How to Pre-Train a Language Model with Megatron-LM, DeepSpeed, and NeMo in 2026
Table of Contents
TL;DR
- NeMo dropped its LLM training collections in 2026 — Megatron Bridge is the replacement. Update your stack before you start.
- Decompose the training pipeline into four layers — data, parallelism, compute, validation — and specify each one before touching a config file.
- Validate at small scale first. A misconfigured parallelism setting on 8 GPUs costs an afternoon. On 512 GPUs it costs a week.
You found this guide because you searched for NeMo Pre Training. Here is what changed: NVIDIA removed the LLM and multimodal collections from NeMo in early 2026. If you followed a tutorial from 2024, your imports are broken and your training script fails on line one. The fix is Megatron Bridge — NVIDIA’s PyTorch-native replacement that now handles everything NeMo used to do for language model training.
Before You Start
You’ll need:
- A distributed GPU cluster (minimum 8 GPUs for meaningful parallelism testing)
- Working knowledge of Scaling Laws and how they size your compute budget
- Familiarity with Megatron-LM or Deepspeed — you need at least one, not necessarily both
- A tokenized, deduplicated dataset ready for training
This guide teaches you: How to decompose a distributed pre-training stack into specifiable layers, pick the right framework combination, and validate your configuration before committing cluster time.
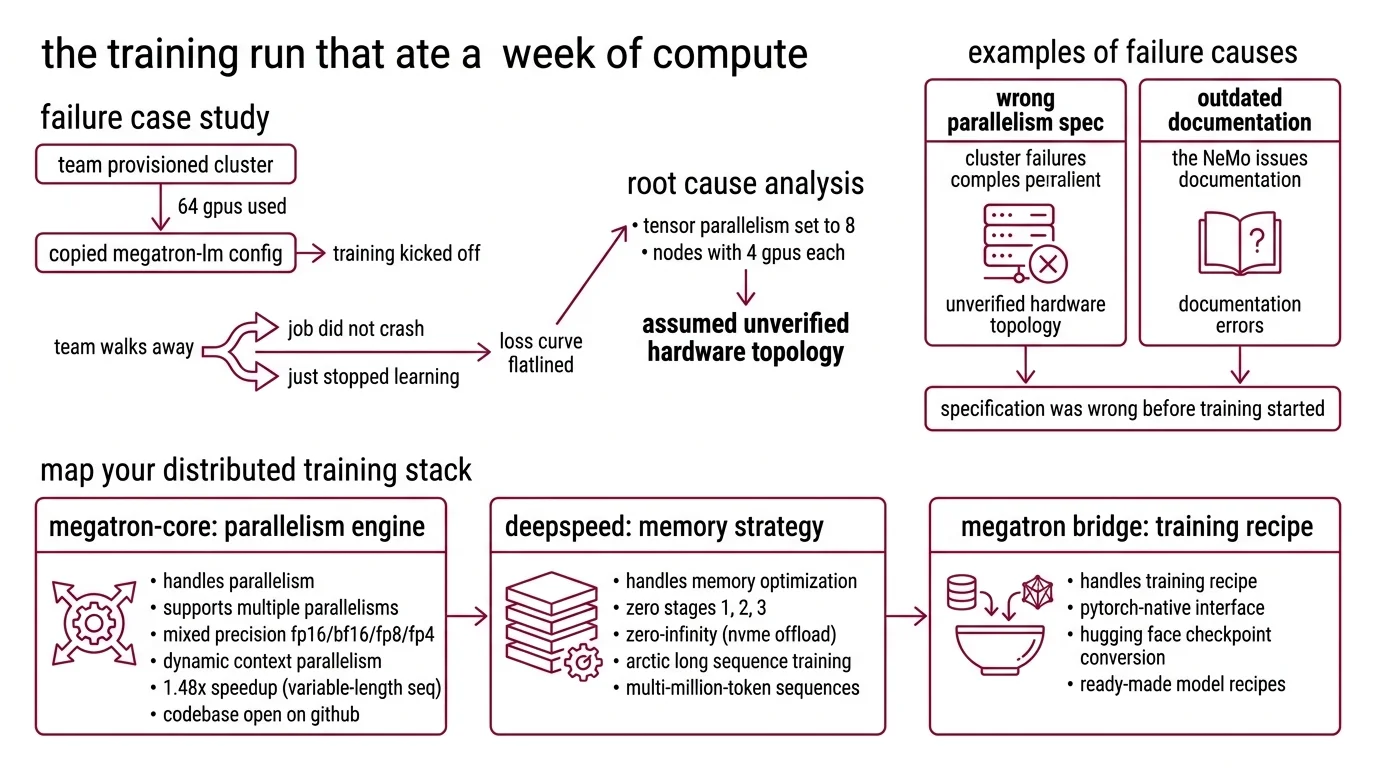
The Training Run That Ate a Week of Compute
Here is a failure I see regularly. A team provisions a 64-GPU cluster, copies a Megatron-LM config from a blog post, kicks off training, and walks away for the weekend. Monday morning the loss curve flatlined at step 4,000 because tensor parallelism was set to 8 on nodes with 4 GPUs each. The job did not crash. It just stopped learning.
That config worked on the author’s cluster. It did not work on theirs because the parallelism spec assumed a hardware topology nobody verified.
A different team tried pre-training with NeMo 2.7 following NVIDIA’s own 2024 documentation. The LLM collections had been migrated to a separate library. Import errors on line one.
Both failures share the same root cause: the specification was wrong before training started.
Step 1: Map Your Distributed Training Stack
Three frameworks dominate distributed pre-training as of March 2026. Each owns a different layer of the problem — they are not alternatives, they are components.
Megatron-Core handles parallelism. Version 0.16.1 supports tensor, pipeline, data, expert, context, and FSDP parallelism with mixed precision across FP16, BF16, FP8, and FP4 (Megatron-Core PyPI). Dynamic Context Parallelism delivers up to 1.48x speedup for variable-length sequence training. Development moved to GitHub in December 2025, making the full codebase open. This is your parallelism engine.
DeepSpeed handles memory optimization. Version 0.18.8 provides ZeRO stages 1 through 3 — sharding optimizer states, gradients, and parameters across GPUs — plus ZeRO-Infinity for offloading to NVMe (DeepSpeed Docs). Arctic Long Sequence Training, shipped in June 2025, extends support to multi-million-token sequences. This is your memory strategy.
Megatron Bridge handles the training recipe. It replaced NeMo’s LLM collections with a PyTorch-native interface, bidirectional Hugging Face checkpoint conversion, and ready-made recipes for over 30 model architectures including Llama 3.x, DeepSeek V2/V3, and Qwen 2.5/3 (Megatron Bridge GitHub). This is your model definition layer.
NeMo v2.7.1 still exists but has pivoted to speech and audio only (NeMo GitHub). Version 2.7.0 was the last release with LLM support. If your workflow depends on NeMo for language model training, migrate to Megatron Bridge now.
All three frameworks are open-source under Apache 2.0 or MIT licenses.
Security & compatibility notes:
- NeMo pre-2.6.1 (CVSS 7.8-8.0): Ten high-severity vulnerabilities including remote code execution via checkpoint loading, patched in NeMo 2.6.1+. Do not load checkpoints from earlier versions without upgrading first. See NVIDIA Security Bulletin, February 2026.
- Megatron-LM pre-0.14.0: Code injection via insecure input handling. Update to Megatron-Core 0.14.0 or later.
- Python 3.10 deprecation: Megatron-Core 0.17.0 and Megatron Bridge 0.4.0 will require Python 3.12 minimum. Plan your environment migration now.
Step 2: Specify Your Data and Parallelism Contract
Before you write a single config line, answer these questions. Each one prevents a class of silent failure.
Data pipeline specification:
- Tokenizer: Which one, and does it match your target vocabulary size? Whether your architecture uses Masked Language Modeling or causal language modeling, the data format must match the training objective.
- Data Deduplication strategy: Exact-match, MinHash, or both? Duplicates inflate your effective token count without improving the model.
- Data mix: What ratio of code, web text, books, and domain-specific data? The mix determines what the model learns — not just how well.
- Sequence length: Fixed or variable? Variable-length training benefits from Megatron-Core’s Dynamic CP, but your data loader must support packing.
Parallelism specification:
- Tensor parallelism (TP): How many GPUs share a single layer? Match TP to intra-node bandwidth — tensor parallelism across nodes kills throughput silently.
- Pipeline parallelism (PP): How many stages? More stages mean more microbatches needed to keep GPUs busy.
- Data parallelism (DP): Everything else. DP times TP times PP must equal your total GPU count exactly.
- Memory strategy: ZeRO stage 1, 2, or 3? Stage 3 maximizes memory savings but adds communication overhead. Start with stage 1 unless your model exceeds single-GPU memory at that setting.
Compute budget specification: The Chinchilla scaling law established roughly 20 tokens per parameter as the compute-optimal training ratio. In practice, modern teams overtrain far beyond that threshold — Llama 3 8B was trained on 15 trillion tokens, roughly 1,875 tokens per parameter (Scaling Laws Blog). When you factor in inference cost at scale, smaller models trained significantly longer can outperform larger compute-optimal models for high-traffic deployments.
Your budget specification needs three numbers: target parameter count, available compute hours, and expected inference volume. Those three numbers determine whether you train a large model at Chinchilla-optimal or a smaller model with heavy overtraining.
The Spec Test: If your parallelism configuration does not account for your node’s GPU-to-GPU interconnect topology, you will not get an error. You will get training that runs at a fraction of its potential throughput — and you will not know until you benchmark.
Step 3: Wire the Training Configuration
Order matters. Each layer depends on the one below it.
Build order:
- Environment first — Python version, CUDA version, framework versions. Pin everything. Megatron-Core 0.16.1 requires Python 3.10 or later. DeepSpeed 0.18.8 supports Python 3.8 through 3.12. Pick the intersection that matches your cluster and plan for the upcoming Python 3.12 minimum.
- Data pipeline second — Tokenization, deduplication, shuffling, sharding. Validate the data pipeline independently before connecting it to the training loop. Feed corrupted data in and you train on garbage for 72 hours before the loss curve tells you something is wrong.
- Model definition third — Use Megatron Bridge recipes for supported architectures. Bidirectional checkpoint conversion means you can start from a Hugging Face checkpoint for continued pre-training or initialize from scratch.
- Parallelism and optimization last — TP, PP, DP, and ZeRO configuration come together here. The settings depend on hardware topology, model size, and memory budget — all values you locked down in Steps 1 and 2.
For each layer, your configuration must specify:
- What it receives (data format, tensor shapes, checkpoint format)
- What it produces (processed batches, gradients, checkpoints)
- What it must NOT do (no silent data truncation, no unlogged gradient overflow)
- How to handle failure (checkpoint interval, restart policy, loss spike detection)
Step 4: Validate Before You Burn the Cluster
A full pre-training run is expensive. Validate incrementally.
Validation checklist:
- Throughput benchmark — Run a short test on a single node. Measure tokens per second per GPU. Compare against published benchmarks for your hardware. If throughput falls well below expected levels, your parallelism config has a bottleneck. Fix it before scaling up.
- Loss curve sanity — Train for a few hundred steps on a small data subset. The loss should drop steeply early and begin flattening. Flat from step zero means the learning rate is wrong or the data is corrupted. Spikes mean gradient overflow — check precision settings.
- Checkpoint round-trip — Save a checkpoint mid-run. Load it. Resume training. Compare the loss immediately after restart with and without the interruption. Divergence beyond noise means your serialization is broken.
- Memory profiling — Monitor GPU memory at peak. If you are running close to capacity with ZeRO stage 1, move to stage 2 or shrink your microbatches. Running at near-maximum memory works until a longer-than-average sequence triggers an OOM that kills a multi-day run in its final hours.
Common Pitfalls
| What You Did | Why Training Failed | The Fix |
|---|---|---|
| Used NeMo 2.7+ for LLM training | LLM collections removed; imports fail | Migrate to Megatron Bridge |
| Copied TP=8 from a blog post | Your node has 4 GPUs; TP crossed node boundary | Set TP less than or equal to GPUs per node |
| Skipped data deduplication | Model memorized repeated passages | Run MinHash dedup before tokenization |
| Set ZeRO stage 3 by default | Communication overhead slowed training | Start at stage 1, increase only on OOM |
| No checkpoint validation | Corruption discovered after 72 hours | Test save-load-resume in first 1,000 steps |
Pro Tip
Treat your training config like a deployment manifest. Every value should trace to a measurement or a constraint — never to a default. If you cannot explain why TP equals 4 instead of 2 or 8, you have not specified it. You have guessed. The difference between guessing and specifying is the difference between a training run that converges and one that burns compute while you sleep.
Frequently Asked Questions
Q: How to pre-train a language model from scratch step by step? A: Decompose into four layers: data pipeline (tokenize, deduplicate, shard), model definition (architecture, vocabulary, sequence length), parallelism (TP, PP, DP, ZeRO stage), and validation (throughput, loss curve, checkpoint round-trip). Specify each layer fully before configuring it. Always validate at single-node scale before scaling to the full cluster — it catches most configuration errors at a fraction of the cost.
Q: When should you pre-train a new model instead of fine-tuning an existing one? A: Pre-train when your domain data distribution differs fundamentally from existing models — specialized scientific corpora, low-resource languages, or proprietary data that Fine Tuning cannot bridge. If an existing checkpoint gets you within range, continued pre-training or RLHF alignment is almost always cheaper. The decision hinges on how far your target distribution sits from available base models and whether that gap justifies the compute investment.
Q: How to choose between Megatron-LM, DeepSpeed, and NeMo for distributed pre-training in 2026? A: They are not competing alternatives — they are layers in the same stack. Use Megatron-Core for parallelism, DeepSpeed for memory optimization via ZeRO, and Megatron Bridge for model recipes and checkpoint management. NeMo no longer handles LLM training as of v2.7.0. The real choice is which combination of these layers fits your model size and hardware, not which single framework to pick.
Your Spec Artifact
By the end of this guide, you should have:
- A hardware-to-parallelism mapping that matches TP, PP, and DP to your cluster topology
- A data pipeline contract specifying tokenizer, dedup method, data mix ratios, and sequence length handling
- A validation checklist with pass/fail criteria for throughput, loss curve shape, checkpoint integrity, and memory headroom
Your Implementation Prompt
Paste this into Claude Code, Cursor, or your preferred AI assistant to generate a training configuration matched to your infrastructure. Fill in the bracketed values from your Step 2 specification.
Generate a distributed pre-training configuration for:
MODEL DEFINITION:
- Architecture: [your model architecture — e.g., Llama-style decoder-only]
- Parameter count: [target parameter count]
- Vocabulary size: [tokenizer vocabulary size]
- Max sequence length: [your sequence length]
- Training objective: [causal LM or masked LM]
- Framework: Megatron Bridge with Megatron-Core parallelism
HARDWARE:
- Total GPUs: [your GPU count]
- GPUs per node: [GPUs per node]
- GPU type and memory: [e.g., H100 80GB]
- Interconnect: [NVLink intra-node, InfiniBand inter-node, etc.]
PARALLELISM (TP must be <= GPUs per node; TP * PP * DP = total GPUs):
- Tensor parallelism: [TP value derived from intra-node bandwidth]
- Pipeline parallelism: [PP value, or 1 if model fits in TP shards]
- Data parallelism: [remaining GPUs after TP and PP allocation]
- ZeRO stage: [1, 2, or 3 based on memory profiling]
- Sequence packing: [yes/no — if yes, enable Dynamic CP]
DATA PIPELINE:
- Tokenizer: [your tokenizer name and vocabulary size]
- Deduplication method: [exact-match, MinHash, or both]
- Data mix: [ratios by source type — code, web, books, domain]
- Total tokens: [target token count based on scaling law choice]
VALIDATION GATES:
- Throughput target: [tokens/sec/GPU from single-node benchmark]
- Checkpoint interval: [steps between saves]
- Max memory utilization: [target percentage, e.g., 85%]
- Loss curve check: [expected loss at step 1000 on validation subset]
Output a complete configuration with inline comments explaining why
each value was chosen. Flag any value that cannot be determined from
the specification above and ask me to provide it.
Ship It
You now have a four-layer decomposition for distributed pre-training where every configuration value traces back to a specification or a measurement. The framework stack has changed — NeMo is out, Megatron Bridge is in — but the engineering discipline has not. Specify the stack. Validate at small scale. Then burn the compute.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors