How to Build Retry, Fallback, and Self-Correction in AI Agents (2026)

Table of Contents
TL;DR
- Treat every LLM call as a network call that can fail — design the retry contract before you write the first tool.
- Persistence is a separate concern from retries. Pick a checkpointer for state, a workflow engine for orchestration, and a validator for output shape.
- Self-correction is just a retry with a better error message — let the validator tell the model exactly what was wrong.
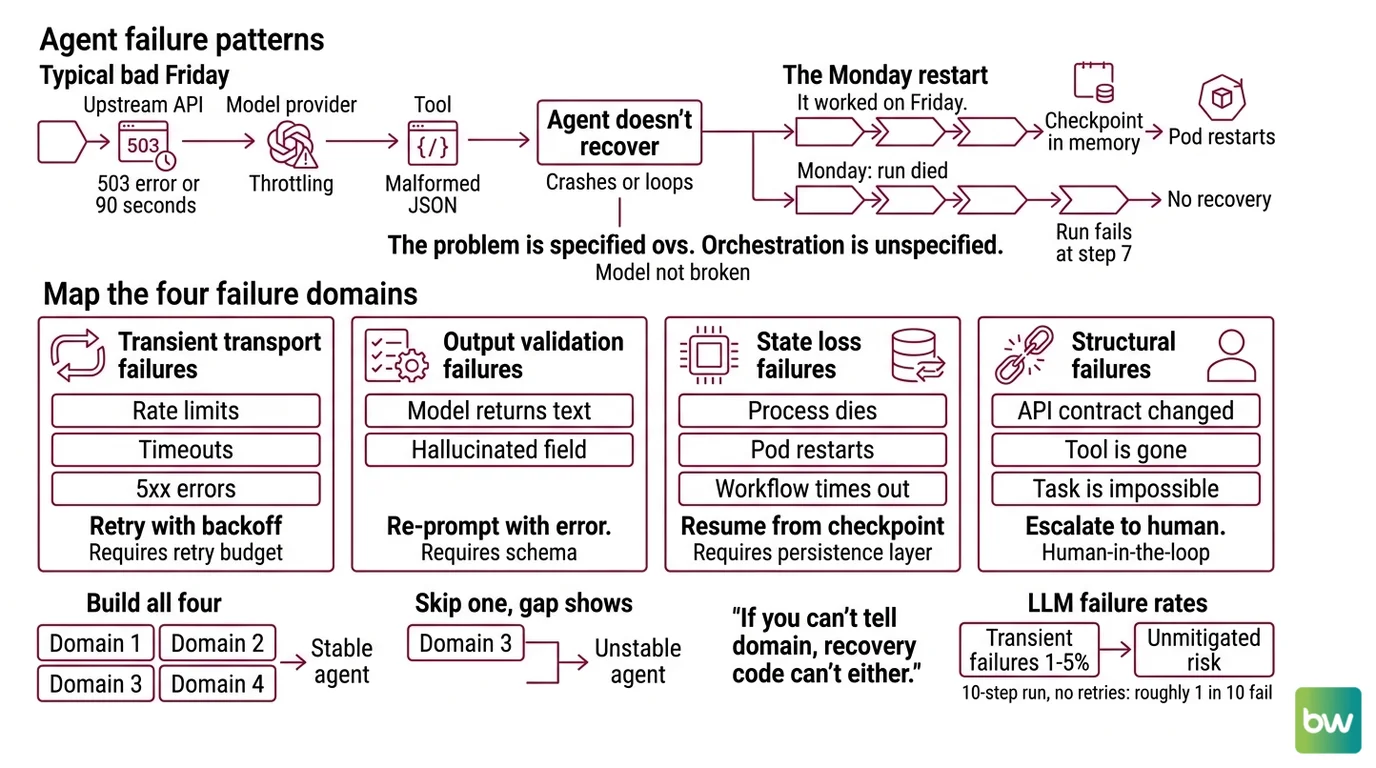
The agent worked all week. Monday morning the orchestrator wakes up, the rate-limit error returns, and the whole graph dies on step seven of twelve. Nobody saved the state. Nobody specified what “retry” meant. The pager goes off. This is the default outcome when Agent Error Handling And Recovery is bolted on at the end instead of designed in.
Before You Start
You’ll need:
- A Python agent stack — LangGraph, Pydantic AI, or the OpenAI Agents SDK with Temporal
- Familiarity with Agent Evaluation And Testing so you can prove recovery actually works
- A clear picture of which failures are transient (retry), which are structural (fallback), and which need a human
This guide teaches you: how to decompose agent failure into four independent contracts — retry, validation, persistence, escalation — so each layer can be specified, tested, and replaced on its own.
Your Agent Won’t Survive a Bad Friday
You ship the agent. It demos beautifully. Then a real Friday hits — the upstream API returns 503 for ninety seconds, your model provider throttles you mid-call, one tool returns malformed JSON. The agent doesn’t recover. It crashes, or worse, it loops forever burning tokens on the same broken state.
It worked on Friday. On Monday, the run died at step seven because the checkpoint was in memory and the pod restarted.
That is the failure pattern this guide fixes. The model is not broken. The orchestration is unspecified.
Step 1: Map the Failure Domains
Before you pick a library, name the failures. Agents fail in four distinct ways, and each one needs a different fix. Mixing them up is why “add retries” never solves the problem.
Your system has these failure domains:
- Transient transport failures — rate limits, timeouts, 5xx errors. These resolve themselves. Retry with backoff.
- Output validation failures — the model returned text where you needed JSON, or hallucinated a field. Re-prompt with the error.
- State loss failures — the process dies, the pod restarts, the workflow times out. Resume from a checkpoint.
- Structural failures — the API contract changed, the tool is gone, the task is genuinely impossible. Escalate to a human.
The Architect’s Rule: If you can’t tell which domain a failure belongs to from the log line, your recovery code can’t either.
Each domain has its own contract. Transient failures need a retry budget. Validation failures need a schema and a re-prompt message. State loss needs a persistence layer. Structural failures need an escalation path — usually Human In The Loop For Agents. Build all four. Skip any one and the gap shows up at the worst possible time.
The industry baseline for transient LLM failures sits around one to five percent of calls (NeuralWired, ballpark only). That means a ten-step agent run without retries fails on roughly one call in twenty under normal load. Add a noisy upstream and the number gets worse fast.
Step 2: Specify Your Retry Contract
A retry policy is a spec, not a flag. Before you turn one on, write down what it actually means.
Retry contract checklist:
- Which exception classes count as transient — typed, not stringly matched
- Maximum retry count per call — not unlimited
- Backoff curve — exponential with jitter, starting around 100ms, capped at a ceiling
- Idempotency — every retried operation must produce the same outcome the second time
- Circuit breaker state — Closed, Open, Half-Open, with a clear threshold for tripping
- Fallback path — what happens after the budget runs out
Exponential backoff with jitter is the default pattern: double the wait each retry, add a small random offset so a fleet of agents doesn’t thunder back at the upstream the moment it recovers (Fastio). Pair it with a circuit breaker so a sustained outage trips the whole call site instead of hammering it for an hour.
For output validation — the second domain — the cleanest primitive in 2026 is the Pydantic AI output validator. Decorate an async function with @agent.output_validator and it receives the parsed output plus a RunContext (Pydantic AI Docs). If the output is wrong, raise ModelRetry(f'Invalid: {e}') and the LLM is re-prompted with that error message. Pydantic AI 1.88.0 (released April 29, 2026, Pydantic AI Changelog) treats this as a first-class loop — output_retries defaults to one, settable per agent, per run, or per tool.
The Spec Test: If your output validator can’t tell the model why it failed, you don’t have self-correction. You have a retry counter dressed up as one.
That is the difference between “the call failed, try again” and a Agent Guardrails layer that turns each failure into a corrective signal.
Step 3: Layer Persistence and Workflow Durability
Retries handle the call. Persistence handles the run. They are separate concerns and they belong in separate libraries.
Build order:
- Output validators first — Pydantic AI
@agent.output_validatorwith a tight retry budget. This is the cheapest layer to add and it catches the most common failure class in isolation. - In-graph persistence next —
LangGraph checkpointers save state at every superstep so a crash mid-graph doesn’t replay successful sibling nodes. Pick the saver that matches your storage:
InMemorySaverfor tests,SqliteSaver/AsyncSqliteSaverfor local,PostgresSaver/AsyncPostgresSaverorCosmosDBSaverfor production, and AWS’s maintainedDynamoDBSaverif you live in that stack (LangChain Docs). - Workflow durability last — Temporal wraps the whole agent in a workflow process that survives infrastructure failure. The OpenAI Agents SDK integration went GA in the Python SDK on March 23, 2026 (Temporal Blog), and Pydantic AI ships a
TemporalAgentwrapper plus aPydanticAIWorkflowbase class for the same pattern.
For each layer, your spec must answer:
- What state must be durable across a process restart
- What inputs map to a stable key — for LangGraph that is
thread_idinside theconfigurabledict; without it, the checkpointer cannot save or resume (LangChain Docs) - What gets re-executed on resume versus replayed from history — LangGraph’s “pending writes” semantics make successful sibling-node outputs durable so they don’t re-run
- What must NOT happen on retry — non-idempotent side effects, double-charging, duplicate emails
The two layers complement each other. Checkpointers give you replayable graph state. Temporal gives you a workflow that survives the host. If your run is short and lives inside one process, LangGraph alone is enough. If the run spans hours, calls external services, or has to survive a deploy, wrap it in a Temporal workflow and expose your activities as tools through activity_as_tool, which auto-generates the OpenAI-compatible tool schema from the activity signature (Temporal Docs).
There is a real industry debate here — Diagrid argues that checkpointers alone are not durable execution because they recover state but not the in-flight call. That is a vendor viewpoint, not consensus, but it points at the right question: what happens to the half-finished tool call when the pod dies? Decide before you ship.
Security & compatibility notes:
langgraph-prebuilt1.0.2: Introduced aruntimeparameter without proper version constraints and broke custom prebuilt implementations. Pin to a known-good version and review the tracking issue before upgrading.- Pydantic AI
NativeOutputretries: Currently include the fullValidationErrorinput on retry, which can balloon token usage on large outputs. Open issue, not yet fixed — keep validation messages compact until it lands.- API rename —
result→output: Pydantic AI deprecated theresult_*attribute names in favor ofoutput_*. Aliases still work but emit warnings — use the new names in new code.- Temporal & LangGraph versions: No specific minor-version pinning is verifiable from docs alone. Track “current stable” and lock in CI; do not name a version in your spec.
Step 4: Verify Recovery, Not Just Success
Most teams test the happy path and ship. That is how you discover at 3 AM that the retry decorator was applied to the wrong function. Recovery is its own surface and it needs its own tests.
Validation checklist:
- Kill-the-pod test — start a long run, terminate the worker mid-superstep, restart it. Failure looks like: the run restarts from scratch instead of resuming, or it replays a successful tool call that had side effects.
- 503-storm test — inject a sequence of upstream 503s shorter than the retry budget. Failure looks like: the agent gives up before the budget is spent, or it retries on a non-retryable error class.
- Malformed-output test — force the model to return invalid JSON once, then succeed. Failure looks like: the validator catches it but the run fails anyway, meaning
output_retriesis set to zero. - Circuit-breaker trip — sustain a real outage past the breaker threshold. Failure looks like: the breaker never opens, or it opens and never closes after recovery.
- Escalation test — feed the agent a genuinely impossible task. Failure looks like: it loops on the retry budget instead of escalating to a human.
Pair these tests with Agent Observability so you can actually see which contract fired on which call. A retry counter with no tracing is a black box. A retry counter wired to traces tells you whether your spec is matching reality.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
Wrapped the whole agent in one try/except and called it “retries” | No retry budget, no backoff, no exception filtering — non-transient errors retried forever | Specify exception classes, max attempts, and exponential backoff per call site |
Used InMemorySaver in production | State lost on every pod restart; “durable” runs were not durable | Move to PostgresSaver, DynamoDBSaver, or a Temporal workflow for real persistence |
Set output_retries=0 because retries felt risky | Validator catches malformed output, run fails immediately — no self-correction | Use the default output_retries budget and let ModelRetry re-prompt with the error |
| Mixed transient and structural failures | Real outages tripped the breaker; impossible tasks burned the retry budget | Separate exception hierarchies — retry transient, escalate structural |
Skipped the thread_id in configurable | LangGraph silently ran without persistence; checkpointer was a no-op | Always pass thread_id; assert it is set in your graph entrypoint |
Pro Tip
Every retry contract has a partner: the idempotency contract. Before you add a retry anywhere, ask one question — if this call runs twice, does anything bad happen? If the answer is yes, you do not have a retry problem. You have a side-effect problem. Make the operation idempotent first — natural keys, deduplication tokens, conditional writes — and only then add the retry on top. This single discipline prevents the most expensive class of agent bug: the duplicate-action incident that no log will explain.
Frequently Asked Questions
Q: How to implement retry with backoff and self-correction loops in an AI agent?
A: Treat them as two layers. Wrap transport calls in exponential backoff with jitter, filtered by typed exception classes. For self-correction, use a Pydantic AI @agent.output_validator that raises ModelRetry(error_message) so the model re-runs with the exact failure reason.
Q: How to use LangGraph checkpointers and Temporal for durable agent execution?
A: Use them in layers, not as alternatives. LangGraph checkpointers (Postgres, DynamoDB) persist graph state between supersteps so crashes resume cleanly. Temporal wraps the whole agent in a workflow that survives infrastructure failure. Always set thread_id or the checkpointer silently no-ops.
Q: How to use Pydantic AI validators as a pre-execution shield for agent outputs?
A: Define a Pydantic model for the output and decorate an async function with @agent.output_validator. The validator receives the parsed output plus a RunContext and can hit databases or check business rules. Raise ModelRetry for recoverable errors, plain exceptions for structural ones.
Your Spec Artifact
By the end of this guide, you should have:
- A failure-domain map naming which exceptions in your code are transient, which are validation, which are state loss, and which are structural
- A retry contract per call site with backoff curve, budget, idempotency strategy, and circuit-breaker threshold
- A validation matrix listing the recovery tests above with pass criteria for each
Your Implementation Prompt
Drop this into Claude Code, Cursor, or Codex once you have your failure-domain map. The prompt mirrors the four steps and asks the AI to fill in the specification, not write the framework code for you.
You are designing the error-handling layer for a production AI agent.
Stack: [your agent framework — LangGraph / Pydantic AI / OpenAI Agents SDK]
Persistence: [your checkpointer — Postgres / DynamoDB / Cosmos / Temporal workflow]
Observability: [your tracing layer — Logfire / OpenTelemetry / Langfuse]
Step 1 — Failure domains
Classify each of the following exceptions into one domain (transient,
validation, state loss, structural):
[paste your current exception list]
Step 2 — Retry contract per call site
For each call site below, specify:
- exception classes that count as transient: [list]
- max attempts: [number]
- backoff: exponential with jitter, base [ms], cap [ms]
- idempotency strategy: [natural key / dedup token / conditional write]
- circuit-breaker threshold: [failures over window]
Call sites: [paste your list]
Step 3 — Persistence layer
Specify:
- checkpointer implementation: [class name]
- thread_id derivation: [how it is computed from input]
- state that must survive process restart: [list]
- state that must NOT be replayed on resume: [list — non-idempotent effects]
Step 4 — Validation
Write recovery tests for each of:
- kill-the-pod mid-superstep
- 503 storm shorter than budget
- malformed model output → ModelRetry → success
- circuit-breaker trip and recovery
- impossible-task escalation to a human
Output: a single markdown spec document with one section per step.
Do NOT generate framework code. Generate the specification only.
Ship It
You now have a four-layer model for agent failure: retry, validate, persist, escalate. Each layer is a separate contract you can specify, test, and replace. The next time someone tells you their agent “just needs retries,” you will know which layer they actually mean — and which three they forgot.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors