Label Noise, Annotator Bias, and the Technical Limits of Human Data Annotation
ELI5
Data labeling attaches a correct answer to each training example. But humans disagree and make mistakes, so every dataset carries label noise — wrong answers in the answer key that models learn as if they were truth.
In 2021, a group of researchers did something quietly subversive: they audited the answer keys of the most famous benchmarks in machine learning. On ImageNet’s validation set they found an estimated 2,916 mislabeled images — roughly 6% of the set (Northcutt et al., 2021). The unsettling part was not the count. It was what those errors did to the leaderboard. Once you correct enough of the mistakes, a smaller model can outrank a larger one that supposedly beat it.
That should not be possible if the test set is telling the truth. The fact that it happens tells you something uncomfortable about the foundation the entire field stands on.
When the Answer Key Is Wrong
We call the labels in a dataset Ground Truth, and the name does a lot of quiet work. It implies the labels are the floor reality rests on — fixed, correct, beyond dispute. They are not. Every label is the residue of a human judgment made under time pressure, often by a crowdworker paid by the task, and judgment leaves fingerprints. The practice of Data Labeling And Annotation is where those fingerprints get pressed permanently into the dataset.
Ground truth is a convenient fiction.
How does label noise degrade supervised model performance?
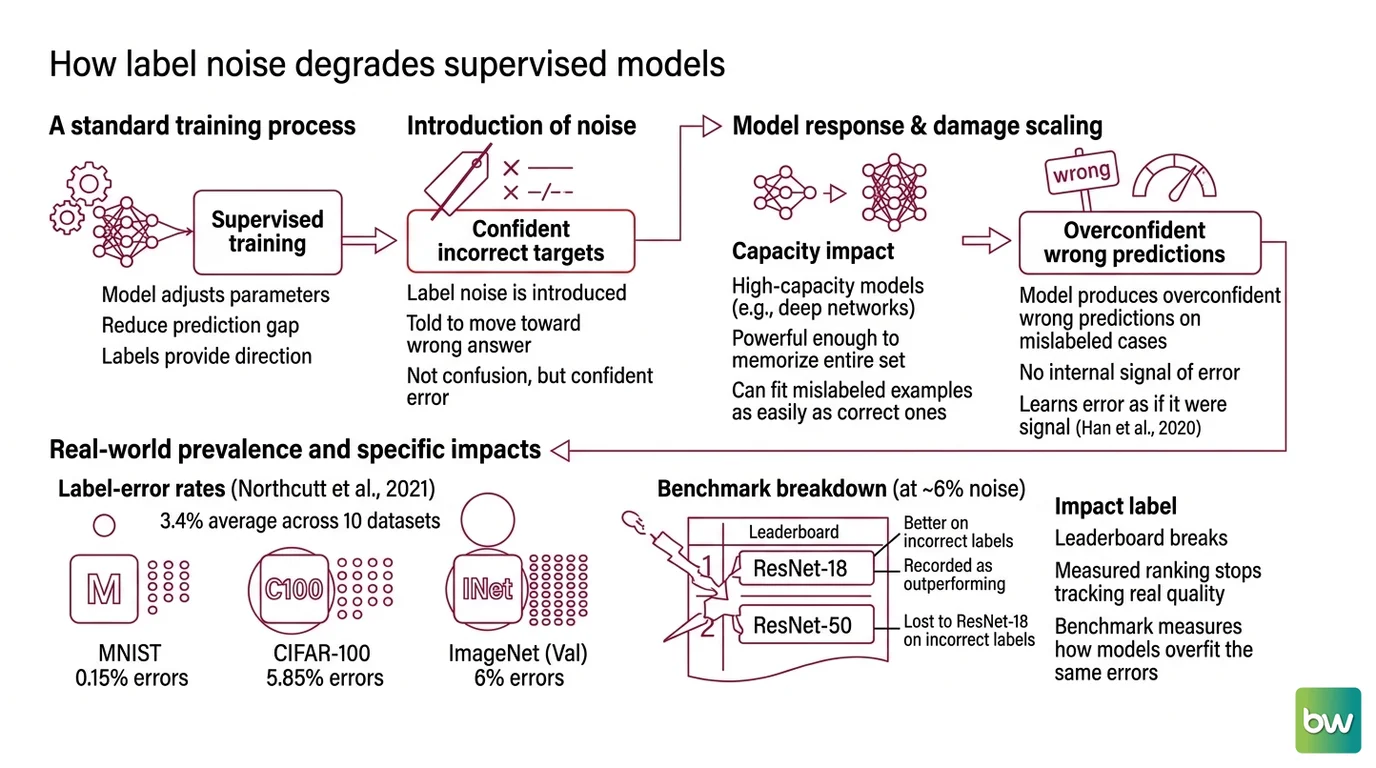
A supervised model has exactly one job during training: adjust its parameters to reduce the gap between its predictions and the labels it is shown. The labels define the direction of every gradient step. So when a label is wrong, the model is not confused — it is being told, with full authority, to move toward the wrong answer. Label Noise does not corrupt the model by adding randomness. It corrupts the model by supplying confident, incorrect targets.
The damage scales with two things: how much noise there is, and how much capacity the model has to absorb it. High-capacity deep networks are powerful enough to memorize their training set outright, which means they can fit the mislabeled examples as readily as the correct ones. The result is a model that produces overconfident wrong predictions on exactly the cases the labels got wrong, with no internal signal that anything is amiss (Han et al., 2020). The model learns the error as if it were signal.
How much noise are we talking about? Across ten widely used ML test sets, the average label-error rate sits around 3.4% — an estimate from confident-learning methods cross-checked by crowd validation, not an exact census (Northcutt et al., 2021). The spread between datasets is wide. MNIST, small and heavily scrubbed, holds only about 0.15% errors (15 images). CIFAR-100 carries an estimated 5.85% (585 images), and ImageNet’s validation set lands near 6%.
That last number is where the leaderboard breaks. Once mislabeled-test prevalence climbs to around 6%, the measured ranking of models stops tracking their real quality: a ResNet-18 can be recorded as outperforming a ResNet-50 it would lose to on correct labels (Northcutt et al., 2021). The benchmark is no longer measuring the models. It is measuring how well each model happened to overfit the same errors the test set contains.
One caveat keeps this from becoming a doom story. Deep networks can stay accurate under surprisingly heavy noise — but only under specific conditions: the noise has to be roughly symmetric (errors scattered evenly across classes), and the model needs abundant clean data and large batches to average the noise out (Rolnick et al., 2017). Real annotation noise rarely cooperates. It is systematic, not symmetric, because the same ambiguous cases trip up annotators in the same direction. Robustness to random noise tells you little about robustness to bias.
The Limits of Counting Heads
If a single annotator is fallible, the obvious fix is to use several and measure how often they agree. That measurement has a name — Inter Annotator Agreement — and a small toolkit of statistics behind it. Cohen’s kappa handles the two-annotator, categorical case and corrects for the agreement you would expect by chance alone. Krippendorff’s alpha generalizes to any number of annotators, to ordinal and interval data, and tolerates the missing labels that real annotation projects always produce. Both ask the same underlying question: is this consensus real, or would coin-flips have looked similar?
Why is inter-annotator disagreement hard to eliminate on subjective tasks?
The comforting assumption is that disagreement is error — that with clearer guidelines and better training, annotators would converge on the one right answer. For objective tasks, that mostly holds. For subjective ones, it collapses.
When researchers studied annotators labeling toxic language, they found that an annotator’s own beliefs and identity measurably shifted which posts they flagged. The disagreement was not scattered randomly across the labeling pool — it correlated with who the annotators were (Sap et al., 2022). That is the crucial distinction.
Not random error. Structured disagreement.
If two people disagree because one was careless, more training fixes it. But if they disagree because “toxic” genuinely means different things to a 22-year-old and a 60-year-old, to an insider and an outsider to the targeted group, then no amount of guideline-tightening makes the gap close. You are not measuring annotator competence. You are measuring a real distribution of human interpretation, and the disagreement is partly structured, not random noise.
This is also where the standard interpretation grid starts to mislead. A common heuristic treats a kappa of 0.61–0.80 as “substantial” agreement and 0.41–0.60 as merely “moderate” (Landis & Koch, 1977). Those cutoffs are conventions, not statistical law, and modern guidance warns they are too rigid for subjective work (Counting on Consensus). A kappa of 0.5 on a sentiment task may not signal a broken annotation process. It may be honestly reporting that the task itself has no single answer.
What Noisy Labels Predict About Your Model
The mechanism is not just a description — it makes predictions you can check against your own pipeline. Once you accept that labels carry both random error and structured bias, several consequences follow directly.
- If your held-out test set was drawn and labeled the same way as your training set, both share the same errors — so your reported accuracy is inflated, and the inflation is largest on exactly the ambiguous cases you most need to get right.
- If two annotators agree only moderately on a task, expect a model trained on the single aggregated label to behave overconfidently, picking one interpretation and suppressing the legitimate alternative the disagreement encoded.
- If you clean naively — running Data Deduplication to remove near-duplicates — you may also be amplifying a single label error, because one mislabeled example copied across the set quietly multiplies its gradient pull.
This is why Training Data Quality work increasingly targets the labels themselves, not just the volume of data. Confident-learning tools can flag the examples most likely to be mislabeled, and Active Learning can route the genuinely ambiguous cases — the ones annotators split on — to additional review instead of burying them under a majority vote.
Rule of thumb: measure inter-annotator agreement before you trust any accuracy number, because a metric computed against noisy labels inherits that noise twice — once in training, once in evaluation.
When it breaks: the entire approach assumes a single correct label exists to converge on. On genuinely subjective tasks, forcing annotators into one gold label does not reduce error — it discards the minority interpretations that were never wrong, and the model inherits whichever view the aggregation rule happened to favor.
When Disagreement Is the Data
There is a quieter shift happening underneath the statistics. The traditional view treats annotator disagreement as noise to be aggregated away into one authoritative label. A competing view — sometimes called perspectivist — argues that for subjective tasks, the disagreement is the most honest part of the dataset, and collapsing it into a single gold label suppresses legitimate minority perspectives (Aroyo & Welty, 2015).
This is an open research direction, not a settled consensus, and it is worth holding both views at once. Sometimes low agreement really does mean a sloppy annotation process that better instructions would fix. Sometimes it means the question has no single answer and the dataset is quietly recording a real divergence in human judgment. The hard engineering problem is telling those two cases apart — because they look identical in a kappa score.
The Data Says
Label noise is not an edge case; it is a measurable, estimated baseline of a few percent in the cleanest public benchmarks and considerably more in messier ones, and it is large enough to scramble model rankings. The deeper limit is structural: on subjective tasks, some disagreement is not error to be eliminated but signal to be preserved. Treating every label as ground truth is the most expensive assumption in the pipeline.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors