How to Implement Multi-Head Attention in PyTorch and Visualize Attention Patterns
Table of Contents
TL;DR
- Multi-head attention has four components — projection, splitting, scaled dot-product, and concatenation. Specify each one separately or the AI merges them wrong.
- Your context must pin PyTorch version, head count divisibility, and mask shape — three values the model will guess incorrectly every time.
- Attention weight visualization is a validation tool, not a feature. Specify what patterns you expect before you look at the heatmap.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex)
- Understanding of the Attention Mechanism and Query Key Value projections
- PyTorch 2.10+ installed (Python 3.10-3.14 supported, per PyPI)
- Familiarity with Transformer Architecture and how Linear Attention variants differ from standard scaled dot-product
- A clear picture of whether you’re building from scratch or wrapping
nn.MultiheadAttention
This guide teaches you: how to decompose multi-head attention into specifiable components so your AI tool generates dimensionally correct, debuggable implementations — not hallucinated tensor shapes that crash silently.
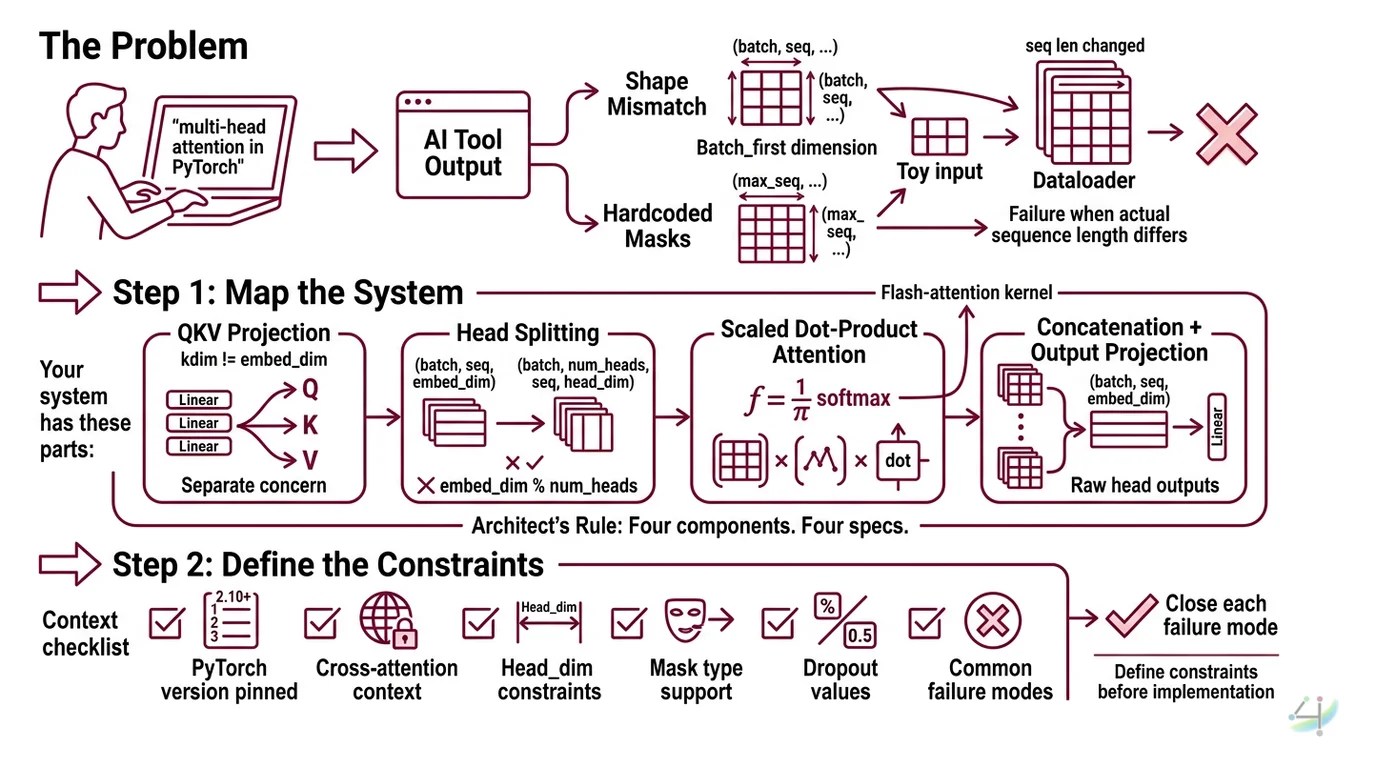
The Problem
You type “implement multi-head attention in PyTorch” into your AI tool and get something that looks right. Linear layers, a
Softmax, matrix multiplications. You run it. Shapes mismatch on the second forward pass because nobody told the AI whether batch_first was True or False.
It worked with your toy input. It died on your actual dataloader because the sequence length changed and the mask shape was hardcoded.
Step 1: Map the System
Multi-head attention isn’t one operation. It’s four operations pretending to be one. Your spec needs to separate them or the AI will fuse steps that shouldn’t be fused.
Your system has these parts:
- QKV Projection — three linear layers (or one packed projection) mapping input embeddings to query, key, and value spaces. Separate concern because
kdimandvdimcan differ fromembed_dimin cross-attention. - Head Splitting — reshaping projected tensors from
(batch, seq, embed_dim)to(batch, num_heads, seq, head_dim). This is where dimension bugs live. Ifembed_dim % num_heads != 0, everything downstream is garbage. - Scaled Dot-Product Attention — the actual softmax(QK^T / sqrt(d_k))V computation. PyTorch 2.10 routes this through
torch.nn.functional.scaled_dot_product_attentioninternally, which selects optimized kernels including Flash Attention when available (PyTorch Docs). - Concatenation + Output Projection — heads get concatenated back to
(batch, seq, embed_dim)and pass through a final linear layer. Skip this in your spec and the AI will return raw head outputs.
The Architect’s Rule: Four components. Four specs. One missing dimension constraint and you get a
RuntimeErrorat inference, not at init.
Step 2: Define the Constraints
Every multi-head attention implementation has the same failure modes. Your spec must close each one before the AI writes a single line.
Context checklist:
- PyTorch version pinned (2.10+ for built-in SDPA support)
embed_dimandnum_headsspecified, with assertion thatembed_dim % num_heads == 0batch_firstflag explicit —Truefor(batch, seq, embed_dim),Falsefor(seq, batch, embed_dim). The default isFalse(PyTorch Docs). Miss this and your data flows through transposed.- Mask type declared:
attn_mask(additive, float) vs.key_padding_mask(boolean). They are not interchangeable. - Dropout value specified for training vs. inference behavior
- Cross-attention vs. self-attention declared — determines whether Q comes from one source and K, V from another
need_weightsflag set —Truereturns attention weights for visualization,Falselets SDPA use fused kernels that skip weight materialization
The Spec Test: If your context doesn’t specify
batch_first, the AI will default toFalseand your(batch, seq, dim)tensors will silently produce wrong attention maps — no error, just incorrect output.
Step 3: Sequence the Build
Order matters. Build the math first, then wrap it.
Build order:
- Scaled dot-product function first — pure math, no parameters, easy to test. Input: Q, K, V tensors + optional mask. Output: attention output + weights. This is your ground truth.
- Head splitting logic next — reshape and transpose utilities. Test with known dimensions before connecting to projections.
- QKV projections third —
nn.Linearlayers with correctin_featuresandout_features. This is wherekdim/vdimfor cross-attention get wired. - Full module last —
nn.Modulewrapping all three, withforward()signature matching your data pipeline’s tensor layout.
For each component, your context must specify:
- Input tensor shape (batch, seq, dim — with actual placeholder values)
- Output tensor shape (explicitly, not “same as input”)
- What it must NOT do (no in-place operations on attention weights if you need gradients)
- How to handle failure (assert on dimension mismatches at init, not forward)
Step 4: Validate
Don’t eyeball tensor shapes in a print statement. Specify what correct looks like.
Validation checklist:
- Dimension roundtrip — input shape equals output shape after full forward pass. Failure looks like: output is
(seq, batch, dim)when you expected(batch, seq, dim)becausebatch_firstwas wrong. - Attention weight sum — each row of attention weights sums to 1.0 (within float tolerance). Failure looks like: weights sum to sequence length because you applied softmax on the wrong axis.
- Mask effectiveness — padded positions produce zero attention weight. Failure looks like: padding tokens influence output embeddings, degrading downstream performance silently.
- Gradient flow — backward pass produces non-zero gradients on all projection weights. Failure looks like: one head’s projection has zero gradient because of a detach or in-place op.
- Kernel selection — with
need_weights=False, verify SDPA selects the fused kernel (Flash or memory-efficient). Failure looks like: training runs slower than expected because it fell back to the naive implementation.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| “Implement multi-head attention” | AI fused all four components, hardcoded dimensions | Decompose into projection, split, SDPA, concat |
No batch_first specified | AI defaulted to False, your data was (batch, seq, dim) | Explicitly state tensor layout in context |
| Asked for “attention visualization” alongside implementation | AI materialized weights in the forward pass, broke fused kernel | Separate implementation spec from visualization spec |
| Skipped mask type declaration | AI generated key_padding_mask when you needed attn_mask | Declare mask type and shape in constraints |
| “Use Flash Attention” without version pin | AI generated FlashAttention-1 API that doesn’t exist in flash-attn 2.8.3 | Pin flash-attn version and specify SDPA path |
Pro Tip
Separate your implementation spec from your visualization spec. The moment you ask for attention weights in the same prompt as a high-performance implementation, the AI will write code that materializes the full attention matrix on every forward pass. That kills memory efficiency and disables fused SDPA kernels. Two specs. Two prompts. One for the fast path, one for the debug path.
Frequently Asked Questions
Q: How to implement multi-head attention in PyTorch from scratch?
A: Decompose into four components: QKV linear projections, head reshape, scaled dot-product with mask support, and output concatenation. Specify embed_dim, num_heads, and batch_first in your AI prompt context. The critical spec most tutorials skip: assert embed_dim % num_heads == 0 at init, not at runtime — otherwise dimension bugs surface only on specific input shapes.
Q: How to use nn.MultiheadAttention in PyTorch for a custom model?
A: Pass embed_dim and num_heads to the constructor, then call forward(query, key, value) with need_weights=True to get attention maps. The module returns (attn_output, attn_weights) (PyTorch Docs). Watch for: batch_first defaults to False, so if your dataloader yields (batch, seq, dim), set batch_first=True or your outputs will be silently wrong.
Q: How to visualize attention weights and interpret attention patterns?
A: Extract weights from forward() with need_weights=True, then use matplotlib heatmaps or BertViz for interactive views. BertViz offers head view, model view, and neuron view (BertViz GitHub). The interpretation trap: high attention weight on a token does not mean that token caused the output. It means the query found that key relevant — which is correlation, not causation. Always compare against a baseline mask.
Your Spec Artifact
By the end of this guide, you should have:
- Component map — four-part decomposition (QKV projection, head split, SDPA, concat+output) with dimension annotations for your specific
embed_dimandnum_heads - Constraint checklist — pinned values for
batch_first, mask type, dropout,need_weights, cross-attention vs. self-attention, and PyTorch version - Validation criteria — five checks (dimension roundtrip, weight sum, mask effectiveness, gradient flow, kernel selection) with expected outputs and failure symptoms
Your Implementation Prompt
Copy this into Claude Code, Cursor, or your AI coding tool. Fill the bracketed placeholders with your values from Steps 1-4.
Build a multi-head attention module in PyTorch 2.10+ with these specs:
COMPONENT 1 — QKV Projection:
- embed_dim: [your embed_dim, e.g. 512]
- num_heads: [your num_heads, e.g. 8]
- Attention type: [self-attention / cross-attention]
- If cross-attention: kdim=[value], vdim=[value]
- Three separate nn.Linear layers (no packed projection)
- Assert embed_dim % num_heads == 0 in __init__
COMPONENT 2 — Head Splitting:
- Input layout: batch_first=[True/False]
- Reshape (batch, seq, embed_dim) → (batch, num_heads, seq, head_dim)
- head_dim = embed_dim // num_heads
COMPONENT 3 — Scaled Dot-Product:
- Use torch.nn.functional.scaled_dot_product_attention
- Mask type: [attn_mask (additive float) / key_padding_mask (boolean)]
- Mask shape: [your mask dimensions]
- dropout_p: [your value, e.g. 0.1 for training]
- is_causal: [True for autoregressive / False for bidirectional]
COMPONENT 4 — Concatenation + Output:
- Concatenate heads back to (batch, seq, embed_dim)
- Final nn.Linear(embed_dim, embed_dim) output projection
VALIDATION:
- Assert output.shape == input.shape after forward pass
- Assert attn_weights rows sum to 1.0 (when need_weights=True)
- Assert padded positions get zero attention weight
- No in-place operations on tensors that need gradients
Return the module as a single nn.Module subclass with type hints.
Ship It
You now have a decomposition framework for multi-head attention that separates projection, splitting, computation, and concatenation into independently specifiable components. Next time you ask an AI tool to build attention, you won’t get a black box. You’ll get four contracts, each one testable, each one debuggable.
Compatibility notes:
- BertViz (v1.0.0): Last PyPI release was February 2021. The repo appears maintained but may have compatibility issues with the latest HuggingFace transformers versions. Test against your transformer version before integrating into a visualization pipeline.
- nn.MultiheadAttention deprecation discussion: An open GitHub issue (#122660, March 2024) proposes deprecation in favor of SDPA and composable transformer blocks. No timeline has been set — the module remains fully supported in PyTorch 2.10. For new projects, consider building directly on
torch.nn.functional.scaled_dot_product_attention.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors