How to Fine-Tune SigLIP 2, DINOv2, and ViT Backbones with Hugging Face and PyTorch in 2026
TL;DR
- Pick the backbone before you write a line of training code. Task shape, license, and native resolution decide it — not Twitter hype.
- Transformers v5 changed the idioms. Your 2025 fine-tune script will break on feature extractors, cache flags, and removed backends.
- Fine-tuning is PEFT LoRA on the attention projections plus a trainable head — a fraction of a percent of parameters, same accuracy class.
You ran your image-classification fine-tune on a Friday. Transformers v4.52. ViTFeatureExtractor. load_in_4bit=True. It shipped. Monday morning, CI upgrades to Transformers v5 and three imports fail, one silent conversion swaps resolutions, and your SigLIP 2 naflex checkpoint is behaving like a fixed-resolution model. Nothing is broken in the math. The spec is broken. This guide fixes that.
Before You Start
You’ll need:
- A Hugging Face account with an accepted license for any gated checkpoint
- A PyTorch install on CUDA or MPS — a single consumer GPU is enough for LoRA on Base-sized backbones
- A Transformers v5 environment and a labeled image dataset
- Working familiarity with the Vision Transformer architecture — Patch Embedding, Class Token, and the Inductive Bias trade-off against CNNs
This guide teaches you: how to pick a ViT backbone by specification rather than popularity, then wire a PEFT LoRA fine-tune that survives Transformers v5 without rewriting the training loop.
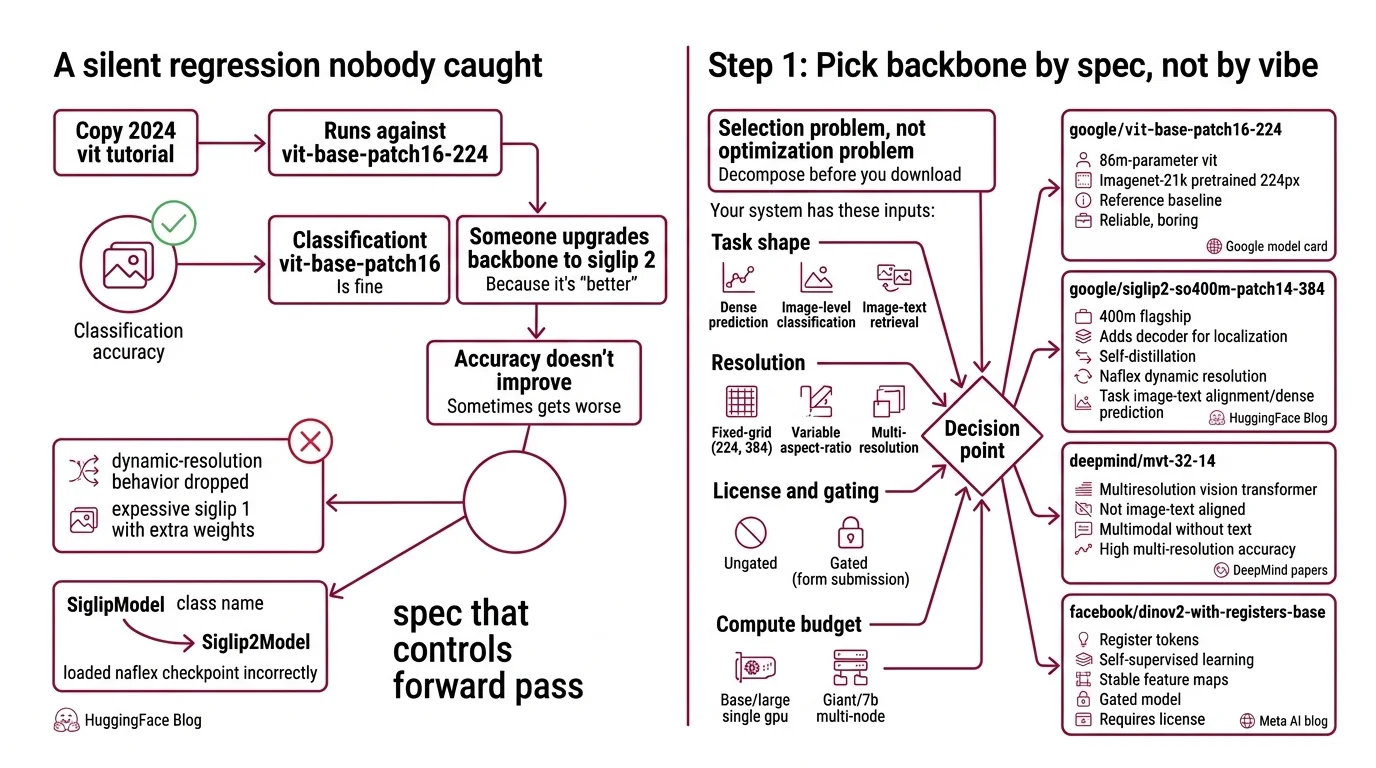
The Silent Regression Nobody Caught
Here’s the failure I see most weeks in 2026. A team copies a 2024 ViT fine-tune tutorial. Runs it against google/vit-base-patch16-224. Classification accuracy is fine. Next sprint, someone upgrades the backbone to SigLIP 2 because it’s “better.” The code still runs. Accuracy doesn’t improve. Sometimes it gets worse.
What changed? Nothing you can see. The team loaded a naflex checkpoint with SiglipModel instead of Siglip2Model — the dynamic-resolution behavior was silently dropped, and SigLIP 2 became an expensive SigLIP 1 with extra weights (HuggingFace Blog). A class name looks like a cosmetic detail. It isn’t. It’s the spec that controls which forward pass your inputs take.
Step 1: Pick the Backbone by Spec, Not by Vibe
Fine-tuning starts with a selection problem, not an optimization problem. Four backbones, four different decision criteria. Decompose before you download.
Your system has these inputs:
- Task shape — dense prediction (segmentation, retrieval patches) vs. image-level classification vs. image-text retrieval
- Resolution — fixed-grid (224, 384) vs. variable aspect-ratio and multi-resolution
- License and gating — ungated vs. gated with form submission
- Compute budget — Base or Large on a single GPU vs. Giant or 7B on multi-node
Now map the backbones against those inputs.
google/vit-base-patch16-224— the original 86M-parameter ViT, ImageNet-21k pretrained at 224px (Google model card). Boring. Reliable. The reference baseline when you need to prove a fine-tune works before you scale up.google/siglip2-so400m-patch14-384— the 400M flagship of the SigLIP 2 family, which also ships Base (86M), Large (303M), and a 1B Giant. SigLIP 2 adds a decoder for localization, self-distillation, and naflex variants for dynamic resolution (HuggingFace Blog). First pick when your task involves image-text alignment or dense prediction. It traces its lineage back to the CLIP Model — same dual-encoder idea, different loss and curriculum.facebook/dinov2-{small,base,large,giant}— Meta’s Self Supervised Learning workhorse. Four sizes from 21M to 1.1B parameters, embeddings from 384 to 1536 dimensions (Meta MODEL_CARD). Best choice when your downstream task is feature extraction or nearest-neighbor retrieval and you cannot afford gated licensing friction. Not the same family as a Masked Autoencoder — DINOv2 uses a discriminative SSL objective, not pixel reconstruction.facebook/dinov3-*— released August 2025, trained on roughly 1.7 billion images with a 7B-parameter teacher (Meta AI). Technically current SOTA for self-supervised features. Gated on Hugging Face — users must submit name, date of birth, country, and affiliation before downloading (DINOv3 model card). This guide still defaults to DINOv2 because gated weights break reproducible CI pipelines and onboarding.
The Architect’s Rule: If you can’t state the backbone’s task, license, and native resolution in one sentence, don’t fine-tune it.
Step 2: Lock the v5 Contract
Transformers v5.0.0 shipped on 2026-01-26 — the first major release in five years, and it broke a lot of idioms that 2024 and 2025 tutorials depend on (HuggingFace Blog). Before your training script compiles, your context has to state the v5 rules explicitly.
Context checklist for any 2026 ViT fine-tune:
- Transformers range: pin to
transformers>=5.0— don’t hard-pin a patch version, because v5 now ships minor releases weekly (HuggingFace Blog) - Python: 3.10 or newer (Transformers migration guide)
- Backend: PyTorch only — TF and Flax backends were removed in v5 (Transformers migration guide)
- Preprocessing class: use
AutoImageProcessor— the oldXXXFeatureExtractorclasses were removed (Transformers migration guide) - Quantization: if you need 4-bit or 8-bit, configure a
BitsAndBytesConfig— theload_in_4bitandload_in_8bitflags were removed (Transformers migration guide) - Cache env var:
HF_HOME, notTRANSFORMERS_CACHE(Transformers migration guide) - Model class: for SigLIP 2 naflex checkpoints,
Siglip2Model— never the genericSiglipModel, which silently drops the dynamic-resolution path (HuggingFace Blog) - Classification head:
SiglipForImageClassificationfor SigLIP 2 classification (Transformers docs)
The Spec Test: if any line of your training script uses
ViTFeatureExtractor,load_in_4bit=True,TRANSFORMERS_CACHE, orSiglipModelon a naflex repo, the v5 migration hasn’t actually happened yet — those are the four tells.
Security & compatibility notes:
- Transformers v5 breaking changes (2026-01-26): TF/Flax backends removed;
XXXFeatureExtractorreplaced byAutoImageProcessor;load_in_4bitandload_in_8bitreplaced byBitsAndBytesConfig;TRANSFORMERS_CACHEreplaced byHF_HOME; Python 3.10+ required. Migrate before pinning.- SigLIP 2 naflex: load with
Siglip2Model, notSiglipModel. Wrong class silently disables dynamic-resolution inputs.- DINOv3 gated access:
facebook/dinov3-*requires accepting the DINOv3 License (name, DOB, country, affiliation) on Hugging Face beforefrom_pretrainedwill succeed.
Step 3: Sequence the PEFT LoRA Build
In 2026, full fine-tuning is almost always wrong. PEFT with LoRA freezes the backbone, injects small adapter matrices into attention, and trains a new head — so you touch roughly 0.77% of the original parameters on a ViT-base (PEFT docs). Same accuracy class. Tiny checkpoint. Faster iteration.
Build order:
- Image processor first — load
AutoImageProcessor.from_pretrained(model_id). Spec the resize, center-crop, and normalize that the backbone expects. No custom transforms until this matches the pretraining pipeline. - Backbone second —
AutoModel.from_pretrained(model_id)with the right class (see Step 2). Freeze its parameters before you touch anything else. - LoRA adapter third — attach with a
LoraConfig. The reference template for ViT-family backbones isr=16, lora_alpha=16, target_modules=["query","value"], lora_dropout=0.1, modules_to_save=["classifier"](PEFT docs). Thatmodules_to_saveline is the spec that says “the classifier is new, so it’s fully trainable even though the rest is adapter-only.” - Trainer last —
Trainersetsmodel.use_cache=Falseby default during training in v5; don’t fight it (Transformers migration guide).
For each component, your context must specify:
- Input: the exact image tensor shape the processor produces (batch × channels × H × W) — naflex inputs are variable-size and need batched padding specified
- Output: logits for classification, pooled embedding for retrieval — pick one, don’t build a head that tries to do both
- Constraint: no gradient flow into frozen layers; LoRA adapters only on
queryandvalueunless you have a measured reason to addkeyor the MLP - Failure mode: a dataset smaller than the head dimension — the classifier overfits while the backbone stays still, and your eval curve looks great on train and flat on held-out
Use the PEFT library directly (the maintained huggingface/peft repo) rather than hand-rolling adapter insertion. The maintained path has the fewest sharp edges.
Step 4: Validate Before You Declare Victory
A fine-tune that “looks fine” on the first batch is the most common false pass I see. Validation has to hit the places the spec can break silently.
Validation checklist:
- Parameter-count check — call
model.print_trainable_parameters(). For a ViT-base with the reference LoRA config, trainable parameters should land near 0.77% of the total (PEFT docs). Failure symptom: a much higher percentage means the backbone isn’t frozen, and you’re full-fine-tuning at a learning rate that was tuned for adapters. - Resolution round-trip — run one batch through the processor, print the resulting tensor shape, compare it to the model card’s expected input. Failure symptom: a SigLIP 2 naflex checkpoint that outputs a fixed 384×384 tensor means you loaded
SiglipModelinstead ofSiglip2Model. - Embedding sanity — on a DINOv2 backbone, cosine-similarity two augmentations of the same image. Failure symptom: a similarity well below the pretrained baseline means the image processor’s normalization doesn’t match the backbone’s pretraining statistics.
- Split integrity — compare class distribution in train vs. eval and inspect the confusion matrix. Failure symptom: high accuracy driven by a single dominant class means your split leaked or your sampler is biased.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Copied a 2024 tutorial into a 2026 env | Used ViTFeatureExtractor — removed in Transformers v5 | Swap to AutoImageProcessor, re-run end-to-end |
Loaded SigLIP 2 naflex with SiglipModel | Generic class silently drops dynamic resolution | Use Siglip2Model for any naflex checkpoint |
| Full-fine-tuned a 1B Giant on a small labeled set | Under-data plus over-parameterization causes catastrophic forgetting | PEFT LoRA on query and value, backbone frozen |
| Reached for a Swin Transformer without a spec reason | Defaulted to hierarchical windows for a flat classification task | Use plain ViT or DINOv2; Swin earns its spot on dense prediction only |
Pro Tip
The spec discipline transfers. When you start evaluating a non-transformer backbone — a State Space Model variant, a ConvNeXt, a hybrid — the same four questions decide the build: what is the task shape, what is the native resolution, what is the license, what is the compute budget. The backbone changes. The decomposition doesn’t. Most future vision fine-tunes run the same playbook, and the playbook is what you’re really learning.
Frequently Asked Questions
Q: Which Vision Transformer backbone should I pick for production in 2026?
A: Start with SigLIP 2 so400m-patch14-384 for image-text tasks, DINOv2 base or large for retrieval and feature extraction, and the original vit-base-patch16-224 only when you need a regression-free baseline. Skip DINOv3 until your CI can handle gated licenses and an identity-disclosure step.
Q: How do I use a Vision Transformer for image classification and retrieval?
A: Use SiglipForImageClassification for classification heads and the raw Siglip2Model or Dinov2Model pooled output for retrieval embeddings. The detail most guides miss: center-cropping during preprocessing can destroy small objects — prefer resize-to-shortest-edge then fixed crop, tuned to your dataset.
Q: How do I fine-tune a Vision Transformer with PyTorch and Hugging Face?
A: Freeze the backbone, inject a LoRA adapter on query and value projections with r=16, mark the classifier as modules_to_save, and train with Trainer. For stability, add a warmup schedule — ViT fine-tunes are more sensitive to early-step learning rates than language models are.
Q: How do I implement a Vision Transformer from scratch step by step?
A: Don’t — not for production. Reference Dosovitskiy et al., “An Image is Worth 16x16 Words” for the patchify plus transformer-encoder plus class-token pattern, and re-implement it once as a learning exercise. Then load google/vit-base-patch16-224 so your fine-tune inherits ImageNet-21k pretraining instead of random weights.
Your Spec Artifact
By the end of this guide, you should have:
- A backbone decision map — task, license, resolution, compute — that pins one checkpoint per deployment slot
- A Transformers v5 context checklist — processor class, model class, quantization config, cache env var — ready to paste into your repo’s training spec
- A LoRA validation checklist — trainable-parameter ratio, resolution round-trip, embedding sanity, split integrity — that catches silent regressions before deployment
Your Implementation Prompt
Drop this into Claude Code, Cursor, or Codex when you’re ready to generate the fine-tuning script. It encodes Steps 1 through 4 as structured placeholders — replace the bracketed values with your own decisions before sending.
You are writing a PyTorch + Hugging Face Transformers v5 fine-tuning script
for a Vision Transformer backbone. Follow this specification exactly.
Step 1 — Backbone decision:
- Task shape: [classification | retrieval | dense-prediction]
- Chosen checkpoint: [e.g., google/siglip2-so400m-patch14-384]
- Model class: [Siglip2Model | SiglipForImageClassification | AutoModel]
- Native resolution: [e.g., 384 | naflex-dynamic]
- License status: [ungated | gated-license-accepted]
Step 2 — Transformers v5 contract:
- Transformers: transformers>=5.0
- Python: 3.10+
- Image processor: AutoImageProcessor.from_pretrained("<checkpoint>")
- Quantization: [none | BitsAndBytesConfig(load_in_4bit=True, ...)]
- Cache env: HF_HOME=[path]
- Do NOT use: ViTFeatureExtractor, load_in_4bit flag, TRANSFORMERS_CACHE,
SiglipModel on naflex checkpoints
Step 3 — PEFT LoRA build order:
1. Load AutoImageProcessor for the chosen checkpoint
2. Load backbone with frozen parameters (no grad)
3. Attach LoraConfig(r=16, lora_alpha=16,
target_modules=["query","value"], lora_dropout=0.1,
modules_to_save=["classifier"])
4. Train with Trainer (accept model.use_cache=False default)
Step 4 — Validation hooks in the same script:
- Print trainable parameter percentage; expect near [target%]
- Resolution round-trip: feed one batch, print tensor shape,
compare to model-card expected input
- Embedding sanity: cosine-similarity on two augmentations of one image
- Confusion matrix on eval split
Output: one runnable Python file. No Jupyter cells. No commented-out
deprecated APIs. Include a top-of-file docstring that restates the
backbone, license status, and v5 class choices from Step 1 and Step 2.
Ship It
You now have a decision framework for backbone selection by spec, not vibe, plus a v5-safe fine-tuning contract that won’t rot when the next weekly Transformers release lands. What you can decompose now that you couldn’t before: “should I use SigLIP 2, DINOv2, or plain ViT?” becomes four concrete questions with answers you can defend in a code review.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors