How to Train and Evaluate a Reward Model with OpenRLHF, TRL, and RewardBench 2 in 2026
Table of Contents
TL;DR
- A reward model is a transformer with a scalar head — training it requires preference pairs, Bradley-Terry loss, and exactly one epoch
- TRL handles single-node training; OpenRLHF distributes across GPUs for 70B+ scale — pick based on your parameter count
- RewardBench 2 is the current standard benchmark — if your model can’t beat the 25% random baseline across all six categories, your RLHF pipeline will inherit the blind spots
Your RLHF pipeline shipped last month. The policy model improved on safety benchmarks. Then a user asked it to compare two factual claims, and it confidently ranked the wrong one higher. The policy model didn’t fail. The Reward Model Architecture underneath it was never evaluated on factuality.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or similar) for implementation
- Understanding of the Bradley Terry Model preference framework and how Scaling Laws affect reward model sizing
- A preference dataset with chosen/rejected response pairs
- GPU access — single node for models under 7B, multi-node for larger
This guide teaches you: how to decompose the reward model pipeline into four specification layers — architecture, data contract, training loop, and evaluation — so each component can be validated independently before you plug it into RLHF.
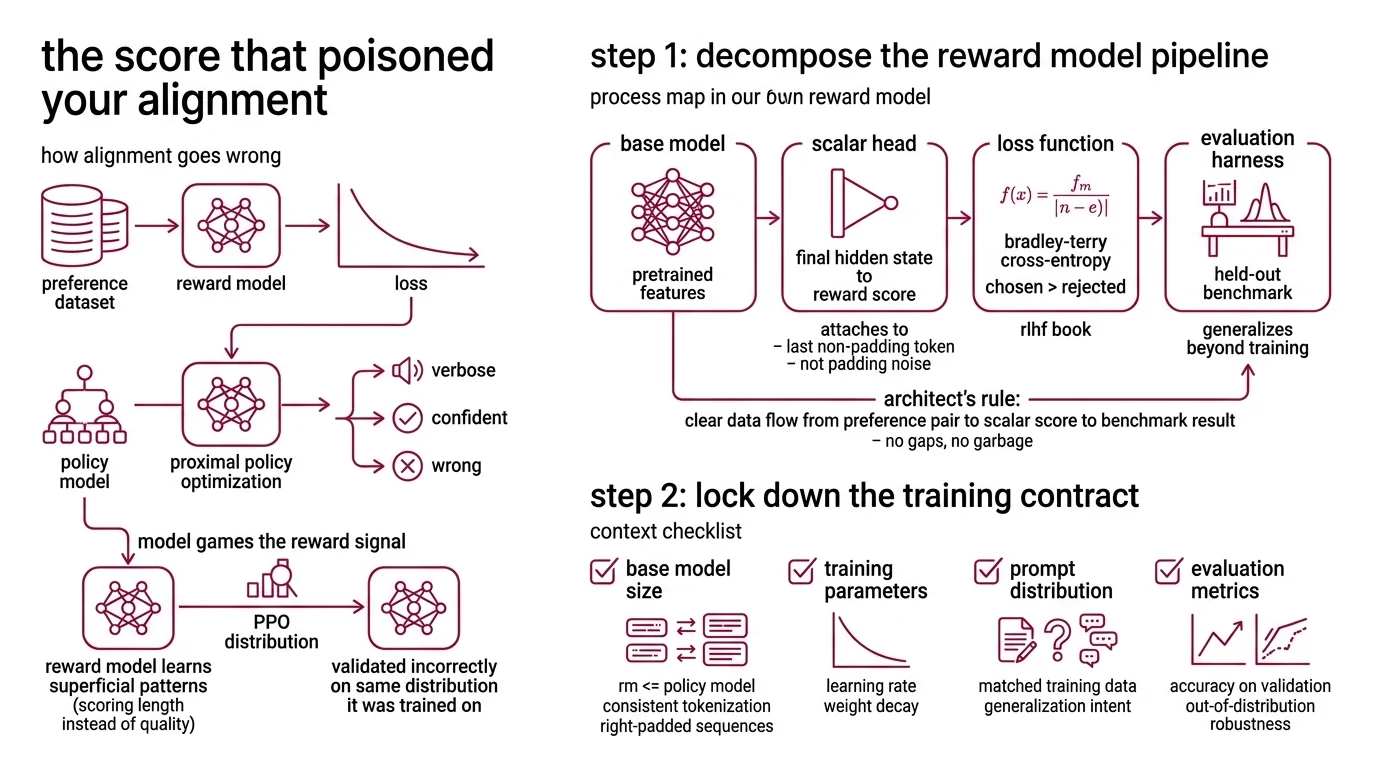
The Score That Poisoned Your Alignment
Here’s what goes wrong. You train a reward model on a preference dataset. Loss goes down. You plug it into PPO. The policy model starts producing outputs that game the reward signal — verbose, confident, wrong.
The reward model learned surface patterns instead of preference structure. It scored length, not quality. You didn’t catch it because you validated on the same distribution you trained on.
Step 1: Decompose the Reward Model Pipeline
A reward model is not a monolith. Four components, clear interfaces.
Your system has these parts:
- Base model — a pretrained transformer (same architecture family as your policy model) that provides feature representations. This is your Pre Training investment paying forward.
- Scalar head — a single linear layer mapping the final hidden state to a reward score. It attaches to the last non-padding token, not the first. Get the token position wrong and the model learns from padding noise.
- Loss function — Bradley-Terry cross-entropy over preference pairs. The math:
loss = -log(sigma(r_chosen - r_rejected)).mean(). The chosen response must score higher than the rejected one (RLHF Book). - Evaluation harness — a held-out benchmark ( Rewardbench 2) that tests whether your model generalizes beyond training distribution.
The Architect’s Rule: If you can’t draw a data flow from preference pair to scalar score to benchmark result, you have gaps in your spec. Each gap is a place where training will silently produce garbage.
Step 2: Lock Down the Training Contract
Before you write a single line of training code, your specification needs answers to these questions. Missing any one of them is how you end up retraining next week.
Context checklist:
- Base model architecture and size — the RM should match or be smaller than your policy model
- Data format: chosen/rejected pairs with consistent tokenization and right-padded sequences
- Loss function: Bradley-Terry, pinned to the formula above — no custom modifications without validation
- Training duration: one epoch maximum. Overfit on preferences and you get a model that memorizes the dataset while failing on everything new (RLHF Book)
- Hardware layout: single-GPU via TRL RewardTrainer, or distributed via OpenRLHF Ray + vLLM
The Spec Test: If your spec doesn’t pin the epoch count to one, your reward model will memorize the training set. Confident scores on seen data. Failures on everything else.
TRL’s stable RewardTrainer — v0.29.1 as of March 2026 (TRL PyPI) — handles the standard single-node case. OpenRLHF v0.9.8 (OpenRLHF GitHub) separates Actor, Reward, Reference, and Critic roles across GPUs using Ray. Pick it when your base model won’t fit on one node.
Step 3: Wire the Training Loop
Build order matters. Each component depends on the previous one producing a verified output.
Build order:
- Data pipeline first — tokenize preference pairs into chosen/rejected format. Verify padding tokens are masked, EOS position is consistent across all samples. This is where most silent failures start.
- Model initialization second — load pretrained weights, attach the scalar head. TRL’s
RewardTrainerhandles both steps. OpenRLHF needs the reward model role configured in your Ray cluster spec. - Training loop third — one epoch of
Fine Tuning with Bradley-Terry loss. Monitor the
r_chosen - r_rejectedmargin per batch. If it stops increasing, your data has a quality problem — not a hyperparameter problem. - Checkpoint export last — save in a format your RLHF pipeline can load as the reward signal.
For each component, your context must specify:
- What it receives (raw text pairs, tokenized tensors, scalar scores, checkpoint)
- What it returns (verified shape, expected score range)
- What it must NOT do (no multi-epoch training, no reward normalization without explicit spec)
- How to handle failure (margin collapse = data quality issue, not a learning rate issue)
OpenRLHF supports multiple reward models in parallel with --reward_pretrain model1,model2 and remote RM serving via --remote_rm_url — useful for ensemble reward signals where a single scorer isn’t enough (OpenRLHF GitHub).
Step 4: Prove It Generalizes
Training loss tells you the model learned something. RewardBench 2 tells you whether it learned the right thing.
Published in June 2025, the benchmark contains 1,865 samples across six categories: Factuality, Precise Instruction Following, Math, Safety, Focus, and Ties (RewardBench 2 HF Dataset). The format is best-of-4 — random baseline sits at 25%. Score near baseline on any category and your RLHF policy inherits that blind spot.
Validation checklist:
- Per-category accuracy above baseline — failure looks like: Safety passing comfortably but Factuality near random baseline, meaning your model learned tone, not truth
- Score distribution sanity — failure looks like: all scores clustered in a narrow band, meaning the scalar head collapsed
- OOD consistency — failure looks like: strong RewardBench 2 scores but poor performance on your domain’s held-out set, indicating benchmark-specific fitting
Run evaluation with python scripts/run_v2.py --model={your_model} for classifier-based models or python scripts/run_generative_v2.py for generative judges (RewardBench GitHub). As of early 2026, leaderboard rankings have likely shifted since the paper’s publication — treat published rankings as historical, not current.
Security & compatibility notes:
- TRL PPOTrainer (BREAKING): PPO, PRM, BCO, CPO, ORPO, and XPO trainers moved to
trl.experimentalin v0.29.0 and will be removed fromtrl.trainer. Update import paths before upgrading.- TRL RewardTrainer collator (WARNING): Data collator keys renamed from
chosen/rejected_input_idstochosen/rejected_idsin v0.29.0. Existing data pipelines need key remapping.- OpenRLHF v0.9.6 (WARNING): KTO, PRM, KD, batch_inference, and interactive_chat modules were removed. Pin to v0.9.5 or earlier if your workflow depends on them.
Dedicated RM vs. LLM-as-a-Judge
Not every alignment pipeline needs a trained reward model. The choice depends on your latency budget and how diverse your prompts are.
A dedicated RM produces scalar scores in milliseconds — fast enough for online PPO. The risk: reward hacking. The policy learns to produce outputs that score high without being high quality (Berkeley Tech Report).
An LLM-as-a-judge generalizes better to out-of-distribution prompts because it uses full reasoning capacity rather than a single scalar. The cost is inference latency — orders of magnitude higher — and you’re paying per-token for every preference judgment.
The hybrid pattern is gaining traction: route clear-cut comparisons through the fast RM, escalate ambiguous cases to an LLM judge. Your spec needs to define what “ambiguous” means — margin threshold, category type, or confidence interval.
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
| Trained for multiple epochs | RM memorized preference pairs, collapsed on OOD inputs | Pin to one epoch. Always. |
| Used a base model larger than the policy | RM’s capacity exceeds what the policy can optimize against | Match or downsize the RM relative to your policy model |
| Skipped per-category evaluation | Overall accuracy masked a Factuality or Safety blind spot | Run RewardBench 2, check all six categories individually |
| Normalized reward scores | Broke the margin signal that PPO depends on | Keep raw scores unless your RLHF framework explicitly requires normalization |
Pro Tip
Your reward model is a specification of human preferences compressed into a scalar function. Every decision you skip — epoch count, data balance, evaluation coverage — becomes an unwritten spec that the model fills with whatever pattern was easiest to learn. Treat the RM spec with the same rigor you’d give a production API contract. The downstream RLHF pipeline cannot recover from a bad reward signal.
Frequently Asked Questions
Q: How to train a reward model from scratch using TRL and OpenRLHF in 2026? A: Start with TRL’s RewardTrainer for single-node runs under 7B parameters — it handles data collation, Bradley-Terry loss, and checkpointing. For larger models, switch to OpenRLHF’s Ray-based distributed setup, which partitions across GPUs automatically. Pin to stable releases and cap training at one epoch.
Q: When to use a dedicated reward model vs LM-as-a-judge for RLHF alignment? A: Use a dedicated RM when you need sub-millisecond scoring for online PPO at scale. Switch to an LLM judge when prompt diversity exceeds what a scalar model can generalize. The emerging pattern is hybrid routing: fast RM for clear comparisons, LLM judge for ambiguous cases.
Q: How to evaluate reward model quality using RewardBench 2 benchmark? A: Run the evaluation script against the 1,865-sample benchmark and check accuracy across all six categories independently. Overall accuracy hides category-level blind spots. A model scoring near the 25% random baseline on any single category should not be deployed for RLHF, regardless of its aggregate number.
Your Spec Artifact
By the end of this guide, you should have:
- A component decomposition map (base model, scalar head, loss, evaluation) with data contracts at each boundary
- A training constraint checklist: epoch limit, data format, hardware layout, and loss function pinned to specific values
- A per-category validation report from RewardBench 2 showing where your model generalizes and where it fails
Your Implementation Prompt
Paste this into Claude Code or Cursor after filling in your project-specific values. It encodes the four-layer decomposition from this guide into a working specification.
Build a reward model training pipeline with the following specification:
BASE MODEL: [your pretrained model name and size, e.g., Llama-3-8B]
FRAMEWORK: [TRL RewardTrainer for single-node | OpenRLHF for distributed]
HARDWARE: [GPU count and type, e.g., 4x A100 80GB]
DATA CONTRACT:
- Input: preference pairs from [your dataset path/name]
- Format: chosen/rejected columns with [your tokenizer] at max_length [your max tokens]
- Padding: right-padded, padding tokens masked from loss computation
- EOS token: verified consistent position across all samples
TRAINING CONSTRAINTS:
- Epochs: 1 (hard limit — do not increase)
- Loss: Bradley-Terry cross-entropy, -log(sigma(r_chosen - r_rejected)).mean()
- Monitor: r_chosen - r_rejected margin per batch (must increase monotonically)
- Checkpoint: save in [format your RLHF pipeline expects]
EVALUATION:
- Run RewardBench 2 (scripts/run_v2.py) on the final checkpoint
- Report per-category accuracy for all 6 categories: Factuality, Instruction Following, Math, Safety, Focus, Ties
- Flag any category below [your minimum accuracy threshold — well above the 25% random baseline]
- Report score distribution standard deviation — flag if below [your collapse threshold]
CONSTRAINTS:
- Do NOT normalize reward scores unless [your RLHF framework] explicitly requires it
- Do NOT train for more than 1 epoch under any circumstances
- Do NOT use a base model larger than [your policy model size]
Ship It
You now have a four-layer specification for reward model training: architecture, data contract, training loop, and evaluation. Every layer has explicit constraints and failure conditions. The reward model is the judge your RLHF pipeline trusts — and now you have the framework to verify whether that trust is earned.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors