Inside Code LLMs: Fill-in-the-Middle and the Training Data Behind Them
ELI5
Fill-in-the-middle is a training trick that teaches a left-to-right code model to complete a gap by reading the code on both sides of your cursor. The model never sees the future — the future just gets moved into its past.
Put your cursor in the middle of a half-written function and ask your editor for a completion. It returns something that fits — code that closes a bracket you opened ten lines down, that calls a helper defined below the gap, that respects a return type the function signature hasn’t reached yet. A model that predicts text strictly left to right should not be able to do that. The information it needs lives in tokens it hasn’t read.
So how does a one-directional predictor condition on what comes next?
The Trick Is in the Data, Not the Architecture
The intuitive answer is that the model “reads the whole file like a person and figures out what belongs in the gap.” That mental model is wrong, and the way it’s wrong is the interesting part. Modern Code LLMs are built on a Decoder Only Architecture, which uses causal masking: during generation, each position can attend only to positions before it. A vanilla left-to-right model is architecturally forbidden from looking at future tokens. Nothing about infilling comes from the network suddenly gaining bidirectional sight.
Not a new architecture. A new data order.
How does fill-in-the-middle training work in code LLMs?
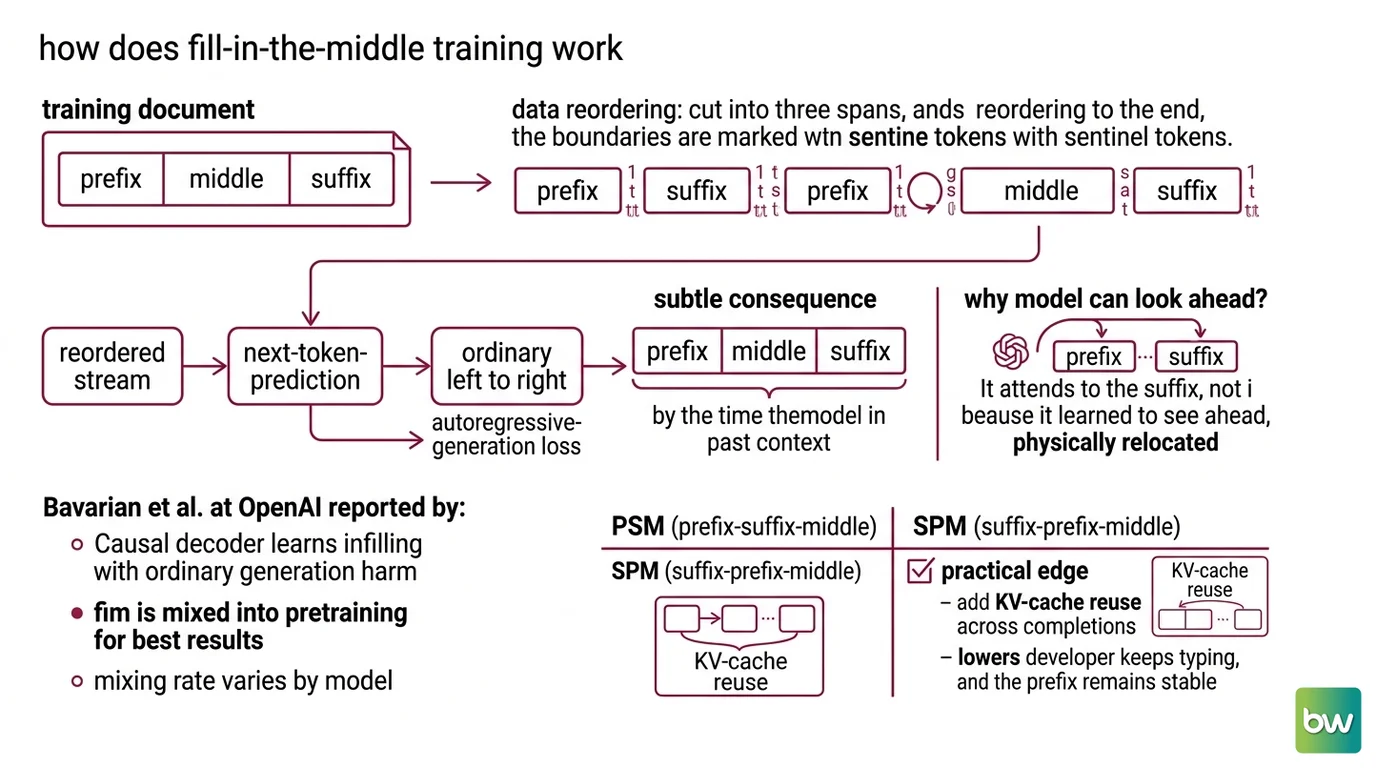
Fill-in-the-Middle (FIM) was formalized by Bavarian et al. at OpenAI in their July 2022 paper “Efficient Training of Language Models to Fill in the Middle.” The mechanism is almost embarrassingly simple. Take a training document, cut it into three contiguous spans — a prefix, a middle, and a suffix — and then reorder them so the middle moves to the end. Mark the boundaries with sentinel tokens, and the model now sees a sequence shaped like prefix, suffix, middle. The training objective never changes; it is still ordinary Next Token Prediction, the same Autoregressive Generation loss applied left to right over the reordered stream.
The consequence is subtle. By the time the model reaches the slot where it must generate the middle, both the prefix and the suffix already sit behind it in the context. It attends to the suffix not because it learned to see ahead, but because we physically relocated those tokens into its past. The model still only ever predicts the next token. We just changed which tokens count as “next.”
Bavarian et al. reported a result that matters for anyone building on these models: a causal decoder can learn this infilling capability without measurable harm to its ordinary left-to-right generation, provided FIM is mixed into pretraining rather than bolted on afterward. The exact mixing rate varies by model and is one of the details you should pull from a specific model’s paper rather than assume.
There are two common orderings. PSM (prefix-suffix-middle) and SPM (suffix-prefix-middle) differ in where the suffix lands relative to the prefix. SPM has a practical edge: it allows KV Cache reuse across completions, which lowers latency when a developer keeps typing and the prefix stays stable, as documented in the StarCoder 2 project’s implementation notes. The model never learned to read the future. We moved the future into its memory, then let an ordinary predictor do ordinary work.
What the Model Actually Eats
A training objective only matters if the data it runs over is any good. FIM explains how a code model completes a gap; it says nothing about why the completion is plausible Python rather than plausible nonsense. That comes from the corpus — its scale, its breadth, and crucially its provenance.
What training data is used to train code LLMs like StarCoder 2?
StarCoder 2, released by BigCode in February 2024, is the cleanest open worked example because its data pipeline is documented end to end. The family ships in three sizes — 3B, 7B, and 15B parameters — trained on roughly 3.3 to 4.3 trillion tokens, with the 15B model seeing north of 4 trillion, according to BigCode. The corpus, called The Stack v2, is built on the Software Heritage archive and spans 619 programming languages, roughly four times the size of the original StarCoder dataset, and it adds material that pure source files lack: GitHub pull requests, Kaggle notebooks, and code documentation.
That breadth is doing more work than the token count suggests. Pull requests teach the model what a change looks like — diff structure, review context, the relationship between a bug and its fix. Notebooks interleave prose, code, and output. Documentation pairs natural language intent with implementation. The model is not only learning syntax; it is learning the shapes of real software work.
Two details separate StarCoder 2 from a scraped pile of code. First, provenance: the dataset ships under an OpenRAIL license with full data lineage through Software Heritage persistent identifiers (SWHIDs), so any training example can be traced back to its origin — a transparency property most frontier models do not offer, per BigCode. Second, Data Deduplication: removing near-identical copies of the same file prevents the model from over-weighting boilerplate that happens to be replicated across thousands of repositories. The payoff shows up on benchmarks. BigCode reports that StarCoder2-15B matches or outperforms CodeLlama-34B — a model twice its size — on most evaluations. Data quality, not raw parameter count, closed that gap.
Why a 16k Window Changes What the Model Can Know
A single file rarely tells the whole story. The function you are completing imports from a sibling module, subclasses a base defined three files over, and obeys a type contract declared in a header you never opened. To complete code the way a human engineer would, the model needs to see across file boundaries — and that is a question of Context Window size and how attention is arranged within it.
StarCoder 2 uses a context window of 16,384 tokens, paired with Grouped Query Attention and a sliding-window attention span of 4,096 tokens, according to the StarCoder 2 model documentation. The long window was a deliberate choice for repository-level pretraining: BigCode concatenated related files from the same project so the model learns cross-file dependencies during training, not just within-file patterns. When the model later infills a function, the imports and helper definitions it needs can sit inside the same context — present, attendable, real. Repository-level context is the difference between a model that autocompletes a line and one that completes a function consistent with the rest of your codebase.
Where the Mechanism Stops Helping
Understanding the trick lets you predict its failure modes, which is more useful than any benchmark headline. The model conditions on local context; it does not verify the world that context refers to. That single fact predicts most of what goes wrong.
What are the technical limitations of code LLMs in 2026?
- If the suffix you give it is misleading or stale, the infilled middle will faithfully match the wrong constraints — the model has no notion that the suffix is “outdated,” only that it is context.
- If a plausible-looking library name fits the statistical pattern of an import, the model will emit it whether or not the package exists.
- If your code is in a language under-represented in the corpus, completion quality drops in proportion, regardless of how clever the FIM objective is.
That second case has a name and a measurement. Package hallucination — the model inventing dependencies that do not exist — runs high enough to be a supply-chain concern. Across studies, the share of invented package references reaches roughly 44.7% in some models, and around 19.7% of recommendations point to non-existent libraries, according to research on LLM package hallucination. Treat those as conditioned ranges, not universal constants: the rate depends heavily on the model, the language, and the task.
Security is the same story. Depending on task and model, somewhere between 12% and 65% of generated snippets have been flagged as non-compliant or carrying a known weakness, with many studies clustering in the 29–45% range for snippets containing vulnerabilities, per work on the security of LLM-generated code. The Hallucination is not a bug in one model; it is a property of generating from a probability distribution that was never grounded in an execution environment.
Rule of thumb: Trust a code model for shape and structure; verify every external reference — package names, API signatures, security-sensitive calls — against ground truth before you run it.
When it breaks: A code LLM has no execution feedback loop during generation. It produces the most probable continuation given its context, so confident, well-formatted output that imports a phantom package or reproduces an insecure pattern is not an anomaly — it is the objective working exactly as designed.
Why Benchmarks Read Better Than Reality
There is a gap between leaderboard numbers and the experience of using these models on a real repository, and the gap is structural. Current code benchmarks lack language diversity and under-reflect real-world workloads, and Benchmark Contamination — test problems leaking into training data — is a known risk that inflates reported scores, according to research on hallucinations in generated code. A model that aces HumanEval on short, self-contained functions may still founder on a multi-file change in a language the corpus barely covered.
This is also why ranking claims deserve hedging. As of mid-2026, agentic benchmarks like SWE Bench place frontier systems such as GPT-5.5 and Claude Opus 4.7 near the top, with open-weight families like DeepSeek V4 and Qwen3-Coder leading the open side — but the precise numbers come from aggregators that disagree with each other, so treat the ordering as directional rather than settled. StarCoder 2 remains a current, fully transparent open reference model even as newer coders post higher scores. The mechanism is stable; the rankings are weather.
The Data Says
Fill-in-the-middle is not a new kind of network — it is a reordering of training data that lets an ordinary autoregressive model condition on code after the cursor. What separates strong code models is less about architecture and more about corpus quality, provenance, and repository-level context, as StarCoder 2 demonstrates by matching a model twice its size. The persistent failure modes — package hallucination and insecure patterns — follow directly from generating without grounding, and no amount of FIM cleverness removes them.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors