How to Fine-Tune and Deploy Sentence Transformers for Semantic Search and Clustering in 2026

Table of Contents
TL;DR
- Your loss function, not your base model, determines whether fine-tuned embeddings actually retrieve the right documents
- Matryoshka training lets you ship smaller vectors that retain most of the quality — specify the dimension budget before you train
- The pipeline has four specification layers (data, loss, model, index) and skipping any one produces garbage retrieval
You fine-tuned a sentence transformer on your domain data. Eval scores looked solid. You deployed it behind a FAISS index, ran your first production query, and the top results were irrelevant. The model wasn’t broken. You matched a symmetric loss function to an asymmetric retrieval problem. That mismatch is invisible in training metrics and catastrophic in production.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex)
- Familiarity with Embedding pipelines and Contrastive Learning fundamentals
- A dataset of domain-specific text pairs (or documents you can pair)
- Python 3.10+ environment with PyTorch installed
This guide teaches you: how to decompose the fine-tuning-to-deployment pipeline into four specification layers — data, loss, model, index — so each layer’s constraints prevent the next layer’s failures.
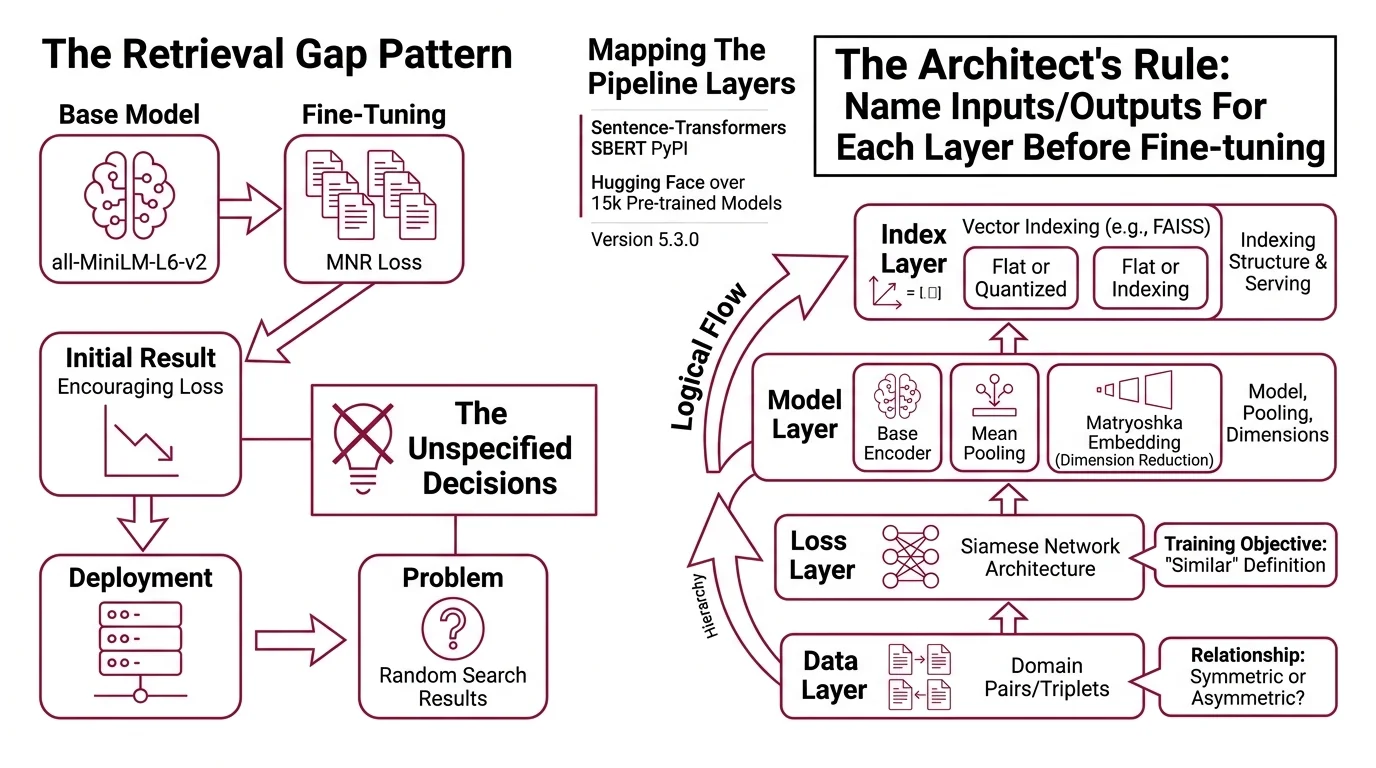
The Retrieval Gap Nobody Debugs
Here’s the pattern. Developer grabs all-MiniLM-L6-v2. Fine-tunes on internal docs with MultipleNegativesRankingLoss. Gets an encouraging training loss. Deploys. Wonders why search results feel random.
The problem isn’t the model. The problem is three unspecified decisions between the model and the user’s query.
The base model assumes symmetric similarity — “A is similar to B” means “B is similar to A.” But search is asymmetric. The query “how to reset password” and the document “Password Reset Procedure v3.2” are a match, but they don’t look alike. If you trained on symmetric pairs, you taught the model the wrong relationship.
That worked on Tuesday. On Thursday, a teammate added a batch of FAQ pairs to the training set — short questions mapped to long answers. Loss went down. Retrieval got worse. The asymmetric data fought the symmetric loss, and the embeddings learned nothing useful about either pattern.
Step 1: Map the Four Pipeline Layers
A Sentence Transformers pipeline isn’t one thing. It’s four decisions stacked on top of each other, and each one constrains the next.
Your system has these layers:
- Data layer — the pairs (or triplets) you train on, and whether the relationship is symmetric or asymmetric
- Loss layer — the training objective that teaches the Siamese Network architecture what “similar” means for your domain
- Model layer — the base encoder, the Mean Pooling strategy, and optionally a Matryoshka Embedding wrapper for dimension reduction
- Index layer — the Vector Indexing structure ( Faiss, flat or quantized) that serves the embeddings at query time
The Architect’s Rule: If you can’t name what each layer expects as input and delivers as output, you’re not ready to fine-tune.
The library ships with over 15,000 pre-trained models on Hugging Face (SBERT PyPI), and version 5.3.0 introduced alternative InfoNCE formulations with hardness weighting for MultipleNegativesRankingLoss (SBERT GitHub). Options are not the bottleneck. Specification is.
Step 2: Lock Down the Training Contract
This is where most pipelines break. Not because the code is wrong — because the constraints were never written down.
Context checklist:
- Pair type decided — (anchor, positive) for MNRL, (anchor, positive, negative) for triplet losses. MNRL uses in-batch negatives automatically, which means your batch size directly controls your negative count (SBERT Docs).
- Symmetry declared — symmetric pairs (paraphrase, duplicate detection) or asymmetric pairs (query-to-document retrieval). This determines your base model:
all-MiniLM-L6-v2for symmetric tasks,multi-qa-mpnet-base-dot-v1for asymmetric (SBERT Docs). - Dimension budget set — full 768 dimensions for maximum quality, or Matryoshka-wrapped training for truncatable embeddings at [768, 512, 256, 128, 64]. On STSBenchmark, Matryoshka retains 98.37% performance at 8.3% of the embedding size (SBERT Docs) — though results on other benchmarks may vary.
- Trainer API confirmed —
SentenceTransformerTrainerwithSentenceTransformerTrainingArguments, not the legacy.fit()method.
The Spec Test: If your context file doesn’t specify pair type and symmetry, the AI will default to symmetric training — and your asymmetric retrieval will silently fail. Specify both before generating any training code.
Compatibility notes:
- SentenceTransformer.fit(): Soft-deprecated since v3. Use
SentenceTransformerTrainerwithSentenceTransformerTrainingArgumentsinstead (SBERT Docs).- encode_multi_process(): Deprecated. Use
encode()withdevice,pool, andchunk_sizearguments for multi-GPU inference.
Step 3: Wire Training to Deployment
Order matters. Each component depends on the previous one’s output.
Build order:
- Fine-tune the base model first — Matryoshka wrapping and index construction both depend on the final embedding space. Train with
MultipleNegativesRankingLosson your domain pairs. Get the embedding space right before you compress it. - Add Matryoshka wrapping second —
MatryoshkaLosswraps your base loss and trains the model to produce useful embeddings at multiple truncation points. Compress after the space is learned, not before. Typical dimensions: [768, 512, 256, 128, 64] (SBERT Docs). - Build the FAISS index third — encode your corpus with the trained model, choose your index type (flat for small corpora, IVF for millions of documents), and write the index to disk. FAISS v1.14.0 added k-means++ initialization and early stopping for IVF training (FAISS GitHub). The Sentence Transformers library provides
semantic_search_faiss()insentence_transformers.utilfor direct integration — though its documentation is still sparse, so verify the API signature against current source. - Add clustering last — clustering operates on the same embedding space but doesn’t need the index. Use k-Means for known categories, agglomerative for hierarchical structure, or fast community detection for near-duplicate grouping.
For each component, your context must specify:
- What it receives (data format, tensor shape, index path)
- What it returns (trained model path, encoded vectors, cluster assignments)
- What it must NOT do (no retraining during indexing, no mixed-symmetry batches)
- How to handle failure (low-quality clusters — check embedding space first, not clustering params)
Step 4: Prove the Pipeline Works
Training loss tells you the model learned something. It doesn’t tell you the right thing was learned. You need Semantic Search evaluation, not just loss curves.
Validation checklist:
- Retrieval precision at k — run your actual queries against the FAISS index, check if top results are relevant. Failure looks like: low precision despite low training loss. Diagnosis: symmetry mismatch or wrong base model.
- Embedding space visualization — UMAP or t-SNE on a sample of your corpus. Clusters should form around semantic categories, not surface patterns. Failure looks like: a uniform blob with no separation. Diagnosis: loss function not discriminative enough for your domain.
- Matryoshka truncation audit — compare retrieval quality at 768, 256, and 128 dimensions on your test queries. If the smaller dimensions drop sharply on your data, your domain has fine-grained distinctions that need more dimensions. Benchmark numbers don’t guarantee your domain behaves the same way.
- Cluster coherence — sample items from each cluster, check if a human would group them the same way. Failure looks like: semantically unrelated items grouped together. Diagnosis: embedding space wasn’t fine-tuned for your domain’s similarity definition.
The Validation Rule: If retrieval precision drops noticeably between your eval set and production queries, your eval set doesn’t represent your users. Fix the eval set before retraining the model.
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
Used .fit() to train | Legacy API; missing learning rate scheduling and proper evaluation hooks | Switch to SentenceTransformerTrainer with SentenceTransformerTrainingArguments |
| Trained symmetric, searched asymmetric | Model learned paraphrase similarity, not query-document relevance | Declare pair symmetry before selecting base model and loss |
| Skipped Matryoshka, shipped full-size vectors | Index memory and query latency scale with dimension count | Wrap your loss with MatryoshkaLoss and ship smaller vectors for most use cases |
| Evaluated only training loss | Loss measures optimization progress, not retrieval quality | Add retrieval precision@k on real queries as your primary metric |
Used encode_multi_process() | Deprecated; may break without warning in future releases | Use encode() with device, pool, and chunk_size arguments |
Pro Tip
Your embedding pipeline is a specification, not a script. When retrieval quality drops in production, the instinct is to retrain with more data. Most of the time, the fix is upstream — a symmetry mismatch, a dimension budget that doesn’t fit the domain, or an eval set that doesn’t represent real queries. Diagnose the spec layer before you touch the training data.
Frequently Asked Questions
Q: How to fine-tune a Sentence Transformers model on custom domain data with MultipleNegativesRankingLoss?
A: Format your data as (anchor, positive) pairs — MNRL generates negatives from other batch items automatically. Use SentenceTransformerTrainer, not .fit(). Watch for click-log data: navigational queries add noise that in-batch sampling amplifies. Filter those pairs before training.
Q: How to train a Matryoshka embedding model with Sentence Transformers in 2026?
A: Wrap your base loss with MatryoshkaLoss and set target dims like [768, 512, 256, 128, 64]. Training happens at all truncation points simultaneously. The 98.37% retention figure was measured on STSBenchmark only — always validate truncation quality on your own domain before choosing a production dimension.
Q: How to use Sentence Transformers with FAISS for production semantic search in 2026?
A: Encode your corpus, build a flat or IVF index, and query using
Similarity Search Algorithms matching your distance metric. FAISS v1.14.0’s k-means++ init stabilizes centroid training. Use semantic_search_faiss() for integration, but verify its API signature against current source — documentation coverage is still limited.
Q: How to use Sentence Transformers for large-scale text clustering and near-duplicate detection?
A: Encode all texts, then apply fast community detection for near-duplicates or agglomerative clustering for topic hierarchies. Set your similarity threshold empirically — encode known duplicate and non-duplicate pairs, measure cosine similarities, and pick the value that separates them. Generic defaults fail on domain-specific text.
Your Spec Artifact
By the end of this guide, you should have:
- Pipeline map — four layers (data, loss, model, index) with input/output contracts for each
- Constraint checklist — pair type, symmetry, dimension budget, trainer API, index type, clustering method
- Validation criteria — retrieval precision@k, embedding visualization, Matryoshka truncation audit, cluster coherence sampling
Your Implementation Prompt
Copy this into Claude Code or Cursor. Replace every bracketed placeholder with your actual values from the constraint checklist above.
Build a Sentence Transformers v5.3 fine-tuning and deployment pipeline with these specifications:
DATA LAYER:
- Training pairs: [symmetric / asymmetric] (anchor, positive) format
- Dataset: [path to your training data, e.g., "data/pairs.csv"]
- Pair source: [paraphrase corpus / click logs / manual annotations]
LOSS LAYER:
- Loss function: MultipleNegativesRankingLoss
- Matryoshka wrapper: [yes / no] with dimensions [768, 512, 256, 128, 64]
- Base model: [all-MiniLM-L6-v2 for symmetric / multi-qa-mpnet-base-dot-v1 for asymmetric]
TRAINING:
- Use SentenceTransformerTrainer (NOT .fit())
- Batch size: [your batch size — larger means more in-batch negatives]
- Evaluation: [STS benchmark / custom retrieval eval] every [N] steps
INDEX LAYER:
- Index type: [Flat for small corpus / IVFFlat or IVFPQ for large corpus]
- Target dimensions: [128 / 256 / 768 — match your Matryoshka truncation point]
- Corpus path: [path to documents to index]
CLUSTERING (if needed):
- Method: [k-Means / agglomerative / fast community detection]
- Similarity threshold: [empirically determined from your duplicate/non-duplicate sample]
VALIDATION:
- Compute retrieval precision@k on [path to test queries with relevance labels]
- Compare Matryoshka truncation quality at 768, 256, and 128 dims on domain queries
- Visualize embedding space with UMAP on a representative sample
- Do NOT use encode_multi_process() — use encode() with device and pool args
Ship It
You now have a four-layer specification framework for sentence transformer pipelines. Every fine-tuning decision — data symmetry, loss function, dimension budget, index type — maps to a specific retrieval failure mode. Specify the constraints before you train, validate retrieval quality instead of training loss, and the gap between eval scores and production performance closes.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors