Intrinsic vs. Extrinsic, Closed vs. Open Domain: The Taxonomy and Prerequisites of LLM Hallucination
Table of Contents
ELI5
LLM hallucination comes in distinct types — some contradict given sources, others invent unsupported facts. Understanding the taxonomy is prerequisite to fixing any of them.
A language model summarizes a medical paper and states the opposite of what the abstract says. A different model, given no source material at all, fabricates a citation that looks real, sounds authoritative, and leads nowhere. Both failures get the same label: Hallucination.
That single word is doing too much work.
Four Failure Modes Hiding Behind One Word
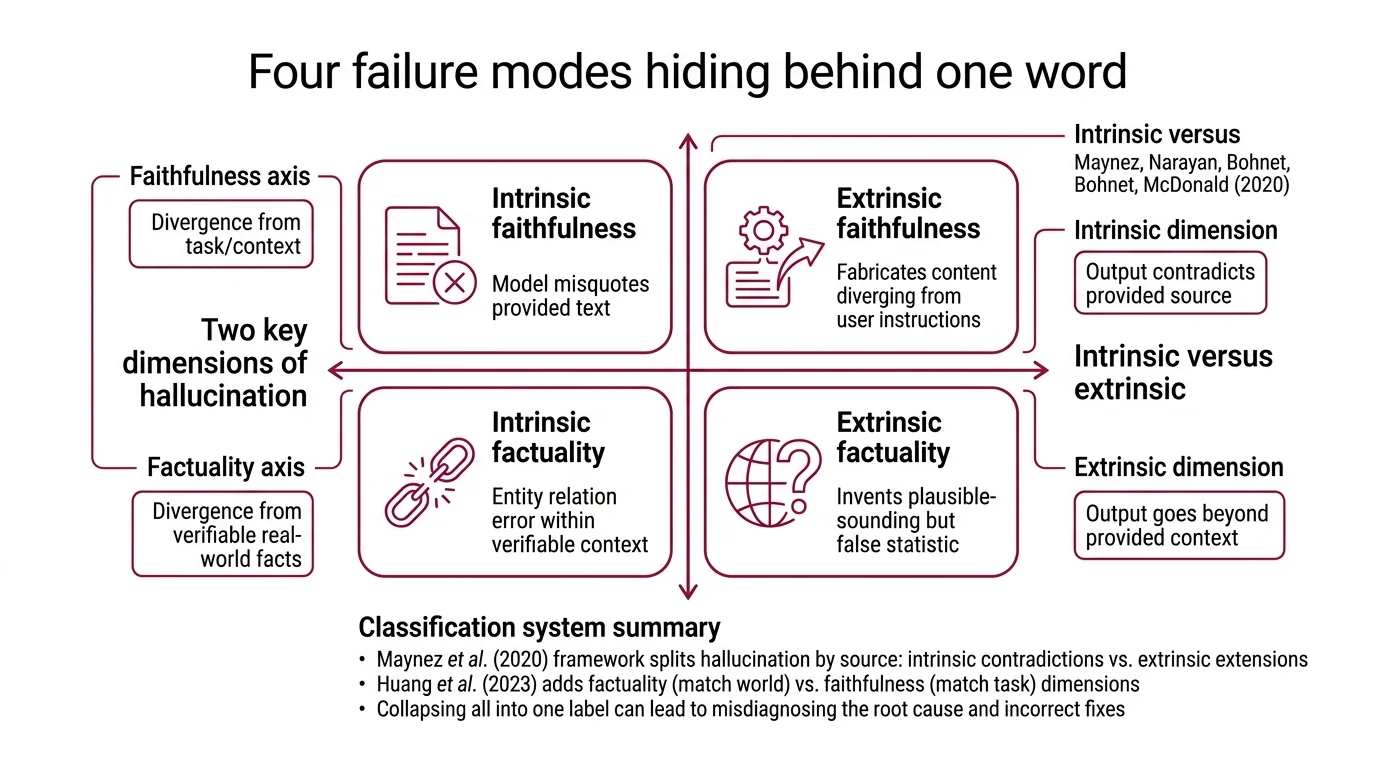
The instinct is to treat hallucination as binary — the model either got it right or it didn’t. But the taxonomy that emerged from summarization research in 2020, and has since been extended across LLM generation, reveals something more structured. Two independent axes define at least four distinct failure modes, and collapsing them into a single category is the fastest way to misdiagnose the cause.
What are the different types of AI hallucination
The most widely adopted framework splits hallucination along two dimensions.
The first comes from Maynez, Narayan, Bohnet, and McDonald, who in 2020 drew a line between outputs that contradict a source and outputs that go beyond it (Maynez et al.). That distinction — intrinsic versus extrinsic — originated in abstractive summarization rather than open-ended generation, but it has become the load-bearing classification in hallucination research. Its extension to general LLM output is widely adopted, though not universally agreed upon.
The second dimension, introduced by Huang et al. in their survey of hallucination principles, separates factuality hallucination from faithfulness hallucination. Factuality hallucination is a divergence between generated content and verifiable real-world facts — encompassing entity errors, relation errors, and outright fabrication (Huang et al. Survey). Faithfulness hallucination is a divergence from user instructions, provided context, or the model’s own internal logical consistency. Factuality asks: does this match the world? Faithfulness asks: does this match the task?
Cross these two axes and the classification sharpens. A model that misquotes a provided document is committing an intrinsic faithfulness error. A model that invents a plausible-sounding statistic about the world is committing an extrinsic factuality error. Same label — entirely different mechanisms and fixes.
Then there is the domain split. In closed-domain tasks — summarization, document QA, extraction from a provided context — the source material creates a verifiable boundary. Hallucination can be measured against that boundary with reasonable confidence. In open-domain generation — creative writing, open-ended conversation, reasoning from parametric knowledge — no single source exists, and “hallucination” becomes entangled with the harder problem of what counts as ground truth at all. The closed-versus-open-domain framing is used widely but informally across the literature; it emerges from task structure rather than from any single canonical paper (Huang et al. Survey).
What is the difference between intrinsic and extrinsic hallucination in LLMs
Intrinsic hallucination occurs when the model’s output directly contradicts information present in the source input — it misrepresents what was given (Maynez et al.). The source says the trial enrolled 200 patients; the summary says 2,000. The mechanism is typically attention misalignment or copying failure during generation.
Extrinsic hallucination occurs when the model introduces information that is neither supported nor contradicted by the source — it cannot be verified from the input at all (Maynez et al.). The summary adds a claim about long-term outcomes that the original paper never mentioned. The information might be true, might be false; the defining feature is that the source cannot tell you which.
The practical difference matters because the mitigation strategies diverge sharply. Intrinsic hallucinations are often addressable through better Grounding — forcing the model to attend more faithfully to the provided context. Extrinsic hallucinations require a different class of intervention: either constraining the model’s generation to source-supported claims, or introducing external verification through Retrieval Augmented Generation pipelines. Self-reflective RAG architectures have achieved hallucination rates as low as 5.8% in clinical settings (MDPI Review), but only for the subset of hallucinations that RAG can catch — primarily the extrinsic kind, where missing knowledge is the root cause.
Intrinsic hallucination is detectable by comparing output to input. Extrinsic hallucination requires external knowledge to identify. That asymmetry determines which tools you reach for.
The Invisible Dependencies
Understanding the taxonomy is necessary but not sufficient. Hallucination research sits at an intersection of concepts that are often studied in isolation — and misunderstanding any one of them distorts the entire picture.
What do you need to understand before studying LLM hallucination
Three concepts form the prerequisite layer, and each one reframes what hallucination actually is.
The first is Knowledge Cutoff. A model cannot know what it was never trained on. Every fact that postdates the training cutoff is, from the model’s perspective, a gap in the world — and the model has no internal mechanism to distinguish “I don’t know this” from “this doesn’t exist.” The result is confabulation that sounds authoritative because the model treats its own silence as absence of evidence rather than evidence of absence.
The second is Calibration — whether the model’s confidence tracks its accuracy. A well-calibrated model assigns high probability to correct answers and low probability to uncertain ones. But Kalai and Vempala proved something uncomfortable at STOC 2024: calibrated language models must hallucinate. The hallucination rate is bounded below by the fraction of facts appearing exactly once in the training data — the Good-Turing estimate (Kalai & Vempala).
That result deserves to sit with you for a moment.
It means that calibration and zero hallucination cannot coexist under current architectures. You can have a model that knows when it’s uncertain, or a model that never fabricates — but the mathematics says you cannot have both without architectural changes that go beyond prompting and fine-tuning. This is not a bug awaiting a patch. It is a statistical consequence of learning from finite data with a calibrated probability distribution.
The third prerequisite is grounding itself — the practice of connecting the model to external reality. RAG pipelines, tool use, and retrieval-augmented verification all serve the same purpose: providing the model with information it cannot access from its parameters alone. Grounding doesn’t eliminate hallucination. A model can still misinterpret retrieved documents (intrinsic error) or generate beyond what the retrieved context supports (extrinsic error). But grounding changes the problem from “the model doesn’t know” to “the model doesn’t read carefully” — a failure mode with more tractable engineering solutions.
What the Classification Predicts — and Where It Collapses
The taxonomy is not decorative. It generates testable predictions about which interventions work where.
If your hallucination is intrinsic and faithfulness-related — the model contradicts the provided context — then improving attention over the source document should help. Constrained decoding, span-level verification, and grounding techniques target this class directly.
If your hallucination is extrinsic and factuality-related — the model invents facts about the world — then the intervention must come from outside the model’s parametric knowledge. RAG, tool use, and post-generation fact-checking attack this class. Chain-of-thought prompting reduces hallucination in 86.4% of tested comparisons after FDR correction (ACL Findings 2025), but with an important caveat: it simultaneously obscures the cues that humans and automated systems use to detect remaining hallucinations. The intervention helps — and makes the survivors harder to find.
If your task is open-domain with no retrievable ground truth, the taxonomy starts to strain. What counts as hallucination in creative writing? In speculative reasoning? The closed-versus-open-domain axis reveals not just a category boundary but the limit of the classification itself.
Rule of thumb: Before choosing a mitigation strategy, identify which quadrant of the taxonomy your failure occupies. Grounding fixes and retrieval fixes are not interchangeable — applying the wrong one wastes compute and creates false confidence.
When it breaks: The taxonomy assumes hallucinations can be classified cleanly into one cell. In practice, a single generated passage can contain both intrinsic and extrinsic errors simultaneously, and the boundary between “contradicts the source” and “goes beyond the source” depends on how narrowly you define the source. The classification is a useful diagnostic map, not a precision instrument.
One more pressure point worth noting: hallucination benchmarks are themselves degrading. TruthfulQA, once the standard evaluation, is now saturated — models trained on its questions can score high without genuine truthfulness. HaluEval suffers from a length-bias exploit that allows high accuracy by simply flagging answers above a character threshold. HalluLens, introduced at ACL 2025, is designed to address these weaknesses, but its adoption is still early.
The tools for measuring the problem are shifting underneath the problem itself.
The Data Says
Hallucination is not one failure. It is at least four, distributed across two independent axes — and the mitigation that works for one quadrant may be irrelevant for another. The prerequisite that reshapes the entire conversation is calibration: the mathematical proof that calibrated models cannot avoid hallucination entirely. The taxonomy tells you where to look. The impossibility result tells you what to stop expecting.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors