How to Detect and Prevent Benchmark Contamination with CoDeC, CCV, and LiveBench in 2026

Table of Contents
TL;DR
- Benchmark scores only mean something if the model hasn’t already seen the answers — detection tools like CoDeC and CCV tell you whether it has
- Contamination-resistant benchmarks (LiveBench, AntiLeakBench) make the problem harder to hide by rotating questions or timestamping knowledge
- No single detection method catches everything — layer detection with prevention for evaluations you can trust
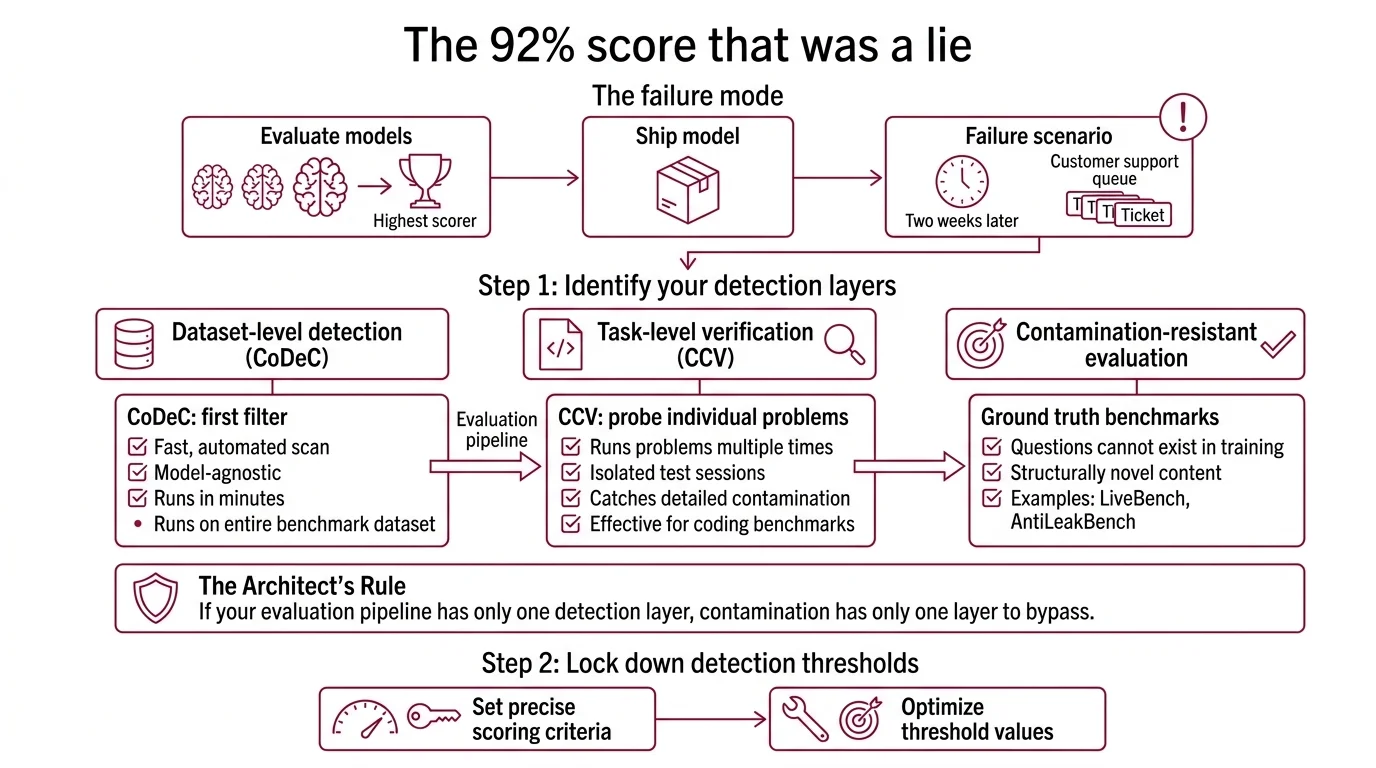
You picked a model based on leaderboard numbers. Three weeks into production, it fails on inputs the benchmark said it could handle. The scores were real. The evaluation wasn’t — the model had memorized the test set. That gap between benchmark promise and production reality is Benchmark Contamination, and closing it starts with your detection pipeline.
Before You Start
You’ll need:
- A model you want to evaluate (API access is enough — no training data required)
- Familiarity with how Model Evaluation pipelines work
- Access to Python and pip for tool installation
This guide teaches you: How to build a contamination detection and prevention workflow — decompose what you’re checking, specify which tools catch which signals, layer detection with resistant benchmarks, and validate that your evaluation actually measures capability.
The Leaderboard Score That Meant Nothing
A model tops MMLU Benchmark. Your team greenlights deployment. Two sprints later, it hallucinates on domain queries that should be straightforward given its score.
The model didn’t learn the skill. It memorized the answers. And the benchmark told you nothing about generalization.
This isn’t hypothetical. Researchers demonstrated that RL post-training can conceal contamination signals entirely — detection tools that work on base models return clean results on the fine-tuned version (Fragility paper). Your evaluation pipeline needs more than one check.
Step 1: Identify the Three Contamination Signals
Contamination leaves traces. Three distinct signals map to three detection strategies.
Signal 1: Confidence disruption. A model that memorized a benchmark answer becomes less confident when you add in-context examples. The context disrupts its recall pattern. This is what CoDeC measures.
Signal 2: Solution uniformity. Ask a clean model to solve the same coding problem five times in isolation. You get variation — different variable names, different approaches. A contaminated model reproduces near-identical solutions because it’s recalling, not reasoning. This is what CCV measures.
Signal 3: Temporal impossibility. If a model answers questions about events that postdate its training cutoff, it didn’t learn from the world. It learned from the benchmark. This is what AntiLeakBench exploits.
Your detection surface has these parts:
- Confidence-based detection (CoDeC) — catches dataset-level memorization across any model architecture
- Behavioral analysis (CCV) — catches instance-level memorization in coding benchmarks
- Temporal filtering (AntiLeakBench) — prevents contamination by construction
Step 2: Specify Your Detection Toolkit
Each tool has a specific scope, specific inputs, and specific limitations. Get these wrong, and you’ll trust results you shouldn’t.
CoDeC (Contamination Detection via Context)
CoDeC is model-agnostic and dataset-agnostic. It works across architectures without needing access to training data (CoDeC paper). The method measures how in-context examples affect a model’s confidence on benchmark items. Contaminated data shows decreased confidence when context is added — the context disrupts memorized recall.
Detection thresholds: scores above 80% indicate strong contamination, 60-80% is ambiguous, below 60% is likely clean (CoDeC paper). At the dataset level, CoDeC achieves 99.9% AUC separating seen from unseen datasets, tested across 13 model families and 40 recent models (CoDeC paper). Accepted at ICLR 2026.
Context checklist for CoDeC:
- Model API access (inference only — no weights needed)
- Benchmark dataset in structured format
- In-context example sets for confidence comparison
- Score interpretation mapped to your risk tolerance
Caveat: as of early 2026, no public code repository has been confirmed despite ICLR 2026 acceptance. The method is described as reproducible from the paper.
CCV (Cross-Context Verification)
CCV solves the same benchmark problem five times in isolated sessions at temperature 0, then measures solution diversity using AST similarity, BLEU, and edit distance (CCV paper). Its Hierarchical Cross-Context Architecture uses four layers — Designer, Executor, three independent Analysts, and Integrator — with information restriction to prevent confirmation bias.
CCV achieved perfect separation on SWE-bench Verified, finding that a third of prior contamination labels were false positives (CCV paper). But this was validated on 9 problems using a single model. Promising signal, not a definitive verdict.
Context checklist for CCV:
- Model API with session isolation capability
- Temperature control (must support deterministic output)
- Benchmark problems with verifiable solutions
- Diversity metrics calibrated to your domain
Caveat: CCV is a March 2026 preprint. Code was anonymized for peer review — public release timing is unclear.
LiveBench (Contamination-Resistant Benchmark)
LiveBench sidesteps detection entirely. Questions are sourced monthly from recent math competitions, arXiv papers, and news — material that postdates model training (LiveBench paper). Six categories cover math, coding, reasoning, data analysis, instruction following, and language across 18+ tasks (LiveBench GitHub). Scoring uses objective, verifiable ground-truth answers. No LLM judge needed.
Free and open-source with roughly 1,100 GitHub stars, pip installable. The latest question release was January 2026. ICLR 2025 Spotlight.
Context checklist for LiveBench:
- pip install and API key for your model
- Version pinning with
--livebench-release-optionfor reproducibility - Use vLLM with OpenAI-compatible API for local inference — the native local model path is unmaintained
Step 3: Layer Detection on Top of Prevention
One tool gives you a data point. A layered pipeline gives you confidence.
Build order:
- Start with LiveBench — evaluate against contamination-resistant questions first. This gives you a baseline capability score that isn’t inflated by memorization.
- Run CoDeC against your primary benchmark — if you’re using a static benchmark for domain-specific reasons, CoDeC checks whether the model has seen those specific items. Clean CoDeC scores plus strong LiveBench performance = genuine capability.
- Apply CCV for coding benchmarks — if your evaluation includes SWE-bench or similar code generation tasks, CCV’s behavioral analysis catches instance-level contamination that confidence-based methods miss.
- Cross-reference with AntiLeakBench — for knowledge-intensive tasks, AntiLeakBench constructs questions using Wikidata with explicit timestamps, ensuring the knowledge postdates training. Question and context accuracy exceeds 96% (AntiLeakBench paper). Published at ACL 2025.
For each layer, specify:
- What it receives (model outputs on benchmark items)
- What it returns (contamination score, confidence interval, or resistant benchmark score)
- What it cannot catch (RL-concealed contamination, partial memorization below thresholds)
- How failure looks (clean CoDeC score on a model that still underperforms in production = the contamination vector isn’t in your benchmark set)
Tooling & compatibility notes:
- LiveBench local inference: Native local model path is unmaintained. Use vLLM with an OpenAI-compatible API endpoint instead.
- LiveBench task changes: House traversal task removed for answer ambiguity; CTA task retired in the April 2025 release. Verify your task set against the current changelog.
- AntiLeakBench: Low-activity repository (5 stars, 4 commits as of April 2026). Original Wikidata dump no longer accessible — reproduced samples may differ from paper releases.
- LLMSanitize: Bundles 12 detection methods in a pip-installable library, but last release (v0.0.8) was August 2024 — evaluate maintenance status before production use.
- Detection fragility: Wang et al. (2025) demonstrate that RL post-training (GRPO) can conceal SFT contamination signals, and chain-of-thought contamination in reasoning models leaves minimal detectable evidence. Do not rely on any single detection method as a standalone gate.
Step 4: Prove Your Evaluation Pipeline Works
Detection and prevention mean nothing if you can’t verify the pipeline itself.
Validation checklist:
- Positive control test — run CoDeC on a model you know was trained on a specific benchmark. If the score is below 80%, your setup has a configuration problem. Failure looks like: clean scores on known-contaminated models.
- Negative control test — run CoDeC on held-out data the model hasn’t seen. Scores should fall below 60%. Failure looks like: high scores on genuinely clean data, meaning your in-context example sets are biasing the measurement.
- Cross-method agreement — where detection ranges overlap (coding benchmarks), run both CoDeC and CCV. Disagreement doesn’t mean one is wrong — it means the contamination vector may be partial or domain-specific. Investigate, don’t average.
- LiveBench version pinning — confirm the question set version matches your evaluation window. Failure looks like: comparing model A (evaluated January) to model B (evaluated March) on different question sets.
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
| Trusted the leaderboard score at face value | Static benchmarks don’t tell you if the model memorized vs. learned | Run CoDeC or add LiveBench to your eval |
| Used one detection method as a gate | RL post-training can conceal contamination from any single detector | Layer at least two methods — one detection, one prevention |
| Compared models across LiveBench releases | Question sets rotate monthly — different releases measure different things | Pin --livebench-release-option for all models in a comparison |
| Skipped positive control validation | No way to know if your detection setup is working | Test against a known-contaminated case before trusting clean results |
Pro Tip
Think of your detection pipeline like a Confusion Matrix for trust. Detection methods have their own false positive and false negative rates. CoDeC’s 99.9% AUC is excellent at the dataset level, but instance-level calls in the 60-80% range are ambiguous by design. Your Precision, Recall, and F1 Score intuition applies: tune your thresholds based on whether a false positive (flagging a clean model) or a false negative (passing a contaminated one) costs you more.
Frequently Asked Questions
Q: How to detect benchmark contamination using CoDeC and Cross-Context Verification step by step in 2026? A: Start with CoDeC for dataset-level screening — it flags contamination at three severity thresholds without needing training data. For coding benchmarks, add CCV to catch instance-level memorization through solution diversity across five isolated sessions. Run both against positive controls first. CCV requires session isolation, so models without stateless API access need a wrapper.
Q: How to audit an LLM’s benchmark results for training data contamination before deployment? A: Run CoDeC on every static benchmark in your evaluation suite, compare those scores against LiveBench on equivalent task categories, and flag models where static scores significantly exceed resistant benchmark scores. That gap is your contamination signal. Apply Ablation Study logic — if removing one benchmark category tanks perceived capability, that category deserves deeper inspection.
Q: Which contamination-resistant benchmarks like LiveBench and AntiLeakBench should you use for LLM evaluation in 2026? A: LiveBench is the stronger choice — ICLR 2025 Spotlight, monthly question rotation, objective scoring, active maintenance. AntiLeakBench uses Wikidata-timestamped questions but has minimal community activity as of 2026. Use LiveBench as your primary resistant benchmark; add AntiLeakBench for knowledge-intensive tasks where temporal filtering adds a distinct signal.
Your Spec Artifact
By the end of this guide, you should have:
- A detection map — which tools target which contamination signals (confidence disruption, solution uniformity, temporal impossibility) for your specific benchmarks
- A threshold spec — CoDeC score boundaries mapped to your risk tolerance, with positive and negative control baselines established
- A validation protocol — cross-method checks, version pinning, and control tests that prove your pipeline works before you trust its output
Your Implementation Prompt
Copy this into your AI coding tool to scaffold the contamination detection pipeline. Replace each bracketed placeholder with values from your detection map and threshold spec.
Build a benchmark contamination detection pipeline with these specifications:
DETECTION SURFACE:
- Primary benchmark under audit: [benchmark name, e.g., MMLU, SWE-bench, GPQA]
- Model under evaluation: [model name and API endpoint]
- Risk tolerance: [high/medium/low — determines threshold interpretation]
LAYER 1 — BASELINE (LiveBench):
- Install LiveBench via pip
- Pin question set version: [--livebench-release-option value from your eval window]
- Run evaluation on categories: [math, coding, reasoning — select relevant subset]
- Record baseline scores per category
LAYER 2 — CONFIDENCE DETECTION (CoDeC):
- Run against [primary benchmark] with in-context example sets
- Thresholds: above 80% = contaminated, 60-80% = investigate, below 60% = likely clean
- Positive control: [known-contaminated model/benchmark pair for validation]
- Negative control: [held-out dataset the model has not seen]
LAYER 3 — BEHAVIORAL DETECTION (CCV, coding benchmarks only):
- Run 5 isolated sessions at temperature 0 per problem
- Measure diversity: AST similarity (0.4), BLEU (0.3), edit distance (0.3)
- Flag problems where contamination score >= 0.8
CROSS-REFERENCE:
- Compare static benchmark scores vs. LiveBench scores per category
- Flag categories where static exceeds LiveBench by [your gap threshold, e.g., >15 points]
VALIDATION:
- Positive control returns score above 80%
- Negative control returns score below 60%
- Cross-method disagreement triggers manual review, not auto-pass
OUTPUT: Per-benchmark contamination risk (HIGH/MEDIUM/LOW), control test results, flagged categories.
Ship It
You now have a framework for evaluating the evaluation. Benchmark scores are inputs to your decision, not the decision itself. Every model gets a contamination check before the leaderboard number means anything.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors