How to Generate High-Quality Unit Tests with Qodo Cover-Agent, Diffblue, and Claude Code in 2026
Table of Contents
TL;DR
- AI Test Generation is a build job, not a magic button — pick the engine that matches the language and the failure you are trying to catch.
- The original Qodo Cover-Agent CLI is archived. New projects in 2026 should target
qodo-ci(the GitHub Action) or Claude Code’s harness pattern, not the oldqodo-coverrepo. - Coverage is not the success criterion. A test that fails the day a real bug ships is the success criterion. Validate generated tests before you trust them.
A PR opens at 4:17 on a Thursday with thousands of new lines of generated unit tests. Coverage numbers jump into the celebration zone. Three weeks later production drops a NullPointerException and nobody can find a test that touches the path. The tests existed. They just tested the wrong thing. That is what unspecified AI test generation produces, and it is the exact failure mode this guide fixes.
Before You Start
You’ll need:
- One AI test generation engine —
qodo-ci, Diffblue Cover, or Claude Code (Step 1 tells you which) - A GitHub repository with admin rights (or an org owner willing to install the GitHub App)
- A working coverage tool already in CI —
pytest-covfor Python, JaCoCo or Cobertura for JVM,c8ornycfor JS/TS - Honest awareness of what your existing tests catch and what they miss — without this, “coverage went up” is the only signal you get
- Familiarity with how AI tooling reads diffs vs. whole repos — see AI Code Completion for the upstream side
This guide teaches you: how to decompose test generation into the four components the AI tool needs specified, then validate that the generated tests actually catch regressions instead of just hitting lines.
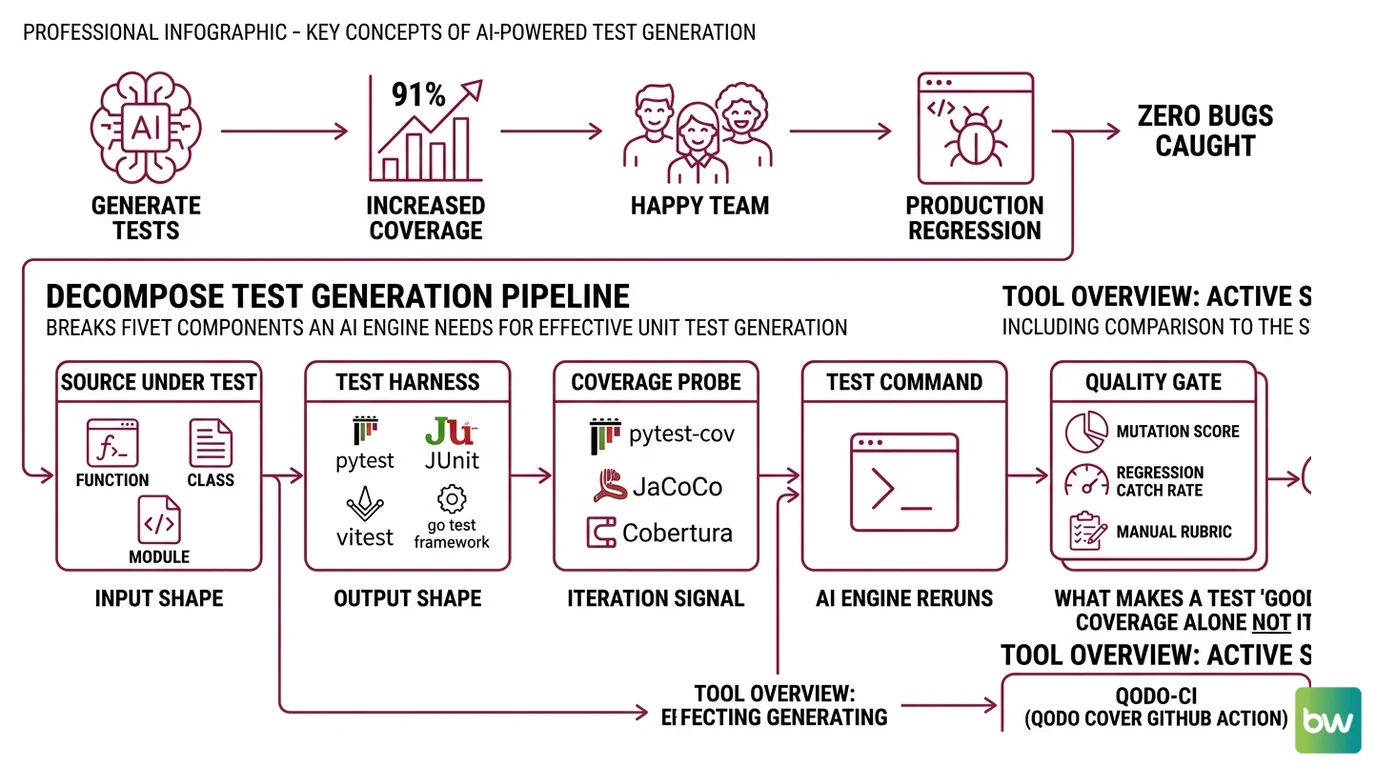
The 91% Coverage That Caught Zero Bugs
Most AI test rollouts die the same way. Someone runs Cover-Agent on a Python module on Friday. By Monday the repo has hundreds of new tests, coverage jumps from middling to celebration-zone, and the team is happy. By the next sprint, production catches a regression that none of the generated tests flagged because every one of them was an assert True derivative — they exercised lines without asserting behavior. The engineer who generated them never looked past the green check.
The model was fine. The harness was the problem. Nobody specified what a good test looked like, what counted as an acceptable assertion, or which classes of behavior the tests had to cover. The tool defaulted to “hit lines, pass quickly.” It did exactly that.
It worked on Friday. On Monday, the regression shipped because the only assertion was assert result is not None and None was never the bug.
Step 1: Decompose the Test Generation Pipeline
Before you pick a tool, decompose unit test generation into the components the AI engine actually needs. Each component is a separate concern, and each tool covers a different subset.
Your test generation pipeline has these parts:
- Source under test — the function, class, or module the test will exercise. Defines the input shape.
- Test harness — pytest, JUnit, vitest, go test — the framework the generated test plugs into. Defines the output shape.
- Coverage probe —
pytest-cov, JaCoCo, Cobertura — measures what the new tests actually exercised. Defines the iteration signal. - Test command — the literal shell command CI runs to execute the suite. The AI engine reruns this between iterations to know whether its draft passed.
- Quality gate — what makes a test “good.” Coverage alone is not it. Mutation score, regression catch rate, or a manual rubric belongs here.
The three tools split this surface very differently:
- qodo-ci (Qodo Cover GitHub Action) is the active successor to the archived Qodo Cover-Agent CLI. It runs as a workflow on GitHub Actions, supports Python, PHP, Java, Go, Kotlin, JavaScript, and TypeScript, and uses an
OPENAI_API_KEYGitHub repo secret for inference, per Qodo’s GitHub repository. Two modes —qodo-cover(manual dispatch, broad expansion across files) andqodo-cover-pr(PR-scoped, runs only on files modified in the PR). - Diffblue Cover is the outlier — Java/JVM only, and it does not use an LLM at all. It runs symbolic AI plus reinforcement learning to derive tests directly from bytecode, per Diffblue’s website. That is a fundamentally different engine. It produces deterministic tests that compile against your exact Maven or Gradle setup.
- Claude Code is general-purpose. Test generation is one of several jobs it can run. Its strength is the harness pattern — you write a
CLAUDE.mdat the repo root describing your test conventions, install the GitHub App with/install-github-app, and trigger generation by mentioning@claudein PRs or issues, per Claude Code Docs.
The Architect’s Rule: If you cannot describe what a “good test” looks like for your codebase in three sentences, the AI engine cannot generate one. Coverage is the easiest metric to satisfy and the worst proxy for quality.
Step 2: Lock the Spec Into a Config
Every rule the AI engine needs has to live in one place — and that place is not the prompt you typed in Slack last week. The location depends on the tool.
Config location by tool:
qodo-ci→ the workflow YAML at.github/workflows/qodo-cover.yml, plus theOPENAI_API_KEYrepo secret. The action exposessource-file-path,test-file-path,project-root,code-coverage-report-path,test-command,coverage-type(cobertura or jacoco),desired-coverage,max-iterations, andmodelas inputs — these are the CLI flags from the archived Cover-Agent, surfaced as workflow inputs, per Qodo’s GitHub repository.- Diffblue Cover →
pom.xmlorbuild.gradleplus a Diffblue config file. The engine reads your build system, not a separate prompt file. There is no API key to manage because there is no LLM call. - Claude Code →
CLAUDE.mdat the repo root. This file is auto-loaded by Claude Code in CI runs, per Claude Code Docs. Treat it as your test specification, not just a README.
Context checklist your spec must include:
- Test framework and version —
pytest 8.x with pytest-cov,JUnit 5 with Mockito 5,vitest 1.x. Without this, the engine guesses. - Coverage format — Cobertura or JaCoCo for qodo-ci, since those are the only two it parses today. JS/TS workflows need a Cobertura adapter from
c8ornyc. - What counts as a passing test — not just “it does not throw.” Assertion expectations, allowed test doubles, banned patterns like
assert Trueor emptyexpect()calls. - What the engine must NOT touch — generated code, vendored dependencies, snapshot files, fixtures.
- Iteration budget —
max-iterationsdefaults exist for a reason. A test that takes the engine fourteen rounds to make pass is usually a test that should not exist. Cap it.
The Spec Test: If a new engineer joins on Monday, reads only your
CLAUDE.mdor workflow YAML, and writes a unit test by hand, would it pass your review? If not, the spec is incomplete and the AI engine will produce worse tests than the engineer would have.
Step 3: Wire the Engine in the Right Order
Build order matters because each phase produces a signal the next one needs.
Build order:
- Pick one module first — never the whole repo. A single class or module with active churn but bounded blast radius. For Python on
qodo-ci, pointsource-file-pathat one file andtest-file-pathat the matching test file. For Diffblue, pick one Maven module. For Claude Code, scope the@claudemention to a single file with@claude write unit tests for src/payments/refund.py. - Wire the test command exactly as CI runs it — not a simplified version. If CI runs
pytest -m "not slow" --cov=src --cov-report=xml, that is the literal string the engine must use too. Any drift here produces tests that pass locally and fail in CI. - Run with a low desired coverage target first — start with a moderate target on
qodo-ci’sdesired-coverageinput, not a ceiling number. The engine spends most of its iterations chasing the long tail, and the long tail is usually the part that should be tested differently (integration, contract, property-based) rather than harder. - Inspect the first batch by hand — every generated test, line by line. The first generation tells you whether your spec is right. If the tests look like assertions written by a junior engineer who understood the requirements, the spec works. If they look like coverage-hitting noise, the spec is wrong.
- Iterate the spec, not the model — when a generation pass produces a bad test, do not switch models. Add the missing constraint to
CLAUDE.mdor the workflow inputs. The model is fine. The instructions are incomplete.
For each module, the engine’s context must specify:
- Source — the file, the class, the public surface to test
- Existing tests — so the engine extends rather than duplicates
- Forbidden patterns — empty assertions, monkeypatching production code, sleep-based timing tests
- Failure mode — what the engine does when it cannot reach the coverage target (commit a partial PR for human review vs. fail the workflow)
Security and licensing note: The original
qodo-ai/qodo-coverrepo was archived on June 15, 2025 — its last release was0.3.10on May 21, 2025. Forks may continue to work but receive no upstream fixes. The active path in 2026 isqodo-ai/qodo-ci(currentlyv0.1.12, in preview and free for a limited time). Pricing for the GA version has not been announced. Cover-Agent is AGPL-3.0; if AGPL is incompatible with your distribution model, that constraint sits with you, not with Qodo.
Step 4: Validate Before You Trust the Tests
You do not measure an AI test generator by coverage. You measure it by whether the generated tests catch the bugs you actually ship. That distinction is the whole reason this step exists.
Validation checklist:
- Mutation score, not line coverage — run a mutation tester (
mutmutfor Python, PIT for Java, Stryker for JS/TS) against the generated tests. Failure looks like: high line coverage, low mutation score. The tests touch lines but do not assert behavior. Throw them out. - Regression replay — take three real bugs your team shipped in the last quarter, revert each fix in isolation, and rerun the generated test suite. Failure looks like: bug returns, suite still green. The generator did not understand what mattered.
- Test quality review — sample twenty generated tests. For each, ask whether you would have approved it in a human PR. Failure looks like: more than three tests you would have rejected. The spec is producing noise.
- Time-to-CI-fail — when you intentionally break the source file, how long until a generated test fails? Failure looks like: silence. The tests do not exercise the path you broke.
- Flake rate — rerun the suite ten times against unchanged source. Failure looks like: any flakes at all. AI-generated tests with embedded timing assumptions are the most common source of flake — catch them before they pollute CI.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
Pointed qodo-ci at qodo-ai/qodo-cover for a new install | The repo is archived as of June 15, 2025 — readers land on stale CLI docs | Use qodo-ai/qodo-ci (the GitHub Action) for any 2026 install |
| Grouped Diffblue with the LLM-based tools when comparing | Diffblue uses symbolic AI on JVM bytecode, not an LLM — the trade-offs are inverted | Compare Diffblue on determinism, JVM-only scope, and zero LLM cost — not on prompt quality |
Set the desired-coverage ceiling high on the first run | Engine burned max-iterations chasing the long tail and produced low-value tests for trivial getters | Start with a moderate target, raise it only after you have validated the first batch |
| Treated coverage as the success metric | Suite hit a celebration-grade line number and shipped a regression on a path the tests “covered” without asserting behavior | Add a mutation tester (mutmut, PIT, Stryker) as a required CI gate |
Skipped CLAUDE.md and prompted in chat | Claude Code in CI had no team conventions, defaulted to its training bias, produced inconsistent test style | Commit CLAUDE.md at repo root — it is auto-loaded in CI runs, per Claude Code Docs |
Used qodo-cover mode on every PR | Workflow rewrote unrelated test files on small PRs; reviewers drowned in test diff | Use qodo-cover-pr mode for PR-scoped expansion, reserve qodo-cover for scheduled batch runs |
Pro Tip
Treat the AI test generator as one engineer on a team of three, not as the team. The generator’s job is to compress the surface area humans have to write — the boring assertions on happy paths and obvious error cases — so humans can spend their test-writing budget on what only humans can see: invariants, contracts, the property-based cases that catch a class of bugs instead of one. If you find yourself rewriting half the generated tests, the spec is wrong. If you find yourself accepting all of them without reading, the validation is wrong. Pick one to fix, in that order. The patterns compound. A CLAUDE.md that produces good Python tests today will produce good Go tests next quarter — once you have run the loop once.
Frequently Asked Questions
Q: How to use Qodo Cover-Agent to generate unit tests for a Python project in 2026?
A: Do not use the old qodo-ai/qodo-cover CLI — it was archived on June 15, 2025 with 0.3.10 as the final release, per Qodo’s GitHub repository. Instead, add the qodo-ai/qodo-ci GitHub Action to .github/workflows/qodo-cover.yml, set the OPENAI_API_KEY repo secret, and pick qodo-cover-pr mode for PR-scoped generation. Your Cobertura report path is the input that links the action to pytest-cov. Watch for the preview-pricing transition — the GA model has not been announced.
Q: How to build an AI test generation pipeline with Claude Code and GitHub Actions step by step?
A: Run /install-github-app from the Claude Code terminal to add the anthropics/claude-code-action app to your repo, then commit CLAUDE.md at the root with your test conventions — it is auto-loaded in CI runs, per Claude Code Docs. Trigger generation by mentioning @claude in a PR or issue. For bulk runs, route through the Anthropic Batch API to take the 50% input + output discount within the 24-hour async window, per Verdent Guides. Pro plan starts at $20/month ($17 annual).
Q: When should I use Diffblue Cover instead of an LLM-based test generator? A: Use Diffblue when your codebase is JVM (Java, Kotlin, Scala) and you need deterministic, repeatable tests that compile against your exact build. Diffblue runs symbolic AI plus reinforcement learning on bytecode — not an LLM — per Diffblue’s website. That means no prompt tuning, no token costs, no model drift between runs. Developer Edition is $30/month with 100 tests included, per the Diffblue Blog. Pick an LLM tool for multi-language repos or when test prose readability matters more than determinism.
Your Spec Artifact
By the end of this guide, you should have:
- A pipeline component map — five components (source, harness, coverage probe, test command, quality gate) labeled covered, partial, or human-owned for your chosen engine
- A committed spec file at the repo root —
CLAUDE.md, theqodo-ciworkflow YAML, or your Diffblue config — with test framework, coverage format, forbidden patterns, and iteration budget specified - A validation dashboard — mutation score, regression replay results, test quality review, time-to-CI-fail, flake rate — measured on one module before any repo-wide rollout
Your Implementation Prompt
Drop this into Claude Code or Cursor at the root of the repo where you are wiring the engine. It mirrors Steps 1-4 and forces every team-specific decision before any generation runs.
You are helping me wire an AI unit test generator into a single module
of a GitHub repository.
The engine is: [qodo-ci | Diffblue Cover | Claude Code]
The repository is: [repo name + primary language + framework + version]
The target module is: [single file or class path]
Generate the rollout spec in four sections.
Section 1 — Pipeline component map.
For each component (source under test, test harness, coverage probe,
test command, quality gate), mark it as: covered by engine / partial /
human-owned. Explain why each component fits or does not fit our engine.
Section 2 — Spec file content.
Produce the literal contents of the spec file the engine reads
([CLAUDE.md | .github/workflows/qodo-cover.yml | Diffblue config])
with these constraints filled in:
- Test framework and version: [pytest 8.x | JUnit 5 | vitest 1.x | ...]
- Coverage format: [cobertura | jacoco | ...]
- Test command (literal CI string): [pytest -m "not slow" --cov=src ...]
- Forbidden patterns: [empty assertions, sleep-based timing, ...]
- Files the engine must not touch: [generated/, fixtures/, vendored/]
- Iteration budget and desired-coverage target: [moderate target to start, e.g. a number well below the language norm]
Section 3 — Rollout order.
Produce the 5-step build order with the specific module I named, the
specific first PR I should open, and what a successful first batch
of generated tests looks like.
Section 4 — Validation plan.
List the five metrics (mutation score, regression replay, test quality
review, time-to-CI-fail, flake rate) with the specific failure threshold
that means I should NOT expand to the rest of the repo, and a 2-week
measurement plan.
Do not generate any tests yet. Do not invent constraints my team did
not specify. If something is missing from the inputs above, ask me
before guessing.
Ship It
You now have a way to look at AI test generation as four engineering decisions — decompose, spec, wire, validate — instead of one tool purchase. Pick the engine that matches your language and your determinism needs. Lock the spec into a file your team can read in three months. Validate by what the tests catch, not by what lines they touch. That is the whole loop, and once you have run it once on one module, the next engine rollout is a copy of the same playbook with a different vendor name.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors