Query Transformation Limits: Latency Tax, Drift, Hallucinated Documents
ELI5
Query Transformation rewrites a user query before retrieval. It works — but every rewrite pays three structural costs: an extra LLM call, drift that narrows what it tried to expand, and hallucinated content that grounds retrieval in fabricated text.
Query transformation sells the idea that retrieval fails because the user’s query is poorly phrased — rewrite it, and recall rises. Teams build that pattern, run it on real traffic, and watch latency climb on cheap queries while the difficult ones still miss. The bottleneck did not vanish; it moved. Three structural limits explain where it went.
The Latency Tax: Every Rewrite Buys an LLM Round-Trip Before Search
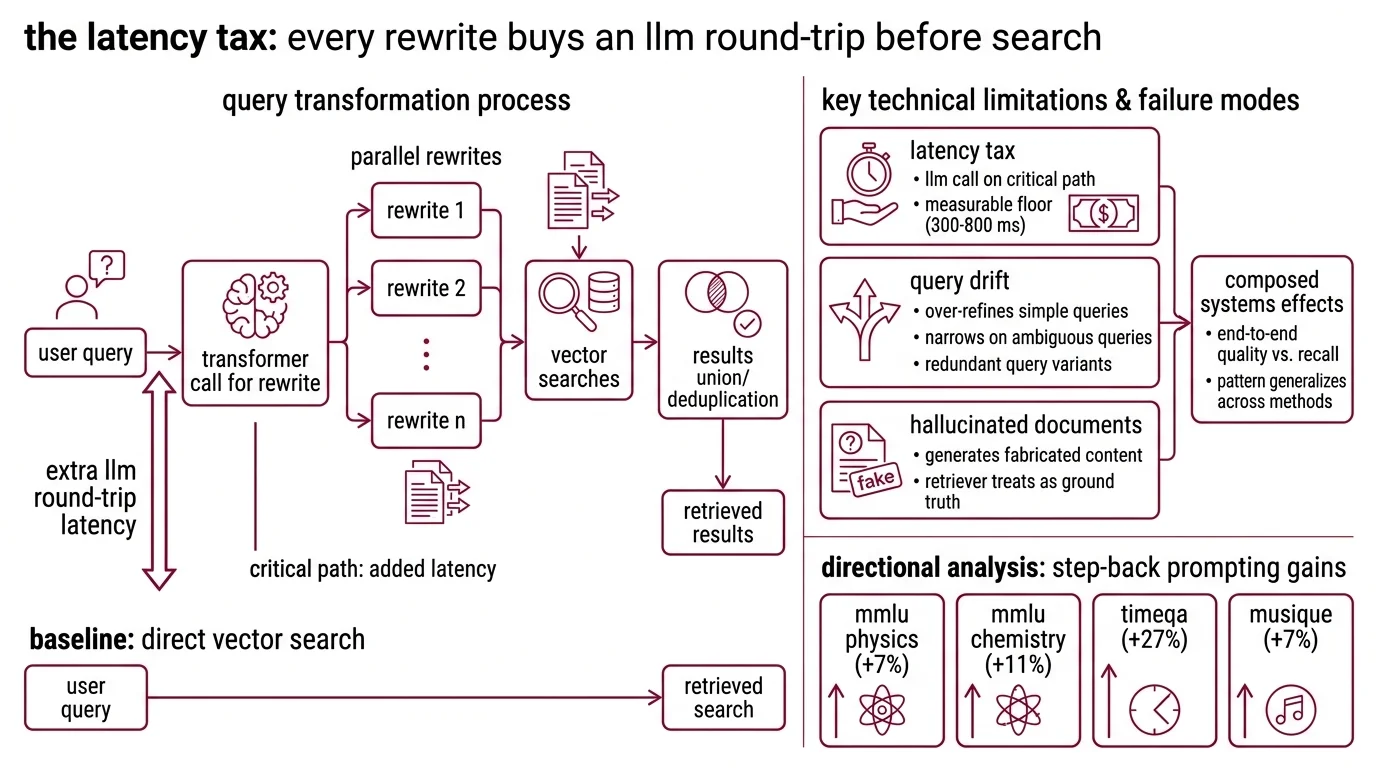
Vector search is fast. The transformer call that decides what to vector-search for is not. That asymmetry is the first structural limit, and the LangChain default makes it concrete: a MultiQueryRetriever issues N parallel rewrites, runs N searches, then unions and dedups (LangChain Docs). The retrieval gain has to clear the cost of one extra LLM round-trip before it shows up in user-visible latency.
What are the technical limitations and failure modes of query transformation?
There are three, and they compose. The first is the latency tax — every transformation puts at least one LLM call on the critical path before the vector search runs. The second is query drift: rewriting can over-refine simple queries, narrow on ambiguous ones, or fan out into redundant variants. The third is hallucinated documents — methods like HyDE generate fabricated content that the retriever then treats as ground truth. Each is a property of how the rewriter is wired into the pipeline, not a defect in any one technique, and the same three surfaces show up across HyDE, multi-query, step-back, decomposition, and trained rewriters.
The latency cost has a measurable floor. A 2025 production analysis of enterprise RAG deployments reported default agent configurations over-retrieving on 42% of simple factoid queries, adding 300–800 ms of latency that produced no recall gain (Mudassar Hakim — directional, single-source engineering analysis). Step-Back Prompting from Google DeepMind illustrates the same shape at the high end: gains of +7% on MMLU Physics, +11% on MMLU Chemistry, +27% on TimeQA, and +7% on MuSiQue (Zheng et al. 2023) — but every one of those queries paid for an additional abstraction-step LLM call before retrieval ran, and those benchmarks are reasoning-heavy multi-hop or temporal QA, not retrieval recall on its own. The pattern generalizes: end-to-end answer quality lifts on hard inputs, while every cheap input pays the same fixed tax.
The architecture, in one sentence: the rewrite runs before the search. Production patterns have evolved around it — a small, fast rewriter (GPT-4o-mini, Haiku, or Llama-3.1-8B) feeds a slower reader; an iteration cap of three cycles resolves roughly 95% of queries that benefit from re-retrieval before runaway cost (DEV Community, Kuldeep Paul). Both are workarounds for a tax that does not go away. They make it bearable.
Query Drift: Rewriting Refines What It Should Have Left Alone
The second limit is subtler because it sounds like the opposite of a problem. The whole point of the rewriter is to refine the query — except refinement, applied indiscriminately, is its own failure mode. The Q-PRM team named the pattern explicitly: for simple queries, rewriting methods “frequently introduce unnecessary steps, leading to over-refinement”; for complex ones, the same methods under-refine (Q-PRM 2025). The system has no internal signal about which side of that line the current query sits on.
Abe et al. mapped where the failure surfaces. Their two-failure-regime analysis identifies knowledge deficiency — where the LLM lacks the relevant domain knowledge and emits incorrect expansions — and query ambiguity, where the rewriter biases its refinements in ways that narrow search coverage instead of broadening it (Abe et al. 2025). The conclusion is sharp: query expansion can significantly degrade retrieval effectiveness when either condition holds. The rewriter has no signal that it is in those regimes.
Rewriting can narrow as easily as broaden — and the production version of this is what ZenML calls rewrite drift: small, unnoticed query errors that silently degrade end-to-end accuracy as the user-query distribution shifts beneath a static rewriting prompt (ZenML Blog). The rewriter keeps producing fluent, plausible reformulations; the retrieval keeps missing in ways no one notices until the eval set catches up. Bias amplification is the adversarial sibling: simple LLM-based rewriting cuts aggregate retriever bias materially under clean conditions but fails when multiple biases combine (bias-rewriting study, 2026). Each rewrite is a chance to over-correct.
Hallucinated Documents: HyDE Grounds Retrieval in Fabricated Text
The third limit is the one most teams underestimate, because the original Hypothetical Document Embeddings paper from Gao et al. argued the architecture defends against it. HyDE generates a hypothetical answer to the user’s query, encodes that synthetic document with an unsupervised contrastive encoder, then retrieves real corpus documents by vector similarity (Gao et al. 2022). The authors’ framing is that the encoder’s dense bottleneck “filters out incorrect/fabricated details” — the embedding flattens the false specifics and preserves the topical signal. That is the original claim. It is not consensus.
When the LLM lacks domain knowledge, the premise is wrong in ways the encoder cannot filter. HyDE retrieves real documents from a fake premise, which is exactly the failure mode Lei et al. mapped on a corpus of 3.4 million Stack Overflow Java and Python posts: standard HyDE struggled in 25% of sampled cases on concept-focused queries — retrieval fetched off-topic content, or the model addressed a broader variant of the question (an AngularJS-syntax query, for instance, returned service-pattern retrieval rather than syntax-level results) (Lei et al. 2025). For specific numerical or factual queries — population of city X, exact API rate limits, model parameter counts — HyDE generates a confidently wrong hypothetical, and the embedding of that wrong answer pulls the retrieval toward documents about the wrong fact (Mudassar Hakim).
The same study makes the case for not abandoning HyDE either. With a similarity-threshold fallback that routes around HyDE when the rewritten query is unlikely to help, Adaptive HyDE materially outperformed accepted Stack Overflow answers as a baseline, with mean LLM-as-judge scores of 6.05 versus 5.04 (p<10⁻⁸²) on developer-support questions (Lei et al. 2025). The threshold itself becomes a coverage-quality dial: at 0.9, only 0.7% of queries pass through HyDE but quality reaches 6.44; at 0.5, every query passes through HyDE and quality drops to 5.13. The architecture’s honesty is in the threshold knob — it admits HyDE is good for some query classes and harmful for others, and forces the system to decide.
Not a fix. A configuration.
What These Limits Predict
Once the three surfaces are in mind, the symptoms in production resolve into something predictable rather than mysterious.
- If your latency p95 jumped after adding a rewriter and your retrieval recall did not move, the queries paying the tax are mostly cheap factoids — the fix is a router that decides whether to rewrite at all, not a faster rewriter.
- If retrieval recall on simple factoid queries got worse after rewriting, you are in over-refinement territory; classify query complexity before sending anything to the rewriter.
- If retrieval misses cluster on unfamiliar-domain queries, you are watching the knowledge-deficiency failure mode of expansion (Abe et al. 2025) — verify the LLM has any signal about the topic before letting it refine the query.
- If multi-query or decomposition expanded the candidate pool but answer quality dropped, the second-order penalty is in play. Liu et al. documented the U-shape: relevant information at the start or end of a long context is retrieved well, while relevant information in the middle is systematically under-attended (Liu et al. 2023). Over-filling context with redundant rewrites pushes the gold chunk into the dead zone.
- If naive sub-query decomposition retrieves more documents than fit your context budget, you are seeing the tradeoff Petcu et al. quantified: a bandit that selects which decompositions to actually run delivered roughly 35% better doc precision and 15% better α-nDCG than uniform decomposition (Petcu et al. 2025). Selection beats fan-out.
The architectural answer the field converged on between 2024 and 2026 is not better rewrites. It is a layer that decides whether to rewrite. Agentic RAG systems route queries through a lightweight intent classifier first, fall back to direct retrieval when the raw query is good enough, and only spend the LLM budget on inputs that demonstrably need it. Corrective-RAG scores retrieved documents and triggers a rewrite-and-retry only when retrieval confidence is low. The router is the architectural fix; the rewriter is the tool the router decides whether to call.
Compatibility & known anti-patterns:
- LangChain
MultiQueryRetriever: Still maintained, but naive N-query fan-out without a router is a known anti-pattern for simple factoid queries — production guidance now favors adaptive routing (LangChain Docs).- Naive query decomposition (no selection): Demonstrated to hurt downstream generation when the retrieved sub-document set exceeds the context budget; bandit-based selection (Petcu et al. 2025) is the current SOTA pattern.
- Static rewriting prompts (no eval loop): Silently degrade as the user-query distribution shifts (“rewrite drift”); production rewriters need online evals on representative traffic, not snapshot prompt tuning.
- InstructGPT (
text-davinci-003) for HyDE: The original 2022 prompts ran on a deprecated endpoint; modern HyDE uses GPT-4o-mini, Haiku, or Llama-3.1-8B as the rewriter, and older tutorials referencing davinci will fail at runtime.
Rule of thumb: treat the rewriter as a cost center first — every transformation pays a latency tax and risks drift; only spend the cost where retrieval recall on the raw query is demonstrably weak, and only behind a router that can fall back when the rewriter has nothing useful to add.
When it breaks: static rewriting prompts have no internal mechanism to detect their own drift. Without an online eval loop and a router that decides whether to rewrite, the system silently degrades as the user-query distribution shifts — the rewriter keeps sounding fluent while retrieval keeps missing on exactly the queries the eval set never anticipated. Wrap the rewriter in Hybrid Search and Reranking as parallel defenses, not as substitutes for the routing decision.
The Data Says
Query transformation in Retrieval Augmented Generation is not a free upgrade. The latency tax, query drift, and hallucinated documents are properties of the architecture, not bugs in any one method, and they compose to produce the second-order penalty of lost-in-the-middle when over-fanned-out context floods the model. The systems that work in production treat the rewriter as one tool among many, gated behind a router that decides per-query whether the LLM call is worth its cost.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors