LLM-as-Judge Bias and the Technical Limits of RAG Evaluation
Table of Contents
ELI5
RAG evaluation uses one language model to score another. That works — until the judge has its own biases, the metrics need ground-truth references they were sold as not needing, and swapping the judge changes the score.
A team runs the same RAG Evaluation suite on the same retrieval pipeline twice in one afternoon. The pipeline did not change. The corpus did not change. The questions did not change. The faithfulness score moved by several points. The only thing that shifted between runs was the underlying judge LLM the evaluation framework called — a routine upgrade nobody flagged. The score followed the judge, not the system being judged.
That is not a bug in the framework. It is the framework working as designed. RAG evaluation, as currently practiced, is a recursive measurement problem: you are using a probabilistic system to grade another probabilistic system, and the grading is itself a sampled inference. Most of the discomfort engineering teams feel about RAGAS scores comes from this fact, even when they cannot articulate it.
This article walks through where the floor is — the set of technical limits that no amount of prompt tuning or metric stacking can cross.
What RAGAS Actually Measures, and Where the Description Drifts
RAGAS — the most widely cited reference-free RAG evaluation library — was introduced by Es et al. in 2023 with a clean pitch: evaluate retrieval-augmented generation without ground-truth human annotations (RAGAS paper). The framework defined a small set of metrics that, in principle, could be computed from only the question, the retrieved context, and the generated answer.
That pitch is partly historical. The current RAGAS docs flag most metrics — including Context Precision and Context Recall — as requiring a reference answer (RAGAS Docs). The “reference-free” label survived in marketing copy and in older blog posts. The capability narrowed.
What remains genuinely reference-free is a smaller core: Faithfulness and Answer Relevancy. Both are constructed entirely from LLM judgments. That is where the architecture starts to bite.
The Architecture That Evaluates Itself
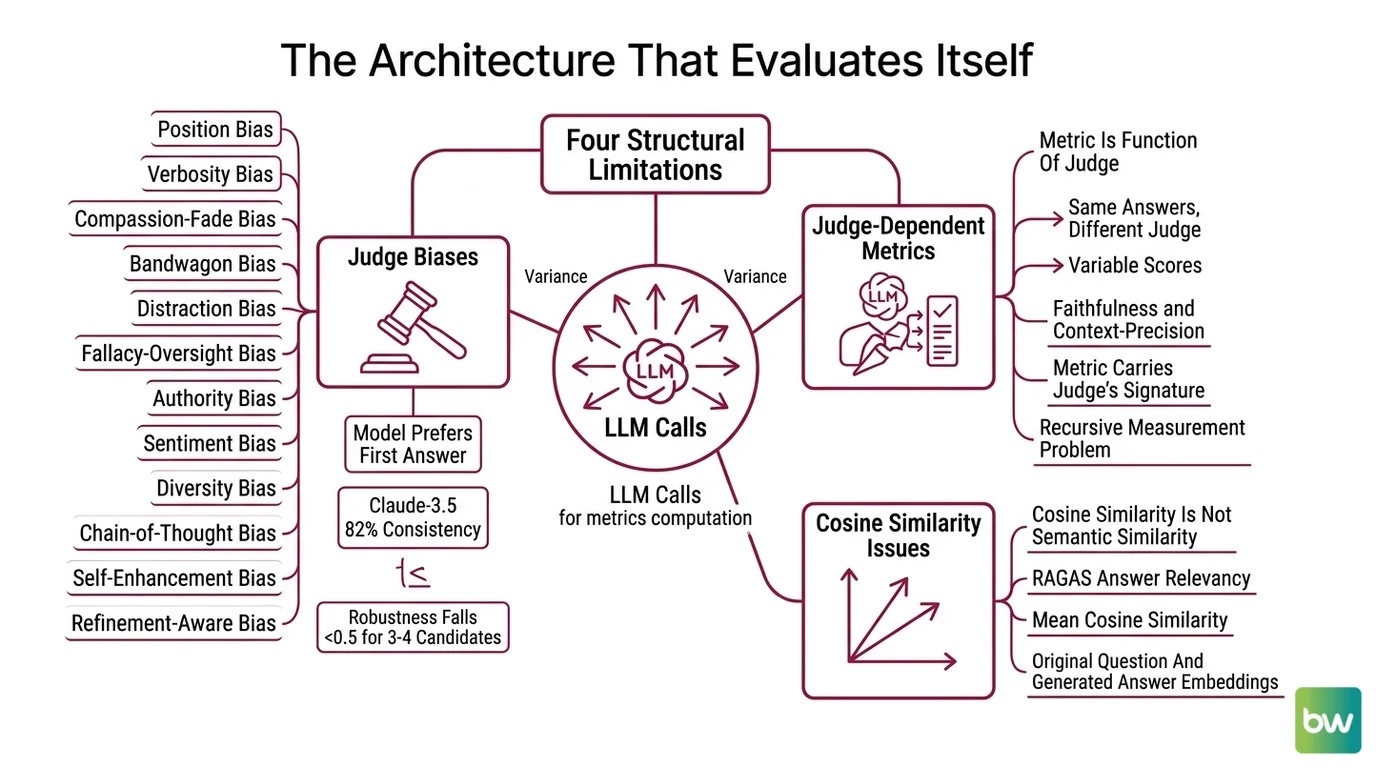
To understand why RAG evaluation has hard ceilings, you have to look at how the metrics are actually computed. They are not arithmetic over deterministic signals. They are LLM calls, with all the variance LLM calls bring.
What are the technical limitations of RAG evaluation frameworks?
There are four limitations that are structural, not implementation details — meaning they survive any choice of judge model, prompt template, or metric stack.
The first is that the judge has biases the system being judged does not. A 2024 systematic study identified twelve distinct bias types in LLM-as-judge setups: position, verbosity, compassion-fade, bandwagon, distraction, fallacy-oversight, authority, sentiment, diversity, chain-of-thought, self-enhancement, and refinement-aware (Ye et al., CALM/Justice or Prejudice). The position-bias finding is the easiest to feel: in pairwise judging, models prefer the first answer they see at rates that vary wildly by judge. Claude-3.5-Sonnet showed roughly 82% position consistency on MTBench, with preference fairness ranging from 0.01 (MTBench) to 0.22 (DevBench, recency-biased) — same model, different datasets, different bias profiles (Shi et al., Position Bias paper). And robustness rates fall below 0.5 once judges compare three or four candidate answers simultaneously (CALM paper).
The second is that the metric is a function of the judge, not just the system being judged. Tweag’s analysis found faithfulness and context-precision scores vary materially when the underlying judge LLM is swapped — the same answers, scored by a different judge, produce a different distribution (Tweag, “Evaluating the evaluators”). This is the recursive measurement problem made concrete: your metric carries the judge’s signature, not the system’s.
The third is that cosine similarity does not track semantic similarity. RAGAS Answer Relevancy is computed as the mean cosine similarity between the original question and N “reverse-engineered” questions generated from the answer (RAGAS Docs, legacy). Cosine similarity in embedding space is a useful proxy for semantic closeness, but it is not guaranteed to be one — modern embedding work has documented failure modes where cosine geometry diverges from human judgments of meaning (Confident AI). The metric is a proxy of a proxy.
The fourth is self-preference, which is real but context-dependent. GPT-4 rates its own outputs higher than other models’ outputs even when source attribution is removed (Self-Preference Bias paper). But Chen et al. (2024c) found that within RAG evaluation pipelines specifically, LLM judges did not exhibit a significant self-preference effect (LLMs-as-Judges Survey). The bias exists; whether it activates depends on the task framing. That is a worse situation than a clean universal bias, because you cannot correct for it with a single offset.
Why faithfulness is harder than it looks
Faithfulness is sold as a clean metric: a score in [0,1] equal to the fraction of claims in the response that are supported by the retrieved context (RAGAS Docs). The number reads like a ratio. It is computed like a probability mass.
The computation is two LLM calls in sequence. First, decompose the response into atomic claims. Second, classify each claim as either inferable from the context or not (RAGAS Docs). Both steps are stochastic. Both steps depend on how the judge tokenizes a “claim.” A response that contains a single nuanced sentence — “the patient’s risk increased by a small but statistically meaningful amount given prior history” — could be split into three claims by one judge and seven by another. The denominator changes. The numerator changes. The ratio changes.
RAGAS does provide an alternative backend: FaithfulnesswithHHEM substitutes Vectara’s HHEM-2.1-Open T5 classifier for the second LLM call (RAGAS Docs). This narrows the variance — a small classifier is more deterministic than a frontier LLM — but it does not eliminate the decomposition step. The judge structure is still LLM-shaped.
Not a bug. A property of the architecture.
Why the Judge Is the System
The deeper point is that LLM-as-judge does not stand outside the system being evaluated. It is part of the same probabilistic substrate.
Consider what a faithfulness score is actually a measurement of. It is the joint output of: (a) the generator’s claim distribution, (b) the retriever’s context, (c) the judge’s claim-decomposition policy, and (d) the judge’s entailment threshold. When you report a single number, you are integrating over four sources of variance. The system being judged contributes only the first two.
This is why inter-judge variance matters more than within-judge stability. A pipeline that scores 0.84 with a GPT-4-class judge and 0.79 with a different frontier model is not telling you the pipeline is unstable. It is telling you the metric is non-uniform in judge identity. If you treat the score as a property of the pipeline, you are misattributing.
There is an alternative architecture worth knowing about. ARES uses fine-tuned classifier judges — not zero-shot LLM scoring — trained on synthetic queries, with statistical confidence intervals attached to each score (Atlan framework comparison). This does not solve the decomposition problem, but it does make the judge a fixed measurement instrument rather than a probabilistic one. The cost is task specificity: a fine-tuned classifier works on the distribution it was trained on. The benefit is interpretability: you can characterize the judge’s failure modes once and trust them across runs.
The trade-off is the one that runs through all of evaluation: precision versus generality. RAGAS’s LLM-as-judge approach is general — point it at any RAG pipeline and it produces numbers. ARES is precise within scope and silent outside it. There is no version of this trade-off that gives you both.
What These Limits Predict
If the architecture is recursive measurement, several predictions follow. Most of them are observable in production with no extra tooling.
- If you swap the judge LLM, expect faithfulness and answer-relevancy scores to shift even though nothing in the RAG pipeline changed. The shift can be material, not noise (Tweag).
- If you increase the number of candidate answers a judge compares simultaneously beyond two, expect robustness to degrade — below 0.5 in the four-candidate regime studied by Ye et al.
- If your evaluation set is small and your judge has a known position bias, expect the rank ordering of candidate pipelines to be unstable across reruns of the same eval.
- If your generator and your judge are the same model family, do not assume self-preference will activate in the RAG context — the literature is mixed (Self-Preference Bias paper; LLMs-as-Judges Survey). Run the cross-judge ablation before drawing the conclusion.
- If you treat a single faithfulness number as a production threshold, you are committing to whatever the judge thinks “supported by context” means today. Judge upgrades will silently move that line.
Rule of thumb: Always report at least two judges’ scores side by side, and report the delta. The delta is the part of the metric that belongs to the judge, not to your pipeline.
When it breaks: RAG evaluation breaks the moment teams interpret a single LLM-as-judge score as a stable property of the pipeline. The score is a property of the pipeline-plus-judge composite. If the judge upgrades, the corpus rebalances, or the metric backend changes, the number moves — and the pipeline itself may be unchanged.
Compatibility & freshness notes:
- RAGAS legacy answer-relevancy API: The
v0.1.xanswer-relevancy implementation is deprecated and slated for removal in v1.0. Code samples in older blog posts may not run on current versions. Action: pin to current RAGAS minor or migrate to the post-v1.0 metric naming.- Reference-free branding (RAGAS): Most current metrics, including context precision and context recall, require a reference answer despite the framework’s historical reference-free positioning (RAGAS Docs). Verify which metrics in your suite actually run reference-free before reporting on that basis.
- Bias taxonomy currency: The 12-type CALM taxonomy is now the de-facto reference for judge-bias audits. Older treatments that cover only position and verbosity bias are incomplete (Ye et al.).
A Quieter Connection
There is one observation that ties this together and that engineering teams rarely articulate aloud. RAG evaluation is the only widely deployed measurement system where the instrument and the object share an architecture, a training distribution, and — frequently — a vendor.
In every other measurement context engineers work with, the instrument is built differently from the thing it measures. A multimeter is not a circuit. A profiler is not the program. The asymmetry is the source of trust. RAG evaluation collapses that asymmetry: the judge is built from the same substrate as the generator, with the same kinds of failure modes. When the score looks too clean, it is sometimes because the judge and the generator are agreeing on the same shared error.
The fix is not “use a better judge.” It is “stop pretending one judge is enough.”
The Data Says
RAG evaluation frameworks are useful, but the metrics they produce are joint properties of the pipeline and the judge — not the pipeline alone. Any single LLM-as-judge score sits inside a documented bias taxonomy of twelve distinct effects, varies materially with judge identity, and depends on a claim-decomposition step that is itself stochastic. Treat the numbers as directional signals, not measurements.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors