How to Detect and Reduce LLM Hallucinations with DeepEval, RAGAS, and RAG Grounding in 2026

Table of Contents
TL;DR
- Hallucination detection needs separate metrics for generation fidelity and retrieval grounding — one metric misses half the failures
- DeepEval, RAGAS, and Galileo measure different surfaces; layer at least two for real coverage
- Without threshold tuning and regression testing, your detection pipeline is a dashboard, not a guardrail
Your Retrieval Augmented Generation system retrieves the right documents. The model reads them. Then it invents a fact that appears nowhere in the context. You built retrieval to stop this. It didn’t. That gap between “the model had the right context” and “the model used the right context” is where most production Hallucination failures live. This guide shows you how to detect that gap, measure it, and close it.
Before You Start
You’ll need:
- A RAG system producing outputs you can evaluate (any framework — LangChain, LlamaIndex, custom)
- Familiarity with Factual Consistency as a measurement concept
- Python >=3.9 for DeepEval and RAGAS
- A working definition of what counts as a hallucination in your domain
This guide teaches you: How to decompose the hallucination problem into measurable surfaces, choose detection tools for each surface, and wire them into a pipeline with domain-specific thresholds.
The RAG System That Still Lied
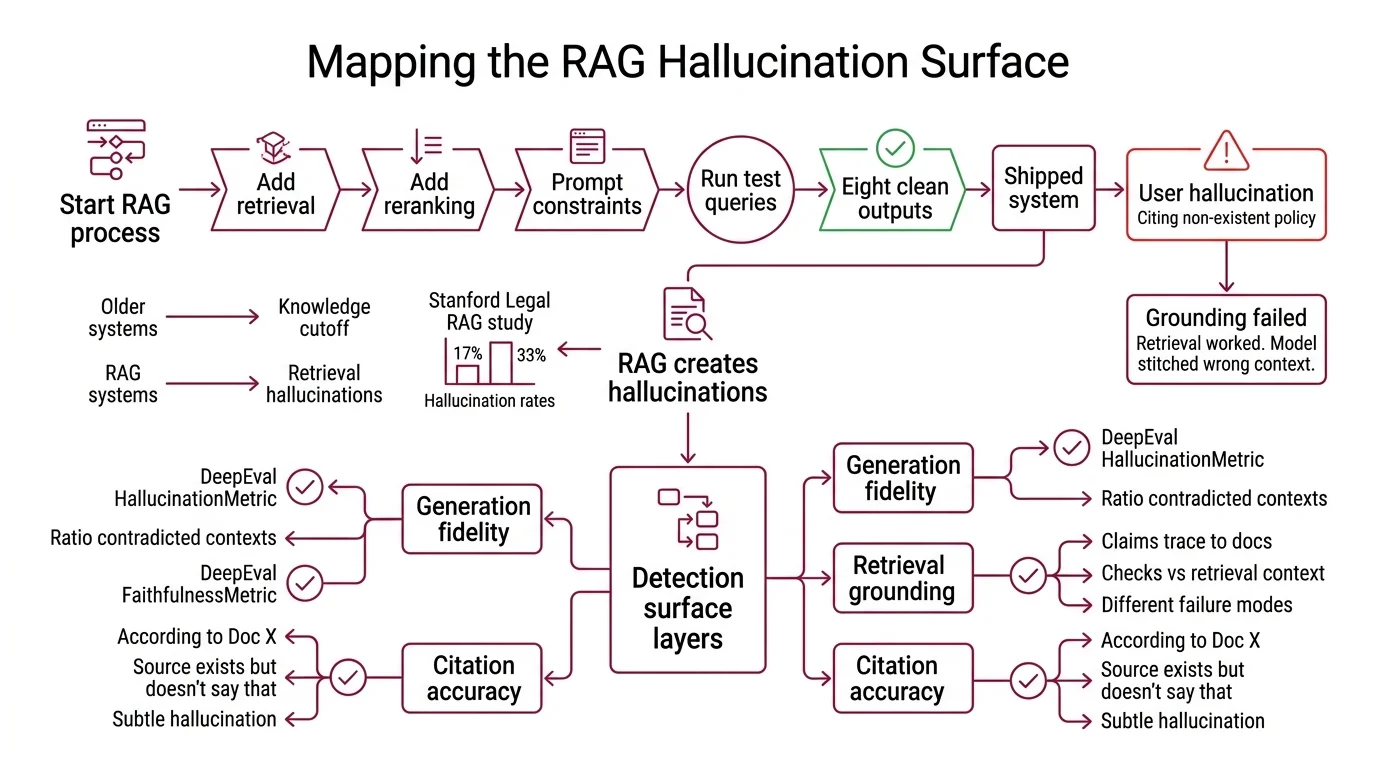
Here’s what happens. You add retrieval. You add reranking. You add prompt constraints telling the model to stay grounded. You run ten test queries. Eight look clean. You ship.
Monday morning: a user screenshots an output citing a policy that doesn’t exist. The model stitched it together from a context chunk about a different policy. Retrieval worked. Grounding failed.
RAG was supposed to fix the Knowledge Cutoff problem — give the model current documents instead of stale training data. A 2024 Stanford study on legal-domain RAG found hallucination rates between 17% and 33% even with retrieval in place (Stanford Legal RAG). That study predates current tooling, but the core finding holds: RAG changes where hallucinations originate, not whether they happen.
Step 1: Map the Hallucination Surface
Before you pick a tool, know what you’re measuring. Hallucinations aren’t one failure mode. They’re at least three, and each needs a different detector.
Your detection surface has these layers:
- Generation fidelity — did the model’s output contradict the context it received? Classic “made something up” failure. DeepEval’s HallucinationMetric catches this: it scores the ratio of contradicted contexts to total contexts (DeepEval Docs).
- Retrieval grounding — do the output’s claims trace back to retrieved documents? Different from fidelity. An output can be internally consistent yet grounded in nothing. DeepEval’s FaithfulnessMetric checks this separately: truthful claims divided by total claims, scored against retrieval context (DeepEval Docs). The distinction matters — the Hallucination metric uses provided context, the Faithfulness metric uses retrieval context. Different inputs, different failure modes caught.
- Citation accuracy — when the model says “according to Document X,” does Document X actually support the claim? This catches the subtle failure where sources exist but don’t say what the model claims they say.
The Detection Rule: If you measure only one surface, you catch one class of hallucination and miss two.
Step 2: Choose Your Detection Stack
Three tools. Different measurement philosophies. Pick based on what you need to catch and where you need to catch it.
DeepEval (v3.9.3) — open-source, 30+ metrics covering RAG, agentic, and multimodal evaluation. Runs locally. The key strength: HallucinationMetric and FaithfulnessMetric are separate checks with separate inputs. Default eval model is gpt-4.1. Python >=3.9 required.
RAGAS (v0.4.3) — open-source, built specifically for RAG evaluation. Core metrics: faithfulness, answer relevancy, context precision, context recall (RAGAS Docs). Faithfulness decomposes the answer into individual claims and checks each against context — score runs 0 to 1. Answer relevancy uses reverse-generated questions and cosine similarity to measure topic drift.
Galileo (Luna-2) — commercial platform using proprietary small language models. Latency averages 152 ms, making it viable for runtime guardrails. Cost runs around $0.02 per million tokens, roughly 97% cheaper than GPT-4-based eval (VentureBeat). Detection accuracy at 88%. Free tier covers 5,000 traces per month; Pro at $100 per month handles 50,000.
MiniCheck-FT5 — a 770M-parameter fact-checker achieving GPT-4-level accuracy on grounding tasks at 400 times lower cost (arXiv). Open-source. Useful when you need a lightweight grounding check without calling a large model.
| Dimension | DeepEval | RAGAS | Galileo |
|---|---|---|---|
| Deployment | Local / CI | Local / CI | Cloud platform |
| Hallucination check | Context contradiction ratio | Claim-level faithfulness | Proprietary SLM score |
| Latency | Depends on eval model | Depends on eval model | ~152 ms (Luna-2) |
| Best for | Granular metric decomposition | RAG-specific evaluation | Runtime guardrails |
Step 3: Wire the Detection Pipeline
Order matters. Run cheap checks first. Fail fast.
Build order:
- Faithfulness check first — your coarsest filter. If claims aren’t grounded in retrieval context, flag before running anything else. Use RAGAS faithfulness or DeepEval FaithfulnessMetric.
- Hallucination contradiction check second — catches outputs that actively contradict the context they were given. More expensive because it compares against each context chunk. DeepEval HallucinationMetric.
- Citation verification third — for systems that produce source references, verify each citation actually supports the claim it’s attached to. Most specific check. Catches the failure where a model says “per Document X” but Document X says something different.
For each metric, your specification must include:
- What input it receives (output text, retrieved contexts, source documents)
- What score range means “pass” — this varies by domain. A faithfulness threshold that works for customer support will miss critical errors in legal contexts.
- What happens on failure (block response, flag for review, retry with expanded retrieval)
- How to handle edge cases (empty retrieval, single-chunk context, multi-turn conversations)
Step 4: Tune Thresholds and Prove It Works
Default thresholds from any tool will be wrong for your domain. Expected.
Threshold tuning process:
- Collect baseline — run your pipeline on a representative sample of production queries. Record scores. Manually label a subset for ground truth.
- Find your failure boundary — plot the distribution. The threshold sits where false negatives (missed hallucinations) and false positives (flagged correct outputs) balance for your risk tolerance.
- Set per-metric thresholds — faithfulness and hallucination need different cutoffs. Legal or medical output demands strict faithfulness. Customer support can tolerate more flex.
Validation checklist:
- Faithfulness on known-good outputs — failure looks like: correct outputs flagged, threshold too strict
- Hallucination score on known-bad outputs — failure looks like: fabrications passing through, threshold too loose
- Citation accuracy on sourced outputs — failure looks like: wrong document linked to the claim
- Regression on every model update — new model versions shift hallucination patterns without warning. Last month’s thresholds might not catch this month’s failures
Security & compatibility notes:
- RAGAS v0.3 to v0.4 breaking changes:
ground_truthsrenamed toreference; wrapper classes (LangchainLLMWrapper,LlamaIndexLLMWrapper) deprecated in favor ofllm_factory; metrics now returnMetricResultobjects instead of floats. Pin to v0.4.3 and follow the migration guide.
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
| Used one metric for everything | Generation contradictions and grounding failures are different mechanisms | Run HallucinationMetric AND FaithfulnessMetric separately |
| Same threshold across domains | A passing score in customer chat is a failing score in legal | Tune thresholds per use case with labeled data |
| Tested only happy-path queries | Edge cases produce the worst hallucinations | Include adversarial and low-retrieval examples |
| Skipped regression after model swap | New models shift hallucination patterns silently | Re-run full eval suite on every model or prompt change |
| Confused DeepEval Hallucination and Faithfulness | They check different inputs — context vs. retrieval_context | Read the metric docs before selecting |
Pro Tip
Your Chain-of-Thought prompts can double as detection inputs. If you already ask the model to show its reasoning, parse those reasoning steps as claims and run faithfulness checks against them. The claims come for free — the reasoning trace is already there, no extra generation call needed. Pairs well with Calibration signals: when a model expresses uncertainty about a specific claim, that claim is more likely to be unfaithful to the source material. Use the uncertainty as a second signal alongside your metric scores.
Frequently Asked Questions
Q: How to use retrieval-augmented generation to reduce LLM hallucination? A: RAG anchors model output in retrieved documents, but doesn’t eliminate fabrication. The critical addition is a faithfulness metric after generation — confirming the model actually used what retrieval gave it. Without that check, you’re trusting retrieval blindly.
Q: Best hallucination detection tools DeepEval vs Galileo vs RAGAS compared 2026? A: DeepEval offers the most granular metric separation. RAGAS excels at claim-level RAG evaluation. Galileo wins on latency for runtime guardrails. Most production setups run an open-source tool in CI and a fast model like MiniCheck or Galileo at inference time.
Q: How to build a hallucination detection pipeline step by step? A: Start with faithfulness as your coarsest filter. Layer hallucination contradiction checks on passing outputs. Add citation verification for sourced responses. Tune thresholds per domain using labeled data, not defaults. Automate the sequence in CI.
Q: How to implement citation verification and grounding checks in LLM outputs? A: Citation verification needs the claim, the cited passage, and an entailment check between them. DeepEval FaithfulnessMetric handles this when you set retrieval_context to the cited passages. The key mistake: verifying a citation exists without verifying it supports the specific claim.
Your Spec Artifact
By the end of this guide, you should have:
- A hallucination surface map — three layers (generation fidelity, retrieval grounding, citation accuracy) with specific metrics assigned to each
- A detection stack specification — which tools handle which layers, with per-domain threshold values tuned on your labeled data
- A regression test protocol — labeled examples, evaluation triggers, and failure handling rules that run on every model or prompt change
Your Implementation Prompt
Use this prompt in your AI coding tool to scaffold the detection pipeline. Replace every bracketed placeholder with your values from Steps 1-4.
Build a hallucination detection pipeline with the following specification:
DETECTION LAYERS:
1. Faithfulness check using [RAGAS faithfulness / DeepEval FaithfulnessMetric]
- Input: model output + retrieval context from [your retriever name]
- Pass threshold: [your faithfulness threshold tuned on labeled data]
- On failure: [block response / flag for review / retry with expanded retrieval]
2. Hallucination contradiction check using [DeepEval HallucinationMetric]
- Input: model output + provided context chunks from [your context source]
- Pass threshold: [your max contradiction ratio tuned on labeled data]
- On failure: [block response / flag for review]
3. Citation verification using [DeepEval FaithfulnessMetric / MiniCheck-FT5]
- Input: each claim-citation pair extracted from [your output parser]
- Pass threshold: [your citation accuracy threshold]
- On failure: [strip citation / flag for review]
PIPELINE BEHAVIOR:
- Run checks in order: faithfulness, then hallucination, then citation
- Fail fast: if faithfulness fails, skip remaining checks
- Log all scores to [your observability platform]
- Domain: [your domain — customer support / legal / medical / general]
- Python version: [>=3.9]
- Dependencies: deepeval>=[pinned version], ragas>=[pinned version]
REGRESSION PROTOCOL:
- Test suite location: [path to your labeled evaluation examples]
- Trigger on: [model update / prompt change / weekly schedule]
- Pass criteria: [minimum percentage of test cases passing all three checks]
Ship It
You now have a framework for decomposing hallucination into measurable surfaces, selecting the right detector for each surface, and wiring them into a pipeline with domain-tuned thresholds. The model will still hallucinate. The difference is you’ll catch it before your users do.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors