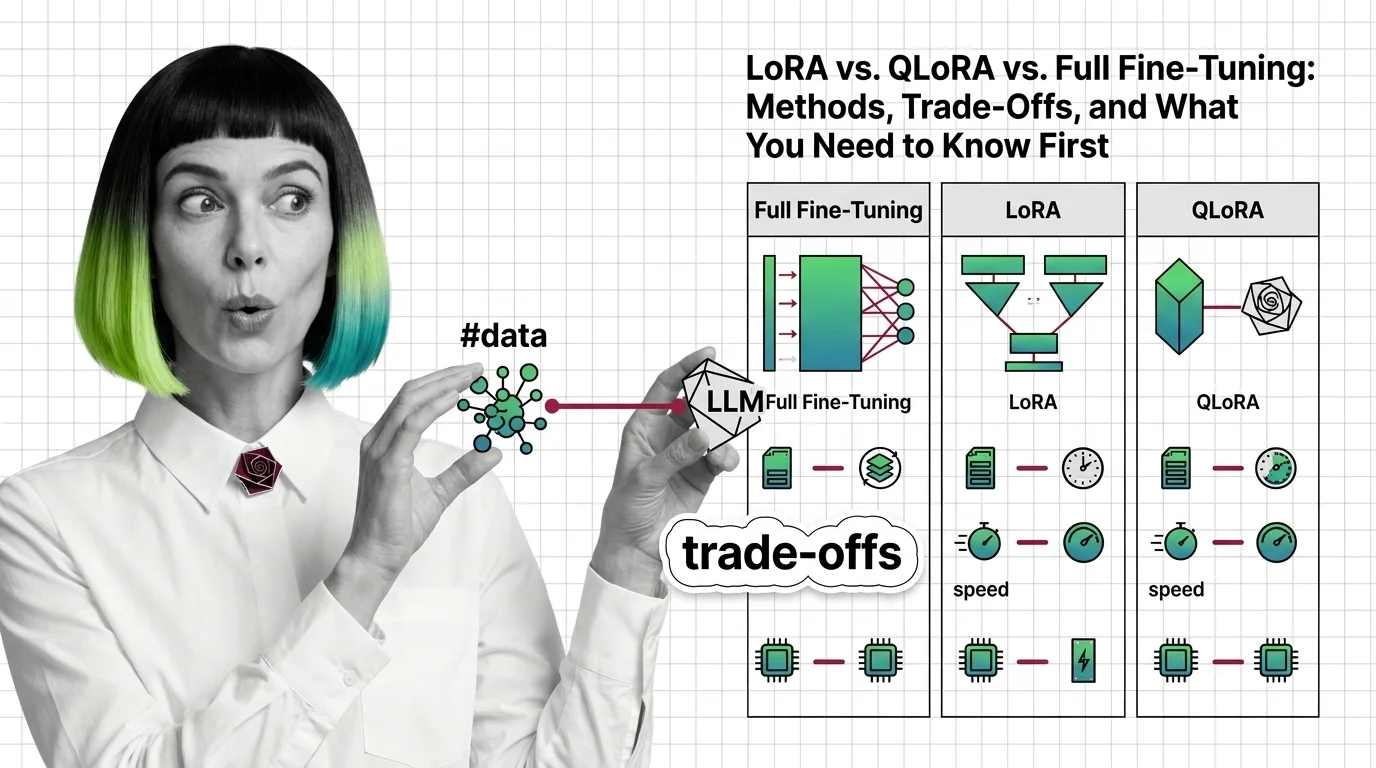
Table of Contents
ELI5
Fine-tuning adjusts a pre-trained model’s weights on new data. LoRA and QLoRA update a small fraction of parameters to save memory. Full fine-tuning updates every weight — more powerful, far more expensive.
Here is a result that should bother you: a research team freezes the pretrained weights of GPT-3 — all 175 billion of them — injects small trainable matrices into the attention layers, and trains 10,000 times fewer parameters than full Fine Tuning would require (Hu et al.). The model still learns the task. That ratio is not a rounding error. It is a clue about how adaptation actually works inside a neural network — and about how little of the architecture you need to disturb.
The Low-Rank Hypothesis and Why It Changes Everything
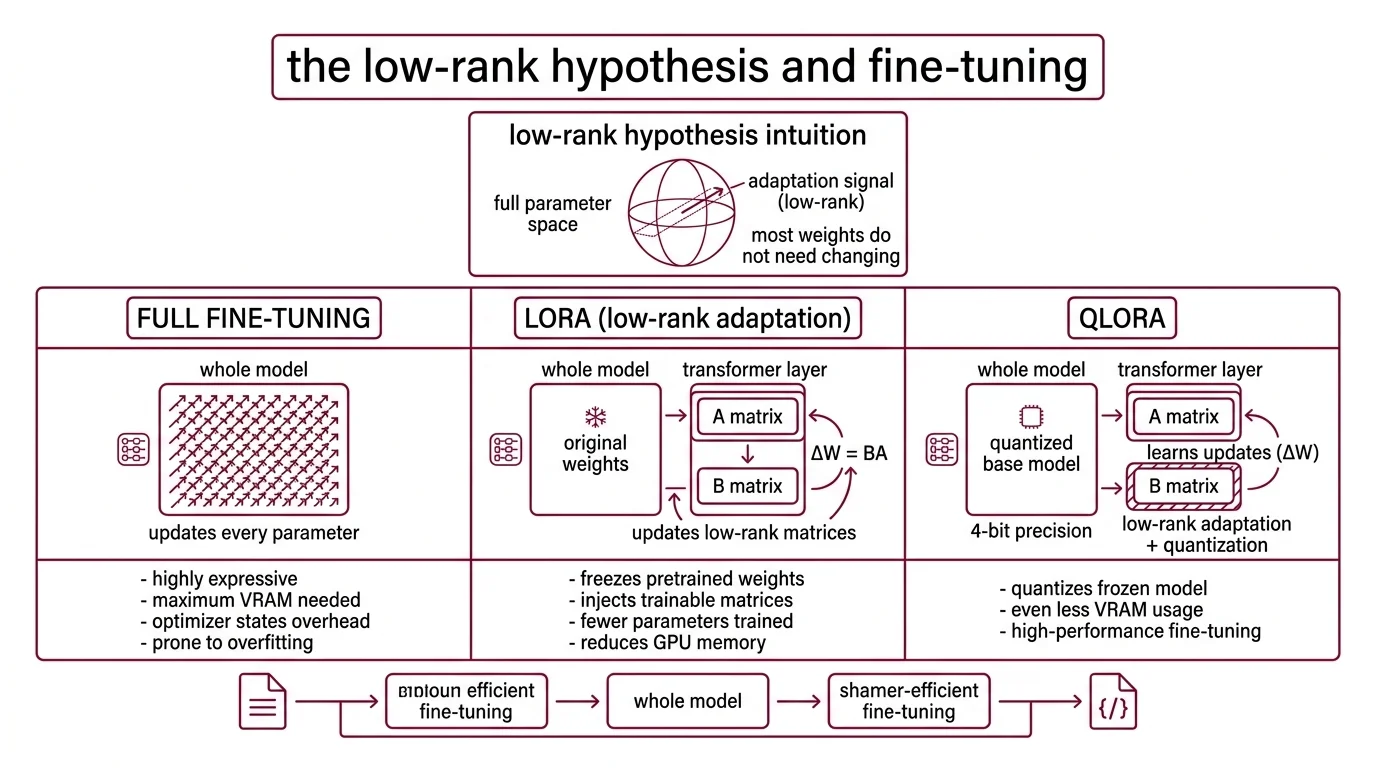
The intuition behind Parameter Efficient Fine Tuning rests on a geometric observation: the weight changes needed to adapt a large model to a new task tend to occupy a low-dimensional subspace. You do not need to move every parameter. You need to find the right direction in a much smaller space — and push.
That observation has practical consequences that split the field into three approaches, each with a different answer to the same question: how much of the model do you actually need to change?
What is the difference between LoRA QLoRA and full fine-tuning?
Full fine-tuning updates every weight in the model. For a 7-billion-parameter model stored in 16-bit precision, that means loading and modifying the entire parameter tensor — roughly 60 GB of VRAM just for the weights, before you account for optimizer states and gradients (Modal Blog). It is the most expressive method: every weight is free to shift. It is also the most expensive, the most prone to Overfitting on small datasets, and the hardest to recover from when things go wrong.
LORA — Low-Rank Adaptation — takes a different approach. It freezes all pretrained weights and injects pairs of small, trainable rank-decomposition matrices (A and B) into the transformer’s attention layers (Hu et al.). Instead of updating a weight matrix W directly, LoRA learns a low-rank update ΔW = BA, where B and A have far fewer rows and columns than W. The original GPT-3 experiments achieved this with 10,000 times fewer trainable parameters and a 3x reduction in GPU memory. Typical configurations train between 0.5% and 5% of total parameters (Modal Blog).
The adaptation signal is low-rank. Most of the information the model already has does not need to change — only the direction of the update matters, and that direction lives in a subspace far smaller than the full parameter space.
QLORA pushes the efficiency further by quantizing the frozen base model to 4-bit precision using a custom data type called NormalFloat4 — NF4 — which is information-theoretically optimal for normally distributed weights (Dettmers et al.). The trainable LoRA matrices remain in higher precision; only the frozen weights get compressed. Combined with double quantization and paged optimizers, QLoRA achieves roughly 4x memory reduction compared to standard LoRA.
In practice, that translates to:
| Method | Precision | VRAM (7B model) | VRAM (70B model) |
|---|---|---|---|
| Full fine-tuning | 16-bit | ~60 GB | impractical on single GPU |
| LoRA | 16-bit | ~16 GB | multi-GPU required |
| QLoRA | 4-bit | ~6 GB | ~48 GB (single GPU) |
A 65-billion-parameter model fine-tuned on a single 48 GB GPU. That is the promise — and the trade-off is quantization noise. QLoRA can introduce knowledge loss and lower-quality outputs in some tasks; the degradation is not universal but depends on how much the quantized representation distorts the information the specific task relies on (Modal Blog).
Three Feedback Loops That Shape Different Properties
Fine-tuning a model’s weights is only half the problem. The other half is what signal drives the updates. Supervised Fine Tuning, RLHF, and DPO are not interchangeable tools — they shape different properties of the model’s behavior, and choosing the wrong one produces a model that is technically trained but functionally misaligned with what you actually wanted.
These three methods are orthogonal to the LoRA-versus-full decision. You can combine SFT with full fine-tuning or with QLoRA; you can run DPO on top of a LoRA adapter. The parameter method determines how much you change. The feedback loop determines what you change toward.
What is the difference between SFT RLHF and DPO in fine-tuning?
Supervised fine-tuning is the simplest loop: you provide input-output pairs, and the model learns to minimize the difference between its output and yours. It teaches the model what to say. SFT is where most fine-tuning projects start — and where many of them should stop. If you have high-quality examples that cover the task distribution, SFT gives you a directly controllable training signal with the lowest infrastructure overhead.
RLHF — reinforcement learning from human feedback — adds a second model to the process. First, you train a reward model on human preference judgments: given two outputs, which one is better? Then you use that reward model to generate a training signal for the base model via proximal policy optimization. Ouyang et al. demonstrated this approach for aligning language models with human instructions; it powered the behavioral shift that made early ChatGPT feel less like an autocomplete engine and more like an assistant.
The cost is architectural complexity. RLHF requires training and maintaining a separate reward model, running PPO optimization — which is notoriously unstable — and managing the interaction between two models that can drift apart during training.
DPO collapses that pipeline. Rafailov et al. showed that you can reformulate the RLHF objective as a classification loss applied directly to preference pairs, eliminating the reward model entirely. The model itself becomes the implicit reward model. DPO reduces compute by approximately 40% relative to RLHF, though that estimate comes from usage-context data rather than a controlled benchmark — treat it as directional, not exact.
The difference is architectural, not cosmetic. SFT optimizes for imitation. RLHF optimizes for a learned proxy of human judgment. DPO optimizes for pairwise preferences without the proxy. They converge on different regions of the output distribution, even when trained on overlapping data.
Before You Touch a Single Weight
Fine-tuning frameworks are getting easier to run — Hugging Face’s PEFT library (v0.18.1) wraps LoRA and QLoRA into a few configuration lines; tools like Unsloth offer faster training with reduced memory overhead through custom kernels (Unsloth Docs). The barrier to starting is low. The barrier to getting useful results is not.
What do you need to understand before fine-tuning an LLM?
The first prerequisite is understanding Scaling Laws — not as abstract research, but as a constraint on what fine-tuning can and cannot do. A model’s base capabilities are determined by its pretraining compute budget. Fine-tuning does not add new capabilities; it surfaces and redirects existing ones. If the base model does not encode the knowledge your task requires, no amount of adapter matrices will conjure it.
The second is Learning Rate sensitivity. Fine-tuning learning rates are typically orders of magnitude smaller than pretraining rates — too high and you destroy the pretrained representations (catastrophic forgetting); too low and the model barely moves. LoRA is more forgiving here because the frozen weights act as an anchor, but the LoRA matrices themselves still require careful tuning. A reasonable starting configuration for most experiments: rank 16, DoRA enabled, targeting all linear layers.
The third — and the one most often ignored — is data quality. Fine-tuning amplifies whatever patterns exist in your training data, including the bad ones. Overfitting on a small, noisy dataset does not just produce worse outputs; it produces confidently worse outputs. The model learns to replicate your mistakes with the same fluency it uses for everything else.
Not ignorance. Fluent overconfidence.
What the Trade-Offs Actually Predict
If you have fewer than a few thousand high-quality examples, full fine-tuning will almost certainly overfit — the model has too many degrees of freedom for too little data. LoRA or QLoRA with a modest rank will constrain the model enough to generalize. If your task requires the model to learn a genuinely new output format — structured JSON with domain-specific schemas, say — SFT on clean examples will get you further than preference-based methods.
If you want the model to choose between good and better (tone, safety, style), DPO on preference pairs gives you the most direct control with the least infrastructure. If you need the model to handle genuinely ambiguous trade-offs where “better” is itself uncertain, RLHF’s separate reward model gives you a tunable proxy that DPO does not offer.
Rule of thumb: start with SFT on clean data using LoRA. If the outputs are functional but the model’s judgment is wrong — choosing the wrong tone, violating unstated preferences — add DPO. Full fine-tuning and RLHF are last resorts, not starting points.
When it breaks: LoRA’s low-rank constraint assumes the adaptation signal is compressible. For tasks that require broadly distributed weight changes — domain transfer from English legal text to Mandarin medical records, for instance — the low-rank bottleneck can cap performance below what the base model is capable of. The efficiency advantage disappears into the gap between what LoRA can represent and what the task demands.
The Data Says
Fine-tuning is not one decision. It is three: how much of the model to update (LoRA, QLoRA, or full), what signal to use (SFT, RLHF, or DPO), and whether your data is good enough to justify any of it. The methods that require the least compute are often the right starting point — not because they are cheap, but because the constraint they impose matches the low-rank structure of most adaptation tasks.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors