In-Context Learning Gaps, Hybrid Complexity, and the Hard Technical Limits of State Space Models
ELI5
State space models compress the past into a fixed-size hidden state, trading perfect recall for linear-time speed. Pure Mamba struggles on tasks that require remembering a specific earlier token. Hybrids fix this by mixing in a small dose of attention.
Pure SSMs were supposed to retire the transformer. The math was elegant — linear time, fixed memory, infinite context in principle. Then someone actually benchmarked an 8-billion-parameter pure Mamba-2 against a transformer of the same size, and something cracked that the theory had not predicted. The fix was not a cleverer state equation or a bigger model. It was a small dose of the very thing SSMs were supposed to replace.
The Compression Tax Every State Space Model Pays
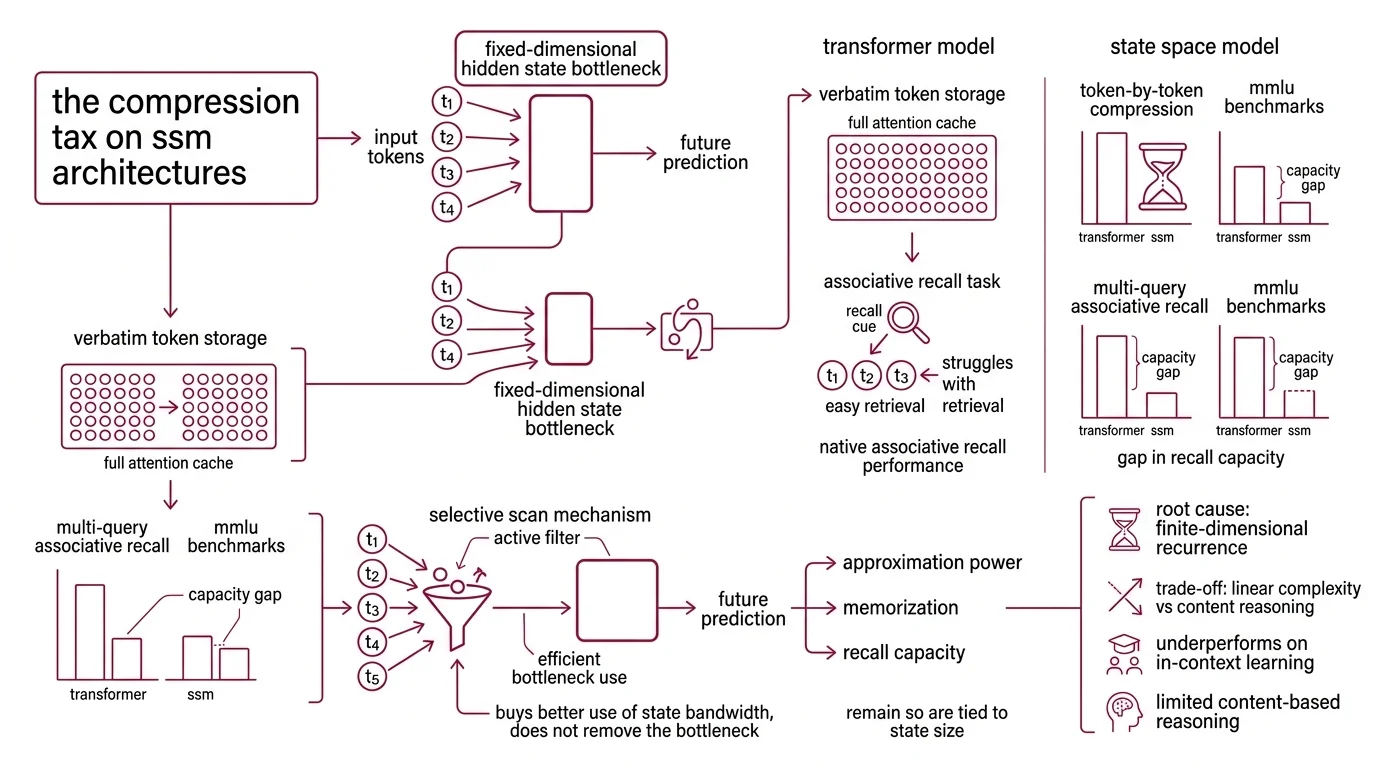
Every State Space Model inherits the same design decision: collapse the past into a fixed-dimensional hidden state and let that state march forward through time. This is what makes the architecture linear rather than quadratic in sequence length. But compression has a cost that only becomes visible on certain tasks, and only when the models are large enough for a fair benchmark.
What are the limitations of pure Mamba compared to transformers?
The core weakness is content-based reasoning. A Mamba Architecture model, like other subquadratic-time SSMs, cannot natively perform associative recall — the task of producing “Potter” after seeing “Harry Potter” earlier in the sequence — because the earlier tokens have already been collapsed into a fixed-dimensional state by the time the cue arrives (Gu & Dao). What survives is what the compression chose to keep.
A transformer stores the entire past verbatim in its attention cache, so any earlier token can be retrieved at any later step. An SSM has to decide, at the moment each token arrived, what was worth remembering. On multi-query associative recall benchmarks the contrast is stark: Mamba struggles where transformers handle the task with ease. The gap is not a fine-tuning gap; it is a capacity gap written into the state size.
The Selective Scan mechanism Mamba introduced was meant to close this gap by letting the model choose which tokens deserve state bandwidth. It helps — selectivity is why Mamba outperformed its predecessors. But approximation power, memorization, and associative-recall capacity remain tied to state size in a way that selection alone cannot escape. Selectivity buys better use of the bottleneck. It does not remove the bottleneck.
Not a training artifact. A property of finite-dimensional recurrence.
Why do state space models underperform on in-context learning and MMLU?
In-context learning depends on two things happening cleanly: surfacing the right earlier tokens when the cue arrives, and combining them with the current query in a content-dependent way. Transformers excel at the first because attention is a direct lookup over the whole context window. Subquadratic SSMs struggle at the first because their content lookup is mediated by whatever the compressed state chose to preserve (Gu & Dao).
The benchmark picture confirmed this before any hybrid was built. Waleffe et al. evaluated an 8B pure Mamba-2 against an 8B transformer and localized the gap to a specific pattern of tasks — five-shot MMLU, which asks the model to absorb and apply demonstrations from within the prompt, and Phonebook, which tests key-value retrieval from earlier context (Waleffe et al.). On tasks that reward understanding-in-context more than pattern memorization, pure SSMs trailed the transformer baseline.
RWKV and other Linear Attention lineages face structurally similar limits. They all trade quadratic attention for some form of compressed recurrence, and the compression shows up on recall-heavy benchmarks. Mamba-3 (ICLR 2026) introduces architectural refinements — exponential-trapezoidal discretization, complex-valued state updates, a MIMO formulation — that lift downstream accuracy modestly at small scale, but none of these, by themselves, closes the gap with attention on the hardest recall tasks.
The “Mamba cannot do in-context learning” framing that circulated in early critiques has not aged well as an absolute claim. Pure SSMs still lag on recall-heavy benchmarks; they improve steadily with scale and architectural tweaks; and the hybrids that followed close the gap in the most consequential places. The framing worth keeping is narrower: content-based lookup is the specific thing compressed recurrence is bad at. The rest is negotiable.
The Hybrid Compromise and Its Invisible Bill
Once the weakness was localized — not “SSMs are bad at everything” but “SSMs are bad at content-based lookup” — the obvious move was to stop treating attention and SSMs as rivals and start treating them as complementary primitives. That is what every production hybrid does. The interesting question is what the pairing actually costs.
What are the engineering tradeoffs of hybrid SSM-attention architectures?
The accuracy case for hybrids is clean. Waleffe et al. showed that an 8B Mamba-2-Hybrid — roughly 43% Mamba-2 layers, 7% self-attention, and 50% MLP — exceeded the 8B pure transformer on all twelve of their standard benchmarks, with an average gain of 2.65 points, a 3.5-point bump specifically on 5-shot MMLU, and token generation up to 8× faster (Waleffe et al.). Other production recipes corroborate the pattern without matching the ratio. NVIDIA’s Nemotron-H 56B model pairs 54 Mamba-2 layers with 54 MLP layers and only 10 attention layers, trained on 20 trillion tokens in FP8, and reports up to 3× throughput against transformers of comparable accuracy like Llama-3.1-70B and Qwen-2.5-72B (Nemotron-H paper). AI21’s Jamba-1.5 Large uses a 1:7 attention-to-Mamba ratio with 16 Mixture Of Experts experts and a 256K context window, and notably keeps Mamba-1 rather than Mamba-2 — the team found the older SSM combined better with attention at scale (Jamba-1.5 paper). Falcon-H1 takes a parallel rather than interleaved approach, running attention heads and Mamba-2 heads side by side inside a single mixer block.
A detail worth noticing: no two recipes agree on the attention ratio. Waleffe landed near 7%, Nemotron-H closer to 8%, Jamba near 12%, Falcon-H1 makes it tunable per layer. The right ratio is task-dependent and architecture-specific — treat it as an empirical parameter, not a universal constant.
The hidden bill arrives at inference time. An attention layer stores a KV cache that grows per token in small kilobyte increments. An SSM layer stores a fixed-size state that is measured in megabytes and is overwritten in place as tokens arrive. Mixing both in one memory pool causes fragmentation and breaks assumptions the serving stack was built around. Standard prefix caching — the technique that lets a serving system reuse prior prompt computations across requests — works for attention KV cache because the cache is additive and replayable. It fails for SSM layers because the state has been written over; there is no prefix to reuse (SGLang hybrid support).
There is also a latency floor nobody advertised. On edge GPUs, the custom kernels that make SSMs fast in theory become the dominant cost in practice — more than 55% of inference latency trace to those kernels because their element-wise sequential nature resists the parallelism GPUs are built for (SSM long-context paper). At short contexts, transformers still win: up to 1.9× faster under 8,000 tokens in the same study. The SSM advantage only arrives when the sequence is long enough. Around 57,000 tokens, SSMs ran up to 4× faster with roughly 64% less memory (SSM long-context paper). Speed is not a property of the architecture — it is a property of the context length at which you measure it.
Long Context Modeling is where hybrids earn their keep. For shorter prompts, attention remains the more efficient primitive even after all the SSM optimizations.
What the Compression Predicts in Practice
Once you see the mechanism, the behavior becomes predictable — and practical choices fall out of the math rather than from benchmark roulette.
- If your workload is long-context document reasoning with steady prompts, a hybrid with a small attention fraction is likely to outperform a pure transformer on both accuracy and throughput — provided your serving stack handles SSM state correctly.
- If your workload is short, heavy on in-context demonstrations, and latency-sensitive, a pure transformer of similar size is usually the safer default. The crossover where SSMs start winning sits roughly at the 8K-token mark and grows from there.
- If your deployment target is an edge GPU, the SSM kernels will dominate latency even when they dominate nothing else. Profile before assuming linear-time math translates to linear-time inference.
- If you benchmark a pure SSM and see it lose on MMLU or Phonebook-style tasks, do not reach for hyperparameters first. The recall gap is structural, and hyperparameter search will not find what the state size cannot hold.
Rule of thumb: A small attention budget — often in the single digits as a percentage of layers — recovers most of the recall capability without surrendering the throughput advantage on long contexts.
When it breaks: The hardest failure mode is a workload that demands heavy associative recall and very long context simultaneously. Pure SSMs lose the recall; pure transformers lose the throughput; and hybrids inherit both the kernel-latency floor at short sequences and the prefix-caching breakage at serving time. No current architecture resolves this trilemma cleanly — it is a research frontier, not a solved problem.
Serving compatibility notes:
- Prefix caching: Standard KV-prefix caching breaks for SSM layers because state is overwritten in place. Use framework versions with explicit hybrid-model support — SGLang and vLLM added this handling through 2025–2026.
- Memory layout: Attention KV caches grow in per-token kilobytes; SSM states are megabyte-scale contiguous blocks held until request completion. Mixing both in one pool causes fragmentation — allocate heterogeneously.
The Data Says
The pure-SSM promise of linear-time intelligence ran into a structural tax: fixed-dimensional recurrence cannot perform content-based recall the way attention can, and on in-context benchmarks the gap is measurable. Hybrids close the accuracy gap with a small attention fraction and earn substantial throughput gains on long contexts — but they also import a serving-stack complexity transformers never required. The architecture question is no longer attention versus SSM; it is how much of each, in what configuration, for which workload.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors