Label Noise, Class Imbalance, and Distribution Shift: What to Know Before Fixing Training Data

ELI5
Before you fix a dataset, you need three lenses: label noise (wrong answers in your data), class imbalance (some categories too rare), and distribution shift (training data unlike the real world). Master these first; tools come later.
A team retrains the same classifier for the third week running. Bigger backbone, longer schedule, a fashionable optimizer. Validation accuracy climbs half a point, then stalls. The instinct is to reach for a larger model. The instinct is usually wrong.
The plateau is rarely in the architecture. It is sitting in the labels, in the class frequencies, and in the gap between the data the model trained on and the data it will actually meet. Training Data Quality is not a tooling decision you make at the end of a project. It is a set of failure modes you have to recognize before you can fix anything — and most of them are invisible if you only watch the loss curve.
Not a modeling problem. A data problem.
The Bottleneck Lives Underneath the Model
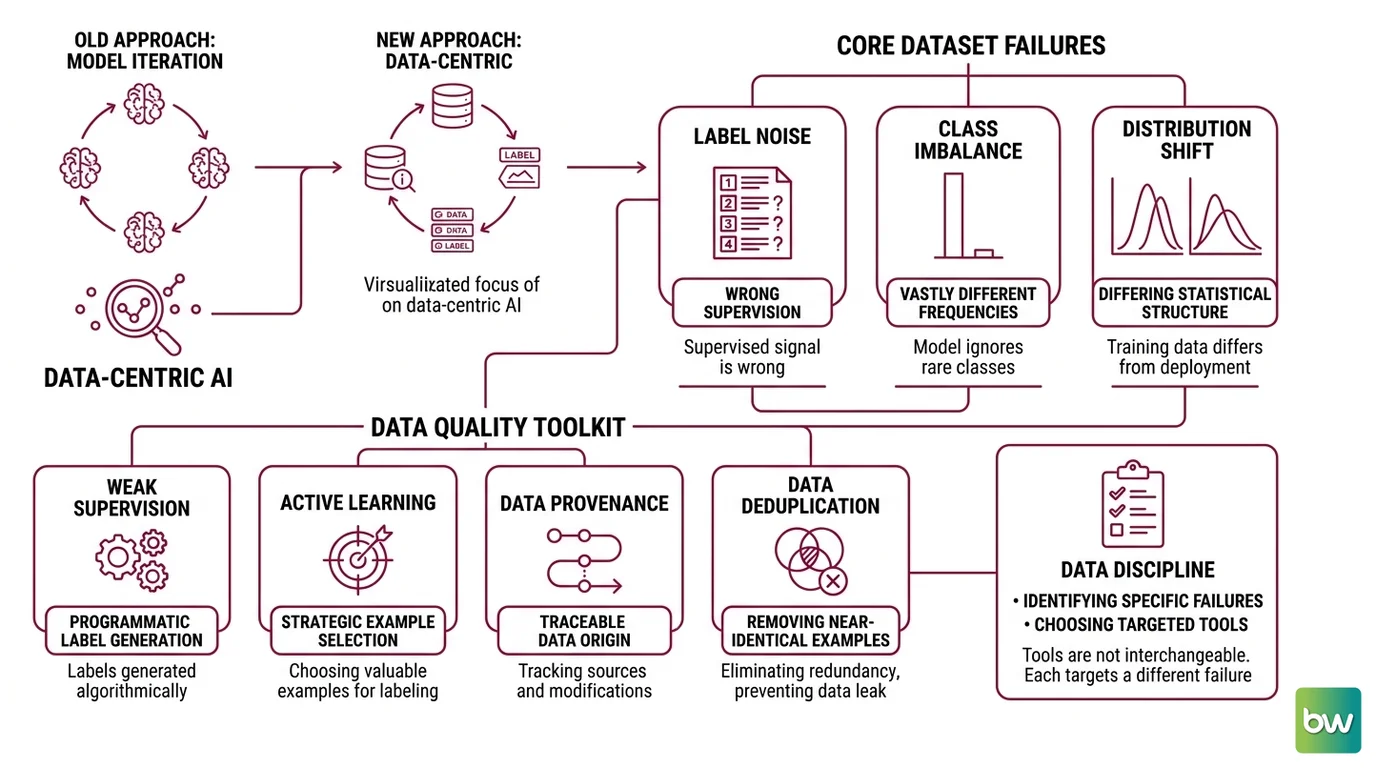
For a decade the reflex was to hold the data fixed and iterate on the model. Data-Centric AI inverts that reflex. Framed as a movement by Andrew Ng around 2021 (MIT Sloan), it argues that for many production systems the fastest path to accuracy is improving the dataset, not the network. Before you can improve a dataset, though, you need a vocabulary for the specific ways data goes wrong.
What concepts should you understand before working on training data quality?
Three failure modes do most of the damage, and they are conceptually independent — a dataset can suffer one, two, or all three at once.
The first is label noise: the supervised signal itself is wrong. The second is Class Imbalance: the categories you care about appear at wildly different frequencies, so the model can score well on paper while ignoring the rare class entirely. The third is distribution shift: the statistical structure of your training data differs from the data the model sees in deployment. Each one breaks a different assumption that supervised learning quietly depends on.
Around those three concepts sits a small toolkit of practices worth knowing by name. Weak Supervision generates labels programmatically when hand-labeling does not scale. Active Learning chooses which examples are worth labeling next, instead of labeling at random. Data Provenance tracks where each example came from and how it was labeled — which is what lets you trace a systematic error back to its source. And Data Deduplication removes near-identical examples that inflate your sense of dataset size while leaking between train and test splits.
These are not interchangeable fixes. Each one targets a different failure. The discipline is knowing which failure you actually have before you pick a tool.
Label Noise: When the Map Lies
Of the three, label noise is the most corrosive, because the model has no way to know it is being misled. A wrong label is not random static the network averages away — it is a confident instruction to learn the wrong boundary.
What is label noise and how does it hurt model training?
Label Noise is the presence of incorrect or inconsistent labels in a training set — usually from annotator error, ambiguous labeling guidelines, or genuine disagreement on hard examples. During training, the Loss Function treats every label as ground truth. So when the label is wrong, gradient descent pulls the decision boundary toward the mistake with the same force it applies to a correct example. The model assigns high probability to the wrong answer not because it failed, but because it succeeded at fitting bad supervision.
The damage compounds in two ways. First, noisy labels near the decision boundary distort that boundary the most, because boundary examples carry the most gradient signal. Second, a high-capacity model will eventually memorize the noise outright — an extreme form of Overfitting where the network learns specific wrong answers rather than the general pattern. The symptom in the wild is a model that trains to suspiciously low loss yet generalizes poorly, with errors clustered on the classes whose labeling guidelines were fuzziest.
The useful question is which labels to distrust. Confident Learning offers a principled answer. Introduced by Northcutt, Jiang, and Chuang in the Journal of Artificial Intelligence Research (JAIR Vol. 70, published April 2021), it estimates the joint distribution between the noisy labels you have and the true labels you wish you had, assuming class-conditional noise. From that estimate it can prune likely errors, count them per class, and rank examples by how suspect they are. The open-source Cleanlab package implements this approach to detect label errors, outliers, and duplicates; the current release is version 2.9.0 (January 2026), requiring Python 3.10 or newer (cleanlab PyPI).
Imbalance and Shift: When the Distribution Itself Is the Problem
Label noise corrupts individual examples. The other two failures are properties of the dataset as a whole — and they are easy to miss because aggregate metrics paper over them.
Class imbalance is the simplest to state and the easiest to misdiagnose. When one class dominates, a model can reach high overall accuracy by predicting the majority and effectively ignoring the minority. A fraud detector that sees fraud in a tiny fraction of transactions can score extremely well on accuracy while catching almost nothing that matters. The skew biases the learned decision boundary toward the frequent class because that is where most of the loss reduction lives.
Distribution shift is the subtler cousin. It is the gap between the distribution a model trained on and the distribution it meets in production. The literature splits it into types worth recognizing: covariate shift, where the input distribution changes but the labeling rule stays the same; label shift, where class proportions change; and concept shift, where the relationship between inputs and labels itself drifts (arXiv DCAI survey). A model that was accurate at training time can degrade silently as the world it operates in moves away from the data it remembers.
What metrics measure the quality of a training dataset?
There is no single number for dataset quality, which is exactly why the three concepts matter — each is measured differently.
For class balance, look past raw accuracy. The Confusion Matrix and per-class Precision, Recall, and F1 Score reveal whether the minority class is actually being learned or quietly abandoned. For label noise, the relevant metric is an estimated label-error rate — the fraction of examples confident learning flags as likely mislabeled, often broken down per class to expose which guidelines failed. For distribution shift, you measure the distance between training and deployment distributions: divergence statistics on feature distributions, or the accuracy of a classifier trained to tell training data apart from production data. If that discriminator does its job easily, your two distributions are not the same.
Two practices feed these measurements. Data deduplication keeps duplicate examples from leaking across train and test splits and inflating your scores, and data provenance lets you attribute a spike in label-error rate to the batch, vendor, or guideline revision that produced it.
What the Three Lenses Predict
The value of naming these failures is that each one makes a falsifiable prediction about how your model will behave. Understanding becomes active when you can anticipate the symptom.
- If your label-error rate is concentrated in a few classes, expect those classes to show the worst per-class recall — and expect a bigger model to memorize the errors rather than fix them.
- If you have heavy class imbalance, expect high overall accuracy alongside near-zero recall on the minority class. The metric that looks good is the wrong metric.
- If a discriminator can easily separate training data from production data, expect accuracy to decay after deployment even though validation looked fine — that is distribution shift cashing in.
The order of operations matters too. Cleaning labels before you have measured imbalance can waste effort on a majority class the model already handles. Curating for diversity before you have deduplicated can leave hidden train/test leakage in place. Diagnose first, then intervene.
Rule of thumb: measure all three failures before changing the model — the cheapest accuracy gains usually live in the data, not the architecture.
When it breaks: limits of confident-learning estimates assume class-conditional noise — that label errors depend on the class, not on the specific features of an example. When noise is heavily feature-dependent (annotators systematically mislabel one visual style, say), the joint-distribution estimate weakens, and flagged errors should be treated as candidates for human review rather than automatic deletions.
The Tooling Follows the Diagnosis
Once you know which failure you have, the tools become obvious rather than fashionable. For programmatic labeling at scale, weak supervision expresses noisy heuristics as labeling functions that vote on probabilistic labels; the Snorkel project is the reference implementation of that idea. For deciding which images are worth labeling next, embedding-based active-learning curation selects diverse, informative examples instead of random ones, which is the approach the Lightly ecosystem takes for computer vision (Lightly Docs).
Tooling status notes:
- Snorkel (open source): The OSS
snorkellibrary is best treated as the canonical reference for the weak-supervision concept, not an actively evolving flagship — the team’s active development moved to the commercial Snorkel Flow platform, whose latest LTS release carries breaking SDK changes (Snorkel AI). The OSS package requires Python 3.11+.- Lightly: LightlyOne is now legacy, superseded by LightlyStudio as of March 2026 (Lightly). LightlyOne remains supported for a transition period, but new work should target the successor.
The Data Says
Label noise, class imbalance, and distribution shift are not advanced topics — they are the prerequisites. A model trained on quietly mislabeled, skewed, or stale data will plateau no matter how large the backbone. The leverage is in diagnosing which of the three you have, measuring it with the right per-class metric, and only then reaching for a tool. The architecture is rarely the thing holding you back.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors