Implementing Attention from Scratch: PyTorch, FlashAttention, and Grouped-Query Optimization
Table of Contents
TL;DR
- Attention is four components with strict tensor contracts — decompose before you generate code
- PyTorch’s native SDPA dispatches to FlashAttention automatically — but only if your shapes and dtypes are correct
- Grouped-query attention cuts KV-cache memory by an order of magnitude — spec the head ratio or your model won’t fit in VRAM
You asked your AI tool to implement self-attention. It gave you something that runs. It even produces reasonable-looking outputs on a toy dataset. Then you scaled to real sequence lengths and the whole thing blew up — wrong shapes, silent NaN gradients, memory that doubles every layer. The Attention Mechanism is not hard to understand. It is brutally hard to specify correctly.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex)
- Working knowledge of Transformer Architecture and tensor operations
- A target model configuration: head count, embedding dimension, sequence length, and dtype
This guide teaches you: how to decompose attention into specifiable components so your AI tool generates an implementation that survives production shapes, FlashAttention dispatch, and GQA memory optimization.
The Attention Implementation That Silently Breaks
Here’s the scene. Developer prompts Cursor: “implement multi-head self-attention in PyTorch.” Gets back clean code. Looks correct. Passes a quick smoke test with small tensors.
Ships it. Sequence length hits a real workload. Memory explodes. Attention scores overflow to inf. Softmax returns NaN. The spec never mentioned the scale factor.
The code compiled. The math was wrong. Two different problems. Your AI tool solved the first one and ignored the second because you never told it the second one existed.
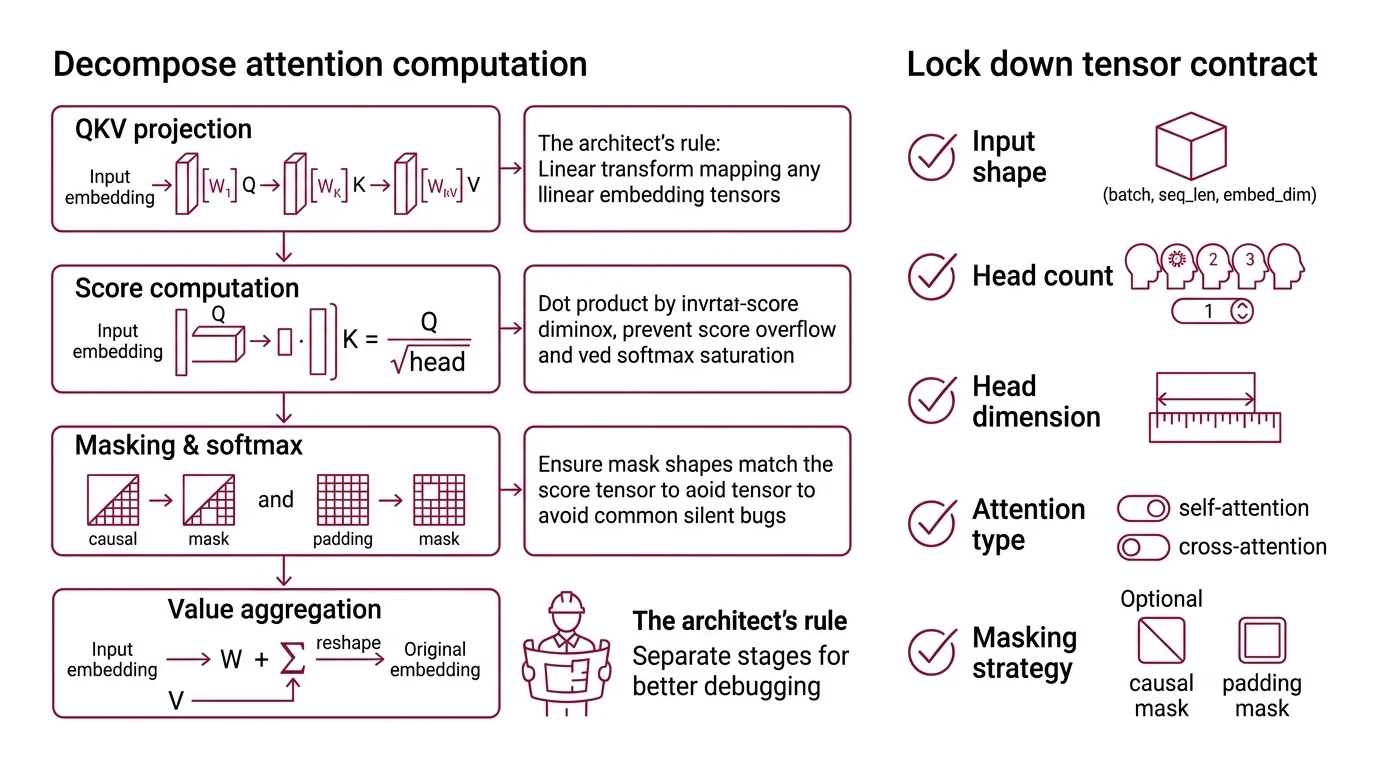
Step 1: Decompose the Attention Computation
Scaled Dot Product Attention is not one operation. It is four operations chained together with strict shape contracts between each stage. If you hand your AI tool “implement attention” as a single blob, it will merge concerns that need to stay separate.
Your system has these parts:
- QKV Projection — three linear transforms mapping input embeddings to query, key, and value tensors. Each has its own weight matrix. Separate concern from the attention math itself.
- Score Computation — the dot product between Q and K, scaled by the inverse square root of head dimension. This is where the scale factor lives. Skip it and softmax saturates on long sequences.
- Masking and Softmax — causal masks, padding masks, or no mask. The mask shape must match the score tensor exactly. This is where most silent bugs hide.
- Value Aggregation — weighted sum of V using the softmax output. The final reshape back to the original embedding dimension.
The Architect’s Rule: If your spec doesn’t separate these stages, the AI will fuse them into a monolith. Bugs in score computation will look like bugs in value aggregation. Good luck debugging that.
Step 2: Lock Down the Tensor Contract
This is where attention implementations die. Not in the math. In the shapes.
Context checklist for your AI tool:
- Input shape:
(batch, seq_len, embed_dim)— specify all three explicitly - Head configuration: number of heads, head dimension, the relationship
embed_dim = num_heads * head_dim - Q/K/V shapes after projection:
(batch, num_heads, seq_len, head_dim)— the reshape and transpose order matters - Scale factor:
1 / sqrt(head_dim)— not1 / sqrt(embed_dim), not omitted entirely - Mask specification: causal (lower triangular), padding (from attention_mask), or both combined
- Output dtype: match input dtype. If using mixed precision, specify which operations stay in float32 (softmax, always)
- Cross Attention variant: if Q comes from one sequence and K/V from another, specify both sequence lengths separately
The Spec Test: If your context doesn’t specify that softmax must stay in float32 during mixed-precision training, the AI will cast it to float16. You’ll get gradient underflow. No error message. Just quietly wrong results.
Step 3: Wire the Optimization Layers
Naive attention is quadratic in memory and compute. Production models don’t run naive attention. Your spec needs to address optimization at two levels: the kernel level and the architecture level.
Build order:
- Naive implementation first — pure PyTorch, no optimization, all stages explicit. This is your correctness baseline. Every optimization gets validated against this.
- Flash Attention backend — PyTorch 2.10 ships
torch.nn.functional.scaled_dot_product_attention, which dispatches to FlashAttention, Memory-Efficient, or Math backends automatically (PyTorch Docs). Spec the dtype and GPU constraints that determine which backend fires. FlashAttention-2 requires Ampere, Ada, or Hopper GPUs and supports head dimensions up to 256 (Dao-AILab GitHub). - Grouped Query Attention configuration — GQA reduces the number of key-value heads while keeping full query heads. Llama 3 uses this approach to cut KV-cache by 16x, enabling 128K context windows (Sebastian Raschka). Spec the ratio: how many query heads share one KV head. Get this wrong and your model either wastes memory or loses quality.
For each optimization layer, your context must specify:
- What it receives (tensor shapes, dtypes)
- What it returns (same shape contract as naive, different memory profile)
- What it must NOT do (no silent dtype casting, no implicit masking)
- How to handle fallback (if FlashAttention is unavailable, fall back to Memory-Efficient, then Math)
Step 4: Prove the Attention Output Is Correct
You have multiple stages and two optimization layers. That’s several potential failure points. Don’t eyeball the output tensor and call it validated.
Validation checklist:
- Shape consistency — output matches
(batch, seq_len, embed_dim)regardless of which backend fires. Failure looks like: dimension mismatch error on the next layer’s input. - Numerical equivalence — optimized output matches naive output within floating-point tolerance for your training dtype. Failure looks like: test passes but downstream loss diverges.
- Causal mask enforcement — future positions have zero attention weight. Failure looks like: model generates tokens that reference future context during training.
- Memory profile — FlashAttention should show sub-quadratic memory on longer sequences. Failure looks like: OOM at the same sequence length as naive attention.
- GQA head mapping — verify that
num_kv_headsdivides evenly intonum_heads. Failure looks like: shape error during KV repeat, or silent broadcasting that corrupts attention patterns.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| “Implement attention” as one prompt | AI merged QKV projection with score computation | Decompose into named stages |
| Omitted the scale factor | AI used unscaled dot products, softmax saturated at long sequences | Specify 1 / sqrt(head_dim) explicitly |
| Said “use FlashAttention” without dtype spec | AI wrote float64 tensors, FlashAttention fell back to Math kernel silently | Specify float16 or bfloat16 input dtypes |
| Specified GQA without head ratio | AI guessed num_kv_heads = 1 (multi-query, not grouped-query) | State exact query-to-KV head ratio |
| Skipped causal mask spec | AI defaulted to no mask — model attended to future tokens | Specify “causal=True” or provide mask shape |
Pro Tip
Every attention optimization trades one constraint for another. FlashAttention saves memory but restricts head dimensions and GPU families. GQA saves KV-cache but requires careful head-ratio tuning. Your spec isn’t done when the code runs. It’s done when every trade-off is tested.
Frequently Asked Questions
Q: How to implement a self-attention layer from scratch in PyTorch step by step? A: Decompose into QKV projection, scaled dot-product scoring, masked softmax, and value aggregation. Spec each stage’s tensor shapes independently. Validate the naive version before adding optimization — your AI tool needs a correctness baseline to test against.
Q: How to use FlashAttention to speed up transformer inference in 2026?
A: Use PyTorch 2.10’s native scaled_dot_product_attention — it dispatches to FlashAttention automatically when inputs are float16/bfloat16 on supported GPUs. Force the backend with sdpa_kernel(SDPBackend.FLASH_ATTENTION) for deterministic routing.
Q: When to use grouped-query attention vs. multi-query attention in production models? A: GQA shares KV heads across groups of query heads, balancing memory savings and quality. Multi-query attention uses a single KV head — maximum throughput but can degrade on complex reasoning. Uptraining from multi-head to GQA requires roughly 5% of original pre-training compute (arXiv).
Q: How to visualize attention weights to debug and interpret transformer model predictions? A: Extract the attention weight matrix after softmax, before value multiplication. Plot as a heatmap with source tokens on one axis, target tokens on the other. Uniform distributions signal the model isn’t attending to anything meaningful — a red flag for debugging.
Your Spec Artifact
By the end of this guide, you should have:
- Attention component map — named stages with tensor shapes at each boundary
- Optimization constraint list — dtype requirements, GPU families, head dimension limits, fallback chain
- Validation criteria — shape checks, numerical equivalence tolerances, memory profile targets, causal mask assertions
Your Implementation Prompt
Drop this into Claude Code or Cursor. Fill in the brackets with your model’s configuration. Every placeholder maps to a checklist item from Step 2.
Implement multi-head self-attention in PyTorch with these specifications:
Stage 1 — QKV Projection:
- Input shape: (batch, [YOUR_SEQ_LEN], [YOUR_EMBED_DIM])
- Number of heads: [YOUR_NUM_HEADS]
- Head dimension: [YOUR_HEAD_DIM] (must satisfy embed_dim = num_heads * head_dim)
- Three separate linear projections for Q, K, V
Stage 2 — Score Computation:
- Reshape Q, K to (batch, num_heads, seq_len, head_dim)
- Compute scaled dot product: (Q @ K.T) / sqrt(head_dim)
- Scale factor is 1/sqrt(head_dim), NOT 1/sqrt(embed_dim)
Stage 3 — Masking and Softmax:
- Apply [CAUSAL/PADDING/BOTH] mask before softmax
- Softmax MUST stay in float32 even during mixed-precision training
- Mask shape: (1, 1, seq_len, seq_len) for causal
Stage 4 — Value Aggregation:
- Weighted sum: softmax_output @ V
- Reshape back to (batch, seq_len, embed_dim)
- Output projection via linear layer
Optimization:
- Use torch.nn.functional.scaled_dot_product_attention for the fused kernel path
- Fallback chain: FlashAttention → Memory-Efficient → Math
- Input dtype: [FLOAT16/BFLOAT16] for FlashAttention dispatch
- If GQA: num_kv_heads = [YOUR_KV_HEADS], repeat KV heads to match num_heads
Validation:
- Assert output shape == input shape
- Assert numerical equivalence between naive and SDPA paths (atol=[YOUR_TOLERANCE])
- Assert causal mask: attention_weights[:, :, i, j] == 0 for all j > i
- Profile memory at seq_len=[YOUR_TEST_SEQ_LEN] — SDPA path must use less memory than naive
Ship It
You now have a decomposition framework for attention that separates correctness from optimization. Named stages, explicit contracts, optimization layers with fallback paths. The AI tool writes the code. You own the spec that makes it correct.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors