How to Generate Synthetic Data with SDV, Gretel, and MOSTLY AI in 2026
TL;DR
- Synthetic data is only as good as the spec — name the correlations that carry your signal before you generate a single row.
- Pick the tool for its access model, not its hype: SDV is the open, pip-installable anchor; Gretel and MOSTLY AI are platforms whose branding moved in 2025–2026.
- Validate on three axes — fidelity, privacy, and downstream utility — or you ship data that looks real and trains nothing.
You exported 800 rows of customer data, ran them through a synthetic data tool, and got 50,000 shiny new rows back. The histograms matched. The averages matched. Then your fraud model — trained on the synthetic set — scored worse than the one trained on the original 800. The tool preserved every average and dropped the thing that mattered: the rare co-occurrences that flagged fraud. Nobody told it those had to survive.
Before You Start
You’ll need:
- A synthetic data tool —
Synthetic Data Vault (SDV) is the safe default; it’s a single
pip install sdvaway and runs entirely on your own machine. - A real dataset you actually understand — its schema, its column types, and the relationships that carry the signal.
- A clear answer to one question: are you optimizing for fidelity, for privacy, or for both? You cannot max all three of fidelity, privacy, and volume at once.
This guide teaches you: how to specify a Synthetic Data Generation job — source profile, fidelity contract, privacy budget, validation criteria — so the tool produces data you can train on instead of data that merely looks plausible.
The 50,000 Rows That Trained Nothing
Most synthetic data failures are not tool failures. They are specification failures. Someone points a generator at a table, clicks run, and assumes “looks like the original” means “behaves like the original.” A generator optimizes for what you measure it against — and if you never name which correlations matter, it optimizes for the easy ones: the single-column distributions.
It worked in the demo on Friday. On Monday the downstream model degraded, because the one cross-column dependency the business ran on was never specified as a constraint, so the synthesizer averaged it away.
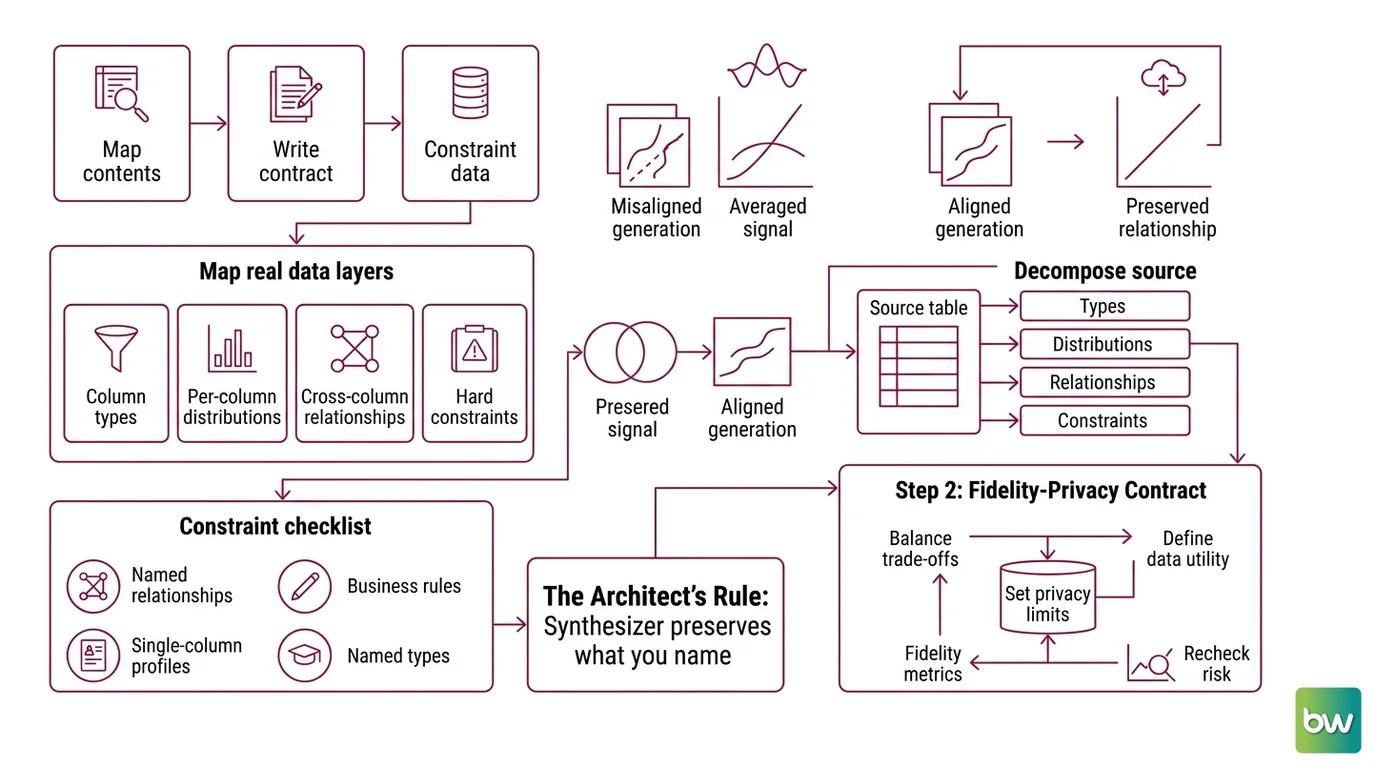
Step 1: Map What Your Real Data Actually Contains
Before you generate anything, decompose the source. A table is not one thing — it’s four layers stacked on top of each other, and a synthesizer models each one differently. If you can’t name the layers, you can’t tell the tool which ones to protect.
Your dataset has these layers:
- Column types — categorical, numerical, datetime, ID. Each is modeled differently, and mislabeling one (an ID treated as a number) corrupts everything downstream.
- Per-column distributions — the shape of each variable on its own. The layer every tool gets right.
- Cross-column relationships — the correlations and conditional dependencies that carry your actual signal. The layer that gets dropped.
- Hard constraints — business rules that must never break:
age >= 0,end_date > start_date, postal codes that match cities.
The Architect’s Rule: A synthesizer can only preserve what you can name. Every relationship you leave unspecified is the first thing it averages into noise.
The output of this step is not code. It’s a written profile — one line per column, plus an explicit list of the relationships that, if broken, make the data useless. That list is the spine of everything that follows.
Step 2: Write the Fidelity-Privacy Contract
This is where most guides hand you a tool and skip the thinking. Wrong order. Before you choose a synthesizer, write the contract it has to satisfy. The contract decides the tool — not the other way around.
Context checklist:
- Synthesizer class chosen, with a reason — statistical or deep learning.
- Fidelity targets defined — which marginal distributions and which correlations must match the original.
- Privacy budget set — none, or a formal Differential Privacy guarantee.
- Constraints listed — every business rule the output must satisfy.
- Volume specified — how many rows, and why that number serves your downstream task.
On the synthesizer choice, SDV gives you a clean menu: a GaussianCopulaSynthesizer for fast statistical modeling, CTGAN and TVAE for deep-learning fidelity on complex distributions, and PAR for sequential data, per SDV Docs. CTGAN — a conditional GAN built for tabular data — is the one to reach for when your columns have messy, multi-modal distributions that a copula smooths over. It costs more compute and buys more fidelity. Your contract should state which side you’re paying for.
On privacy: if you need a formal guarantee, differential privacy is the mechanism, and the epsilon parameter is your dial — lower epsilon means stronger privacy and lower fidelity. Pick the number deliberately and write it in the spec. Don’t let it default.
The Spec Test: If your contract doesn’t name the correlations that must survive, the synthesizer will preserve the marginals, pass a superficial eyeball check, and silently flatten the dependency your model was trained to detect.
Step 3: Sequence the Generation Run
Order matters, and not for style reasons. Each stage depends on the output of the one before it, so getting the sequence wrong produces errors that look like data problems but are really ordering problems.
Build order:
- Build and validate the metadata first — because the synthesizer needs correct column types and key definitions before it can model anything. A datetime read as a string poisons every later stage.
- Fit the synthesizer on the real data next — because sampling is meaningless until a model is trained on the true joint distribution.
- Sample, then enforce constraints last — because volume and business rules are the final shaping step, applied after the model exists.
For each stage, your context must specify:
- What it receives (inputs)
- What it returns (outputs)
- What it must NOT do (constraints — e.g., never emit a row violating a hard rule)
- How to handle failure (a constraint violation should be rejected and resampled, not patched)
This is also where you choose the platform, and in 2026 the access model matters as much as the algorithm. SDV — maintained by DataCebo, the team that spun out of MIT’s Data to AI Lab, per SDV’s GitHub repository — is the independent, open library you can run today. Gretel and MOSTLY AI are platform/SDK options — powerful, but their ownership and access flows shifted recently, so verify before you wire either into a spec. The MOSTLY AI open-source Synthetic Data SDK runs locally under an Apache v2 license, on its TabularARGN model with optional differential-privacy settings, according to the MOSTLY AI Blog — a genuine pip-installable option outside SDV.
Tool status notes (as of mid-2026):
- Gretel is no longer a standalone startup — NVIDIA acquired it for upwards of $320 million (announced March 2025) and folded its roughly 80-person team into its generative-AI services, per TechCrunch. Older tutorials that reference a standalone Gretel free tier or console may no longer apply; confirm current access before building it into a spec.
- MOSTLY AI brand and assets moved to Syntho in June 2026; sign-up flows and URLs now route through “MOSTLY AI, powered by Syntho,” according to Syntho. Re-check any console walkthrough you find.
- SDV is actively maintained — version 1.37.1 shipped June 11 2026, supporting Python 3.9 through 3.14, per SDV’s PyPI page — and remains the reliable, freely pip-installable anchor.
Step 4: Prove the Synthetic Data Is Safe to Train On
Generation is the easy half. Validation is where you find out whether you built training data or a convincing decoy. Run all three checks — fidelity alone is the trap that produced the 50,000 useless rows.
Validation checklist:
- Statistical fidelity — failure looks like: marginal distributions match column by column, but the named correlations from Step 1 collapsed.
- Privacy leakage — failure looks like: synthetic rows that are near-duplicates of real individuals, so the “synthetic” data quietly re-publishes your source records.
- Downstream utility — failure looks like: a model trained on synthetic data and tested on real data scores far below one trained on real data. This “train on synthetic, test on real” gap is the single most honest number you can report.
Common Pitfalls
| What You Did | Why The Tool Failed | The Fix |
|---|---|---|
| Pointed a generator at the table and clicked run | Too many implicit goals; it optimized the easy single-column distributions | Profile the four layers first, then name the correlations that must survive |
| Eyeballed the histograms and called it done | Marginals can match while every cross-column dependency is destroyed | Validate downstream utility with train-synthetic-test-real, not by sight |
| Left the privacy budget on default | No formal guarantee means synthetic rows can mirror real individuals | Set an explicit differential-privacy epsilon or document that none is needed |
| Copied a 2024 Gretel tutorial verbatim | Gretel’s standalone access changed after the NVIDIA acquisition | Confirm current tool ownership and access before writing it into the spec |
Pro Tip
The validation step transfers to every future job. Whatever generator you use, whatever the column count, the train-synthetic-test-real gap is your universal acceptance gate: train a simple model on the synthetic data, test it on held-out real data, and compare against the same model trained on real data. Small gap, real signal. Large gap, decoration. The number doesn’t care which tool produced the rows — which is exactly why it’s the one to automate first.
Frequently Asked Questions
Q: How to generate synthetic data step by step? A: Profile the source into four layers, write a fidelity-privacy contract, sequence the run (metadata, fit, sample-and-constrain), then validate on fidelity, privacy, and utility. One detail guides skip: build and check the metadata object before fitting — a single mistyped column, like a datetime read as text, silently corrupts every row the synthesizer produces afterward.
Q: How to use synthetic data to augment a small training dataset? A: Fit a synthesizer on your real minority cases, then sample extra rows of only those cases to rebalance the set. Watch out: this differs from Knowledge Distillation, where a model transfers learned signal. Augmentation cannot invent patterns the source lacks — with very few real examples, the synthesizer amplifies noise, so validate on real held-out data, never on synthetic.
Q: Best synthetic data generation tools for tabular data in 2026? A: SDV is the reliable open anchor — pip-installable, actively maintained at v1.37.1, with statistical and deep-learning synthesizers. MOSTLY AI’s open-source SDK runs locally too. Gretel is strong but now lives inside NVIDIA, so confirm its current access model before you commit. Match the tool to your access and privacy needs, not to a leaderboard.
Your Spec Artifact
By the end of this guide, you should have:
- A source profile — one line per column, plus a named list of the two or three relationships that must survive generation.
- A fidelity-privacy contract — chosen synthesizer, fidelity targets, privacy budget, hard constraints, and output volume with a reason.
- A validation plan — fidelity, privacy-leakage, and train-synthetic-test-real checks, each with the specific failure symptom you’re watching for.
Your Implementation Prompt
Paste this into your AI coding tool (Claude Code, Cursor, Codex) once you’ve filled the brackets with values from your spec artifact. It mirrors the four steps above, so the tool builds against your decomposition instead of guessing.
You are generating synthetic tabular data. Do not write throwaway code —
follow this specification and stop if any bracketed value is missing.
SOURCE PROFILE (Step 1):
- Dataset: [path or description of your real table]
- Column types: [each column -> categorical / numerical / datetime / id]
- Relationships that must survive: [the 2-3 correlations carrying the signal]
- Hard constraints: [business rules, e.g. age >= 0, end_date > start_date]
FIDELITY-PRIVACY CONTRACT (Step 2):
- Synthesizer: [GaussianCopula for speed / CTGAN or TVAE for complex distributions]
- Fidelity targets: [which marginals and correlations must match]
- Privacy budget: [none / differential privacy with epsilon = [your value]]
- Output volume: [number of rows and why this number]
BUILD ORDER (Step 3):
1. Build and validate metadata (column types, keys) before fitting.
2. Fit the synthesizer on the real data.
3. Sample [N] rows, then reject and resample any row breaking a hard constraint.
VALIDATION (Step 4):
- Report marginal-distribution similarity per column.
- Report whether each named correlation survived.
- Flag any synthetic row that is a near-duplicate of a real record.
- Train a simple model on synthetic, test on real, and report the gap.
Ship It
You now have a mental model that survives any tool change: synthetic data generation is a specification problem, not a button. Decompose the source, write the contract that names what must survive, sequence the run, and gate on the train-synthetic-test-real number. Do that, and the next branding shuffle costs you a tool swap — not a rewrite.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors