Indexing Cost, Token Blowup, and the Hard Engineering Limits of GraphRAG at Scale
Table of Contents
ELI5
GraphRAG asks an LLM to extract entities and relations from your documents, then builds hierarchical community summaries on top. The graph reads beautifully — but indexing costs five to ten times the source tokens, and most variants rebuild from scratch when documents change.
Someone fed a 32,000-word book to Microsoft’s GraphRAG indexer and watched the bill climb to roughly six or seven dollars before the graph was finished. A different team scaled the same pipeline to a real enterprise corpus in early 2024 and paid around $33,000 to index it once (Graph Praxis). The indexer worked. The graph was elegant. The cost cliff is not a bug — it is the price of recursion meeting LLM token economics.
The Mechanics Behind the Cost Cliff
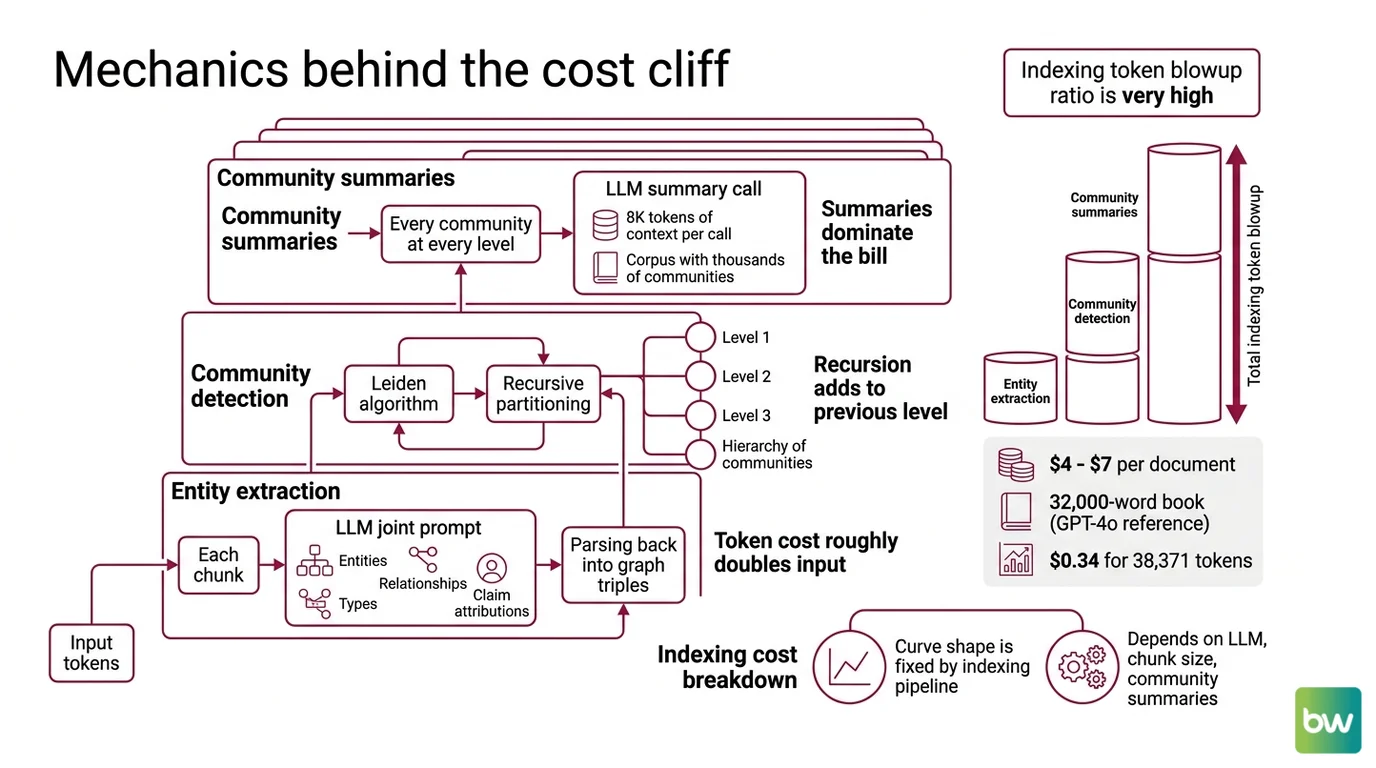
GraphRAG is not a vector index. It is a multi-pass LLM job that reads every chunk twice and writes summaries on top of summaries. To understand why the cost cliff exists, you have to follow the tokens through every layer of the build.
Why does Microsoft GraphRAG cost $4 to $7 per document to index and how does that constrain real deployments?
The widely cited reference figure is roughly six to seven dollars to index a 32,000-word book using GPT-4o (Maarga Systems). A smaller document tells the same story at smaller scale: 38,371 source tokens cost about $0.34 in a hand-instrumented run on the indexing pipeline (Khaled Alam on Medium). The number collapses or grows with document size, but the shape of the curve is fixed by the indexing pipeline itself.
The figure is widely cited but is not an official Microsoft benchmark. Exact cost depends heavily on the chosen LLM, chunk size, and whether community summaries are generated.
Three layers consume the tokens.
The first is Entity Extraction. Each chunk is fed to the LLM with a joint extraction prompt that asks for entities, types, relationships, and claim attributions in one shot. The output is parsed back into graph triples; token cost roughly doubles input on this pass alone.
The second is Community Detection — Microsoft GraphRAG uses the Leiden algorithm, applied recursively, to partition the graph into a hierarchy of communities (Microsoft GraphRAG concepts). Recursion is the operative word. Each level of the hierarchy is computed on top of the previous one.
The third is the community summary pass. Every community at every level is summarized by another LLM call; the original “From Local to Global” paper specifies 8K tokens of context per summary call (arXiv 2404.16130). On a corpus with thousands of communities, the summary layer alone can dominate the bill.
Stack the three layers together and the indexing token blowup ratio lands around five to ten times the source token count, by Microsoft’s own community-blog estimate (Microsoft Community Hub). The ratio is a rule of thumb — actual blowup scales with entity density and graph hierarchy depth — but it is the right order of magnitude for budgeting.
The constraint on real deployments is sharp. A hundred-thousand-document enterprise corpus is not a feature; it is a budget item that has to be approved before indexing starts. Update behaviour is brutal: adding new documents requires recomputing communities and rebuilding portions of the graph, which is a known pain point for dynamic corpora (Maarga Systems). And the cliff has produced its own market response. LazyGraphRAG indexes at roughly 0.1% of full GraphRAG cost by deferring summary generation until query time — a thousand times cheaper at indexing (Microsoft Research). LightRAG reports retrieval token counts under 100 per query versus GraphRAG’s roughly 610,000 per global query (Maarga Systems).
Not retrieval. Construction. The cost is paid up front, in tokens, before the user has asked a single question.
When the Graph Lies to You
Even when you can afford to build it, the graph isn’t necessarily faithful to the source. Auto-extraction is a probabilistic process, and probability sneaks errors into structures that look definitive on the page.
What are the technical limits of knowledge graph RAG: entity extraction errors, schema drift, and stale graphs?
The extraction prompt is the first failure surface. Microsoft’s default joint-extraction prompt asks the model to identify entities, types, and relationships simultaneously. That workload causes attention spread — the model under-allocates capacity to any single sub-task and quietly misses or mistypes entities that a more focused prompt would catch. Entity resolution is still primarily name-based, so two surface forms of the same entity often end up as two separate nodes (PremAI Blog).
The hallucinated-edge rate in auto-extracted Knowledge Graph structures is roughly 1.5 to 1.9% (Pebblous research blog). That ratio sounds small. On a graph with millions of edges it is the source of confident wrong answers — answers that a vector index would never have produced, because a vector index never claimed authority over the relationship in the first place. A hallucinating graph never looks hallucinated. It wears a clean schema with typed nodes and labelled relations.
Schema drift is the slower failure. The first thousand documents teach the extractor that “company” and “organization” are distinct types. The next ten thousand teach it that they are not. Re-indexing under the new convention silently produces a different graph for the same source text. Without a frozen ontology — and Microsoft GraphRAG does not ship with one — the graph is a function of the indexing run as much as the corpus.
Staleness is the structural one. The Microsoft-style pipeline assumes a static corpus. New documents force a community-restructuring pass, and many teams in practice rebuild the graph rather than attempt the surgery (Maarga Systems). LightRAG’s incremental design responds directly to this constraint and reports roughly 70% reduction in update time on 2026 benchmarks (LightRAG GitHub) — a measurable signal of how costly the rebuild path is for the tools that take it.
Operational caveats compound the picture. Graph backends like Neo4j introduce their own query layer — Cypher Query Language for traversal — and the cost of a Multi-Hop Reasoning query at retrieval time is paid every time the user asks. The build cost is fixed; the query cost is recurring; the staleness cost shows up as scheduled rebuilds you didn’t budget for.
What the Cost Curve Predicts
The mechanism predicts the failure modes you should see in production, not just the ones you have already paid for.
If your corpus updates daily, the rebuild will dominate your cost more than queries do — the static-corpus assumption is the silent constraint. If your ratio of distinct entities to source tokens is high — dense biographical, financial, or regulatory text — expect the upper end of the five-to-ten times blowup ratio rather than the lower end. If you choose a more expensive model than GPT-4o for the extraction pass, expect costs to climb several-fold without proportional quality gain; the bottleneck is the prompt design, not the model intelligence. And if your queries are mostly local — “what does this contract say about indemnity?” — the community-summary layer is overhead the user never benefits from.
Newer architectures absorb these predictions. LazyGraphRAG defers summary generation until queries arrive and reports query costs more than 700 times lower than full GraphRAG (Microsoft Research). Real-world LazyGraphRAG deployments in financial, legal, and healthcare contexts have reported 70 to 97% cost reductions versus the baseline (The Stack). LightRAG was published at EMNLP 2025 and is the open-source leader for incremental updates (LightRAG arXiv).
Treat full Microsoft GraphRAG as a deliberate choice for static corpora where global summarization is the actual product the user wants, not a default for every Knowledge Graphs For RAG project. Microsoft’s own follow-up work positions LazyGraphRAG as the successor for most use cases, and that signal is intentional.
Rule of thumb: If your documents change weekly, build with LazyGraphRAG or LightRAG; reserve full GraphRAG for static corpora where global summarization is the actual product.
When it breaks: The architecture assumes a static corpus and a global-summarization use case. On dynamic corpora the rebuild dominates total cost; on local-search use cases, the community-summary layer is overhead the user never reads.
The Data Says
The cost cliff is not a tuning problem — it is a structural feature of recursive LLM-built graphs, and the engineering limits follow from the same recursion. Newer architectures absorb the lesson by deferring summarization, swapping global queries for local ones, or compressing the graph itself. The gap between full GraphRAG and its successors at indexing time is roughly three orders of magnitude, with LazyGraphRAG indexing at about 0.1% of full GraphRAG cost (Microsoft Research).
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors