Cross-Encoder Reranker Limits: Latency Walls and Domain Drift
ELI5
Reranking with a Cross-Encoder hits two architectural walls: latency scales linearly with candidates and quadratically with token length, and MS-MARCO-trained relevance often drifts in legal, financial, and argument-style domains.
The pitch for adding a cross-encoder to a Retrieval Augmented Generation stack is short and convincing: bi-encoder retrieval is fast but coarse, so you re-score the top-k with a model that reads the query and document together and accept the latency cost in exchange for a relevance lift. Teams put one in, watch the rankings improve, and ship. Then the document length distribution shifts, or the index grows, or someone asks why the p99 just doubled, and the answer is not a bug. The answer is the math the model is doing — every time, on every pair, in every request.
The Strength to Name Before the Limits
It is fair to start with what cross-encoders are actually good at, because the rest of this article is about where they break. In Rosa et al.’s 2022 BEIR study, the largest cross-encoders beat the strongest bi-encoder by more than 4 nDCG points on average across the benchmark, and the gap widened on out-of-domain corpora the encoders had never seen during fine-tuning (Rosa et al. (2022)). The same paper offers a sharper formulation worth quoting verbatim: “Increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning.” Translated: cross-encoders are the part of the retrieval stack that generalizes when the corpus shifts. That is the reason you put one in. The 2024 SPLADE comparison from Déjean et al. extended the result against GPT-4 zero-shot listwise reranking and concluded that traditional cross-encoders “remain very competitive,” with the effect depending on both model type and the number of documents reranked (Déjean et al. (2024)).
The cross-encoder is not the obsolete part of the retrieval stack. It is the part doing real work.
The walls are real anyway.
The Latency Wall Has Two Geometries
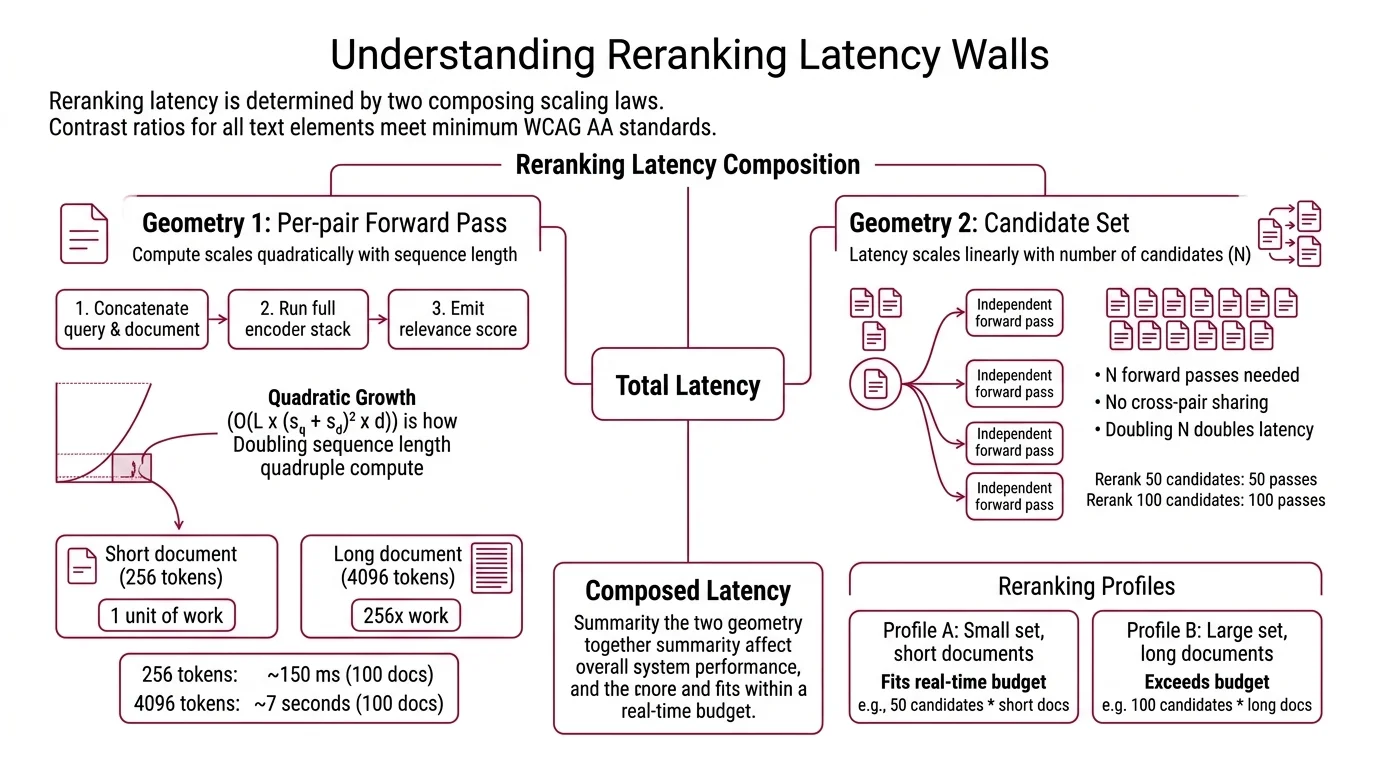
The cost of reading a query-document pair through a transformer is not a single number. It has a shape, and the shape is what determines whether your reranker fits inside a real-time budget. Two scaling laws compose, and both are baked into the architecture rather than tunable from the API.
Why does reranking add so much latency to RAG pipelines and how bad is it?
The first geometry is the per-pair forward pass. A cross-encoder concatenates the query and the document into a single sequence, runs it through the full encoder stack, and emits a relevance score. The compute per pair is O(L × (s_q + s_d)² × d), where L is the number of transformer layers, s_q and s_d are query and document token counts, and d is the hidden dimension (Brenndoerfer). The quadratic term in sequence length is the one that bites: a cross-encoder reading a 256-token document is doing one unit of work, while the same model on a 4096-token document is doing roughly 256 units of work on the same hardware. Brenndoerfer’s tables make the shape concrete — 100 documents at 256 tokens each clears in about 150 ms, while the same 100 documents at 4096 tokens each takes about 7 seconds.
The second geometry is the candidate set. There is no cross-pair sharing in a classic cross-encoder — each query-document pair is an independent forward pass, so reranking N candidates costs N forward passes and total latency scales linearly with N. Doubling your retriever’s top-k from 50 to 100 doubles reranker latency. No batching trick gets around this: the attention pattern across query and document tokens is what makes the cross-encoder better than the bi-encoder in the first place.
These two laws compose. A pipeline that retrieves 50 short snippets and reranks with a distilled MiniLM cross-encoder fits comfortably inside a real-time budget — about 8 ms per pair on CPU, so 50 candidates clears in roughly 100–300 ms (Sentence-Transformers Docs). The same pipeline retrieving 100 long-form policy documents at 4 K tokens each can take seconds. The bottleneck is not the model. It is the geometry of the workload you handed it.
How modern rerankers attack the wall instead of denying it
The 2025–2026 wave of rerankers is best read as architectural responses to those two scaling laws. The “cross-encoder = MiniLM, hundreds of milliseconds, MS-MARCO-trained” stereotype is over. The frontier is small Qwen- and gemma-class models, RL-trained, often instruction-following, deliberately engineered to keep a quadratic operator inside a real-time budget. ZeroEntropy’s Zerank-2, released November 2025, posts about 60 ms of latency with native instruction-following and multilingual coverage at $0.025 per million tokens (ZeroEntropy Blog). On the open-weights side, mixedbread’s mxbai-rerank-large-v2 is a 1.5 B-parameter Qwen-2.5 base trained with reinforcement learning rather than cross-entropy, released March 2025 under Apache 2.0, at about 0.89 seconds per query on an A100 (Mixedbread Blog). These are not the same product as a 2021-era MiniLM reranker. They are deliberate engineering against the wall.
Two other techniques attack latency directly. Distillation produces small student cross-encoders that retain accuracy within roughly 2 nDCG of their teacher at 2–3× lower latency (Brenndoerfer). Early-exit cross-encoders — formalized in “Efficient Re-ranking with Cross-encoders via Early Exit” (ACM SIGIR) — terminate the forward pass at intermediate layers when the score is already confident, paying the full quadratic cost only on the hard pairs. Both still leave the per-pair quadratic in token length intact for the cases that need the deepest read.
The architecturally interesting alternative is to abandon the per-pair structure entirely. Listwise Reranking models score a slate of documents in a single pass, which lets the model reason across candidates rather than independently scoring each. The cost has historically been latency: pointwise LLM rerankers run 1000–3000 ms per query and listwise LLM rerankers above 5 seconds, putting them out of reach for most real-time RAG (ZeroEntropy Blog). Jina’s jina-reranker-v3, released September 2025, is the first listwise reranker engineered for real-time budgets — a 0.6 B-parameter Qwen3 base with a 131 K-token context window that scores up to 64 documents in a single forward pass (Hugging Face). The license is the catch. Jina Reranker-v3 ships under CC BY-NC 4.0 (non-commercial), so production teams need an enterprise contract to deploy it, and the better Apache-licensed comparator for engineering choices is mxbai-rerank-large-v2.
Security & compatibility notes:
- jina-reranker-v3 license: CC BY-NC 4.0 — non-commercial only. Production deployments require an enterprise contract from Jina (AWS / Azure marketplace or sales).
- naver/splade (often used as the sparse first stage before a cross-encoder): Last release Oct 2023; license CC-BY-NC-SA 4.0 — non-commercial. Production users must move to derivative open-licensed sparse encoders.
- BAAI/bge-reranker-v2-m3: Hard 512-token maximum. Documents above that limit are silently truncated and recall degrades. Chunk before reranking.
- sentence-transformers v4.0+:
CrossEncoder.fitis softly deprecated; the new API isCrossEncoderTrainer+CrossEncoderTrainingArguments. Tutorials referencing.fit()directly are out of date.
Domain Drift Is the Quieter Wall
The latency wall is the one operators see first, because it shows up in p99 dashboards. The domain wall is the one that ships into production unnoticed and degrades silently, because the model still returns scores — the scores are just measuring something other than what you wanted.
What are the technical limitations of cross-encoder rerankers in production?
The classic ms-marco-MiniLM cross-encoders, and most of their pre-2025 successors, were fine-tuned on the MS MARCO passage ranking dataset — a corpus of web search queries and short web passages with relevance labels reflecting how human raters judge web-search relevance (Sentence-Transformers Docs). What that fine-tuning teaches the model is a specific notion of relevance: short query, short candidate, factoid-style match. Point that model at financial-compliance documents, legal opinions, or biomedical literature, and the relevance signal does not reliably map. The model still scores. The scores still rank. The ranking is now measuring a similarity that the auditor or the clinician would not necessarily endorse.
The cleanest published example is Touché-2020 in BEIR. On the argument retrieval task, neural rerankers — including the multi-vector CITADEL+ family — underperform plain BM25, which scores nDCG@10 of about 0.367 on the task (BEIR Benchmark Topic). The mechanism is unflattering: argumentative passages tend to be long and dense, while the rerankers learned during MS MARCO fine-tuning a strong prior toward short, lexically overlap-rich passages. The model is doing exactly what its training distribution rewarded. The training distribution was the wrong shape for this corpus.
Two qualifications matter. First, this is a domain-shift caveat, not a blanket failure. Cross-encoders fine-tuned on in-domain pairs in legal, financial, and biomedical corpora close most of the gap; the limit is not “cross-encoders fail on legal” but “MS-MARCO-pretrained cross-encoders learn web-search relevance, which is not always the relevance you need.” Second, “cross-encoders trained on MS MARCO only” is itself out-of-date framing. Frontier rerankers — zerank-2, mxbai-rerank-v2, jina-reranker-v3 — are trained with reinforcement learning, zELO-style ELO-inspired pairwise training (arXiv), and multilingual data mixes that go well beyond MS MARCO.
The 2025–2026 architectural answer to domain drift is instruction-following. Voyage Rerank 2.5 was the first commercial reranker explicitly engineered to take a natural-language instruction as part of the input, so the same model can be steered toward “rank by argumentative strength” or “rank by regulatory relevance” without retraining (Voyage AI Blog). At release in August 2025, its 32 K context window was 8× Cohere Rerank v3.5’s and 2× the previous Voyage rerank-2; Cohere has since closed the gap with Rerank 4 and Rerank 4 Fast in December 2025, both at 32 K context with multilingual coverage across more than 100 languages and a self-learning capability the earlier line did not have (Cohere Changelog). Treat the December 2025 release date as Tier-2 confidence — it appears in third-party reporting more clearly than in the official changelog excerpt verified for this article.
A note on benchmark numbers. BEIR nDCG@10 scores quoted on individual model cards — jina-reranker-v3 at 61.94 (Hugging Face), mxbai-rerank-large-v2 at 57.49 (Mixedbread Blog) — are best read as rough magnitude evidence, not a head-to-head leaderboard, since vendors use different aggregation conventions and different subsets.
What the Geometry Predicts
Two scaling laws and one domain prior give you a usable predictive model of where a cross-encoder reranker will fail before you measure it.
- If your candidate set is fixed but document length grows — say you start indexing full policy documents instead of summary passages — expect a roughly quadratic latency increase in token length. Chunk first, rerank chunks, then merge.
- If your top-k grows and the latency budget is fixed, you cannot rerank more candidates without paying the linear scaling. Either move to a smaller distilled student, switch to a listwise reranker that scores a slate in a single pass, or accept that the marginal candidate is not worth it.
- If your domain drifts away from the web-search distribution — argument retrieval, legal precedent, regulatory compliance, scientific literature — expect MS-MARCO-pretrained cross-encoders to underperform their Hybrid Search BM25 baseline on the hardest tasks before any in-domain fine-tuning. Touché-2020 is the published example, not the only one.
- If you need to steer the same model across multiple domains without redeploying, an instruction-following reranker is the architecture that matches the requirement — not a bigger generic cross-encoder.
- If you need to catch a reranker regression in production rather than only at deploy time, the Agentic RAG verification pattern wraps the reranker output in a downstream evaluator that scores the actual answer’s faithfulness against the top-ranked chunk — moving relevance into a continuous gate rather than a property you check once.
Rule of thumb: measure your reranker’s p95 latency at production token-length and candidate-count distributions, not at the model card’s defaults; measure relevance on a labeled in-domain eval set, not on BEIR.
When it breaks: the architecture has no built-in mechanism for cost-aware reranking — every candidate gets the same expensive treatment regardless of how confident the bi-encoder already was. Until your pipeline implements early exit, a cascade of progressively heavier rerankers, or an explicit budget gate, the worst-case workload (long documents × large top-k × out-of-domain queries) sets your p99 latency and your relevance ceiling at the same time.
The Data Says
Cross-encoder rerankers are the part of the retrieval stack that is supposed to generalize when the corpus shifts, and the BEIR evidence says they do — when scaled. The architecture pays for that generalization with a per-pair quadratic in token length and a linear scan over candidates, and it inherits whatever notion of relevance its fine-tuning corpus imprinted. The 2025–2026 generation of rerankers — RL-trained, instruction-following, listwise where it can afford to be — is not a replacement for cross-encoders. It is the cross-encoder taken seriously about its own limits.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors