KV-Cache, PagedAttention, and the Building Blocks Every LLM Inference Pipeline Needs
Table of Contents
ELI5
An LLM inference pipeline turns a trained model into a responsive service by managing memory, scheduling requests, and optimizing the token-by-token generation loop that produces every response.
A 70-billion-parameter model can draft legal briefs, summarize research papers, generate working code. But most of the time it spends producing those outputs isn’t consumed by anything resembling reasoning. It’s consumed by re-reading what it already wrote. Every new token requires attending to every previous token, and the cost of that backward glance grows with every word generated.
Strip away the marketing language around “AI acceleration,” and the entire optimization stack for serving LLMs reduces to a surprisingly old problem: memory management. The techniques that determine whether your chatbot responds in 200 milliseconds or 2 seconds are the same mechanisms operating systems have used to manage RAM since the 1960s — pages, caches, scheduling. The substrate changed. The computer science didn’t.
The Repetition Tax Inside Autoregressive Generation
Every transformer-based language model generates text the same way: one token at a time, each conditioned on everything that came before. This is autoregressive generation, and it carries a computational cost that most users never see but every serving engineer measures daily.
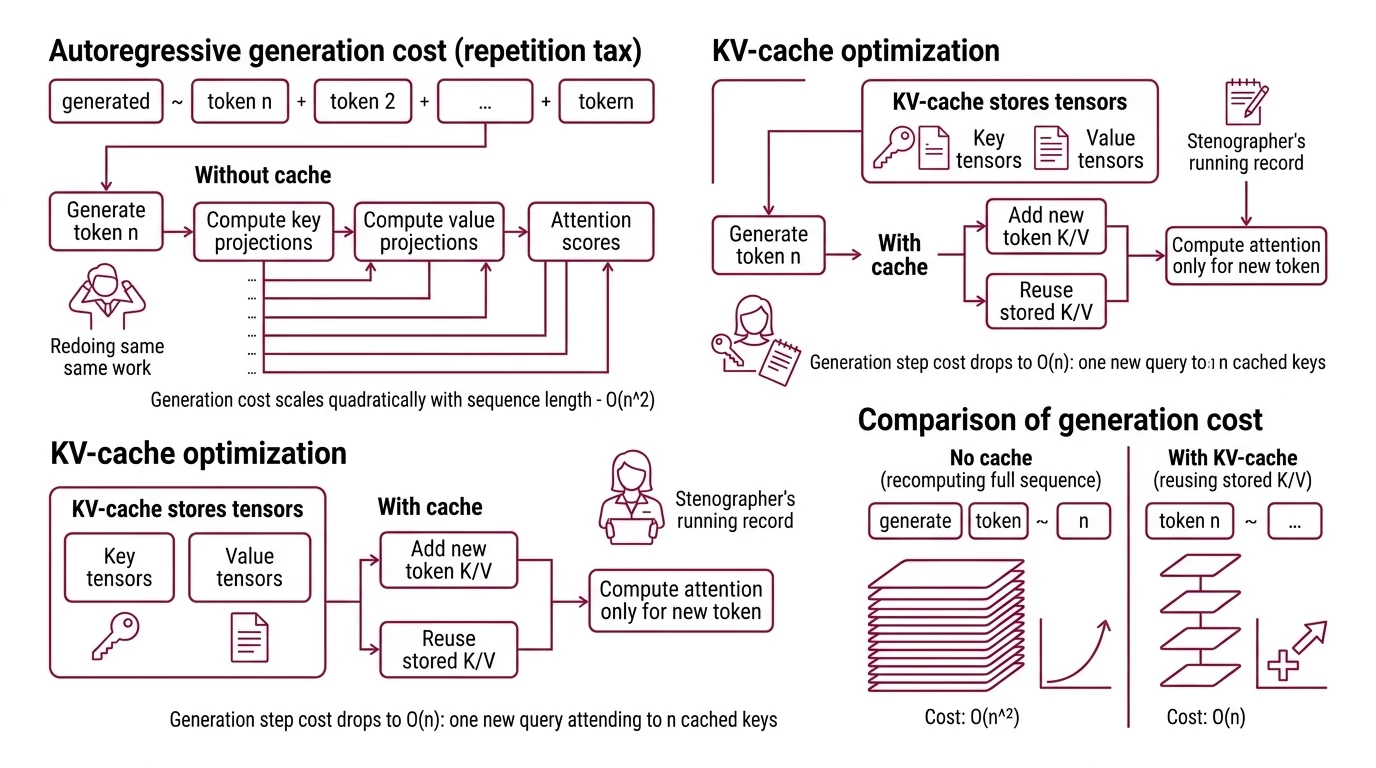
The cost hides inside the attention mechanism. To produce token n, the model computes attention scores between that token’s query vector and the key vectors of all n-1 preceding tokens — then weights the corresponding value vectors. Without intervention, this means recomputing the key and value projections for every previous token, at every attention layer, for every new token generated.
That’s the repetition tax.
And it’s the reason the first optimization in any Inference pipeline isn’t a clever algorithm — it’s a cache.
What is KV-cache and how does it accelerate autoregressive text generation?
The KV-cache stores the computed key and value tensors from every previous token at every attention layer. Instead of recomputing these projections across the full sequence each time the model generates a new token, the cache appends only the new token’s K/V pair and reuses everything already stored.
The arithmetic is clean. Without the cache, generation cost scales quadratically with sequence length — O(n^2) — because each new token recomputes attention over all predecessors. With the cache, each generation step drops to O(n): one new query attending to n cached keys. For a 4,096-token response, that’s the difference between recomputing thousands of projections per step and computing exactly one.
Think of a court stenographer. Without notes, you’d need to replay the entire trial transcript before asking each new question. The KV-cache is the stenographer’s running record — always current, always accessible, growing one line at a time.
But the cache creates a new problem. Each attention layer stores key and value tensors for every token in the sequence. For large models running at half precision, a single request with a long context can consume gigabytes of GPU memory. Multiply by concurrent users, and the cache — not the model weights — becomes the binding constraint on serving concurrency.
What are the key components of an LLM inference pipeline?
An inference pipeline sits between a trained model and the user. Its job is to make generation fast, cheap, and concurrent. The core components form a stack, and each one addresses a different bottleneck:
Prefill processes the entire input prompt in parallel — a single forward pass that populates the KV-cache for all input tokens at once. This is the compute-heavy phase, and it determines your Time To First Token.
Decode generates output tokens autoregressively, one at a time, reading from the KV-cache. This is the memory-bandwidth-bound phase — its speed depends on how fast the GPU can read cached tensors, not on how fast it can multiply matrices.
Batching groups multiple requests to fill GPU cycles that would otherwise idle between decode steps. Static batching waits until a full batch accumulates; continuous batching — introduced by Orca (Yu et al.) — inserts new requests at the iteration level the moment a slot opens, achieving dramatically higher throughput.
Memory management for the KV-cache determines how many concurrent sequences the GPU can hold. Naive allocation reserves maximum-sequence-length memory per request; Paged Attention virtualizes this allocation.
Speculative Decoding uses a small draft model to propose multiple tokens, then verifies them against the large model in a single forward pass — reducing latency by 2-3x while preserving the exact output distribution (Google Research).
Quantization reduces the numerical precision of model weights and activations — FP16 to INT8 to INT4 — trading marginal accuracy for substantial memory and compute savings.
Not a single intelligence breakthrough in the list. Memory management, scheduling, and compression — the same toolkit systems engineers have refined for decades, applied to a new kind of workload.
Virtual Memory for Attention Weights
The KV-cache solves the recomputation problem but immediately introduces a memory allocation problem. Sequences vary in length — some finish in 50 tokens, others run to 8,000 — and the GPU cannot know in advance how long each will be. The naive approach: allocate maximum-length memory for every request, regardless of actual usage.
The waste is substantial. Kwon et al. measured it: the majority of allocated KV-cache memory in existing systems sat unused at any given moment because sequences rarely consumed their maximum allocation. GPU memory — the most expensive resource in the serving stack — reserved but idle.
What do you need to understand before optimizing model inference?
Before reaching for any optimization framework, three mental models separate productive tuning from cargo-cult configuration.
First: inference is two phases with opposing bottlenecks. Prefill is compute-bound — large matrix multiplications over the full input. Decode is memory-bandwidth-bound — reading KV-cache entries for each new token. Optimizing one phase can actively hurt the other. This is why SGLang’s prefill-decode disaggregation separates them onto different hardware; they compete for different resources when forced to share.
Second: the KV-cache is the binding constraint on concurrency. Model weights are static and shared across all requests. The KV-cache is dynamic and per-request. If your GPU has a fixed memory budget, your weights consume a fixed portion, and whatever remains is your KV-cache ceiling. That ceiling — not your compute throughput — determines how many concurrent long-context requests you can serve.
Third: memory fragmentation destroys throughput before memory capacity does. This is the central insight behind PagedAttention (Kwon et al.). Instead of allocating a contiguous memory block per sequence, PagedAttention borrows the operating system’s virtual memory paradigm: it divides the KV-cache into fixed-size blocks — pages — maps them through a block table, and allocates pages on demand as sequences grow. Fragmentation drops to near zero. The result: 2-4x throughput improvement over prior systems like FasterTransformer and Orca.
The analogy is exact, not decorative. Traditional KV-cache allocation behaves like a filing cabinet where you reserve an entire drawer per folder, even when the folder holds three pages. PagedAttention treats the same cabinet like a paged memory system: one slot at a time, allocated as needed, reclaimed the moment the sequence finishes. The virtual memory abstraction that solved RAM fragmentation in the 1960s now solves GPU memory fragmentation for attention weights.
The Arithmetic That Determines Your Latency Budget
Cache the keys and values, page the memory, batch at iteration level, speculate where possible. The mechanisms are clear. But how do you know whether your optimizations are working? Three metrics define inference performance, and confusing them is the fastest way to optimize the wrong variable.
What is the difference between inference latency, throughput, and time to first token?
Time to First Token (TTFT) measures the delay from request submission to the first output token arriving: queuing time plus prefill computation plus network latency. For chatbots, the target sits below 500 ms; for code completion, below 100 ms (BentoML Handbook). TTFT is dominated by prefill cost — longer input prompts mean longer waits, regardless of how fast your decode loop runs.
Time Per Output Token (TPOT) measures the interval between consecutive output tokens after the first. The formula: TPOT = (end-to-end latency - TTFT) / (output tokens - 1). This is the decode-phase metric, bounded by memory bandwidth — how fast the GPU reads the KV-cache per step.
Throughput measures total tokens generated per second across all concurrent requests. The optimization levers here are batching — more requests per GPU cycle — and memory efficiency — more concurrent sequences before the KV-cache overflows.
The trap is subtle: optimizing TTFT and optimizing throughput pull in opposite directions. Lower TTFT favors dedicating GPU compute to one request’s prefill phase; higher throughput favors packing as many decode steps as possible into each cycle. Modern engines like vLLM and SGLang implement prefill-decode disaggregation precisely because these two objectives fight for the same silicon when forced to coexist.
As of March 2026, the open-source engine landscape reflects this tension. vLLM v0.18.0 ships with FlashAttention 4 and gRPC serving; SGLang v0.5.9 achieves approximately 16,200 tokens per second on H100 hardware through RadixAttention and prefill-decode separation (SGLang GitHub). TensorRT-LLM v1.2 defaults to a PyTorch backend with in-flight batching and supports speculative decoding variants including Eagle3 and Medusa. On the hardware side, Groq built an SRAM-based LPU with deterministic execution — no HBM, no memory hierarchy unpredictability — though the company was acquired by NVIDIA in December 2025 (CNBC), and the Groq 3 chip announced at GTC March 2026 with claimed 150 TB/s SRAM bandwidth is pre-release hardware shipping Q3 2026; those numbers are manufacturer claims, not independently benchmarked.
Rule of thumb: If users complain about perceived slowness, measure TTFT first. If the finance team complains about GPU cost, measure throughput first. They are rarely the same problem.
When it breaks: KV-cache memory becomes the hard ceiling. Once the cache fills GPU memory, new requests queue regardless of available compute. Long-context models — 32K tokens and beyond — hit this wall earliest, and no amount of batching or speculative decoding solves a memory capacity constraint. The only exits are quantization, offloading to CPU memory with corresponding latency penalties, or adding GPUs.
Security & compatibility notes:
- vLLM V0 engine (BREAKING): The legacy V0 engine is deprecated; code removal is scheduled for end of June 2026. V0 was last supported in v0.9. Migrate to the V1 engine before upgrading past that version (vLLM GitHub).
- TensorRT-LLM IPC vulnerability (CVSS 8.8): A pickle deserialization flaw (CVE-2025-23254) in all versions before 0.18.2 enables arbitrary code execution through IPC channels. HMAC authentication is now default. Fix: upgrade to v0.18.2+ (NVIDIA Security).
- Groq acquisition: Groq was acquired by NVIDIA in December 2025 (CNBC). The LPU is no longer an independent platform; future development falls under NVIDIA’s ecosystem roadmap.
The Data Says
LLM inference optimization is memory management applied to a new substrate. The KV-cache eliminates redundant computation but creates a memory capacity problem; PagedAttention solves fragmentation with virtual memory techniques that predate neural networks by half a century; continuous batching fills idle GPU cycles; speculative decoding attacks the serial nature of autoregressive generation itself. Each optimization shifts the bottleneck rather than removing it. The discipline — and the difficulty — lies in knowing which metric to watch, because TTFT, TPOT, and throughput rarely improve from the same intervention.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors