How to Deduplicate a Training Corpus with text-dedup, datasketch, and NeMo Curator in 2026
TL;DR
- Deduplication is three jobs, not one — exact, near-duplicate, and semantic. Specify which tiers your corpus actually needs before you pick a tool.
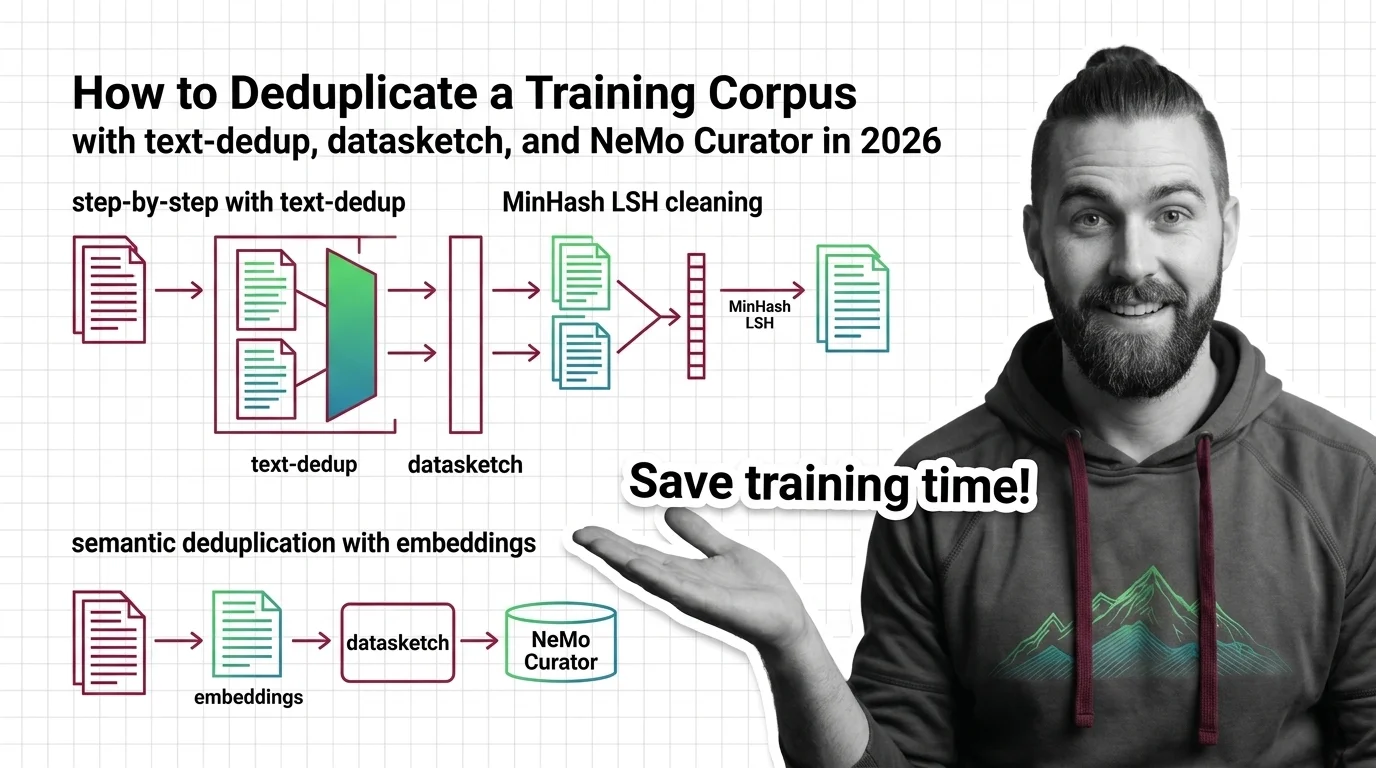
- The tool follows the scale: datasketch for prototyping, Text Dedup scripts for HuggingFace datasets, NeMo Curator for GPU-scale corpora.
- Your spec must pin the similarity threshold, the MinHash banding, and the normalization rules — or every run produces a different “clean” dataset.
Your freshly pretrained model just emitted a Stack Overflow answer word-for-word — license footer, username, and all. You didn’t train it to plagiarize. You fed it a web crawl where that same snippet appeared four thousand times, and the model did exactly what duplicated data tells it to do: memorize. The fix isn’t a bigger model or a cleverer loss function. It’s Data Deduplication done as a specification, not a one-line script you ran once and forgot.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex) to scaffold the pipeline from your spec
- A working grasp of MinHash and Jaccard Similarity — the math behind near-duplicate detection
- A clear picture of your corpus: source mix, rough token count, and whether it lands on a laptop or a GPU cluster
This guide teaches you: how to decompose deduplication into three independent tiers, specify the constraints each one needs, and match the tier to the right tool — so the AI builds a pipeline that actually improves Training Data Quality instead of one that silently drops half your good data.
The Duplicate You Can’t See Is the One That Hurts
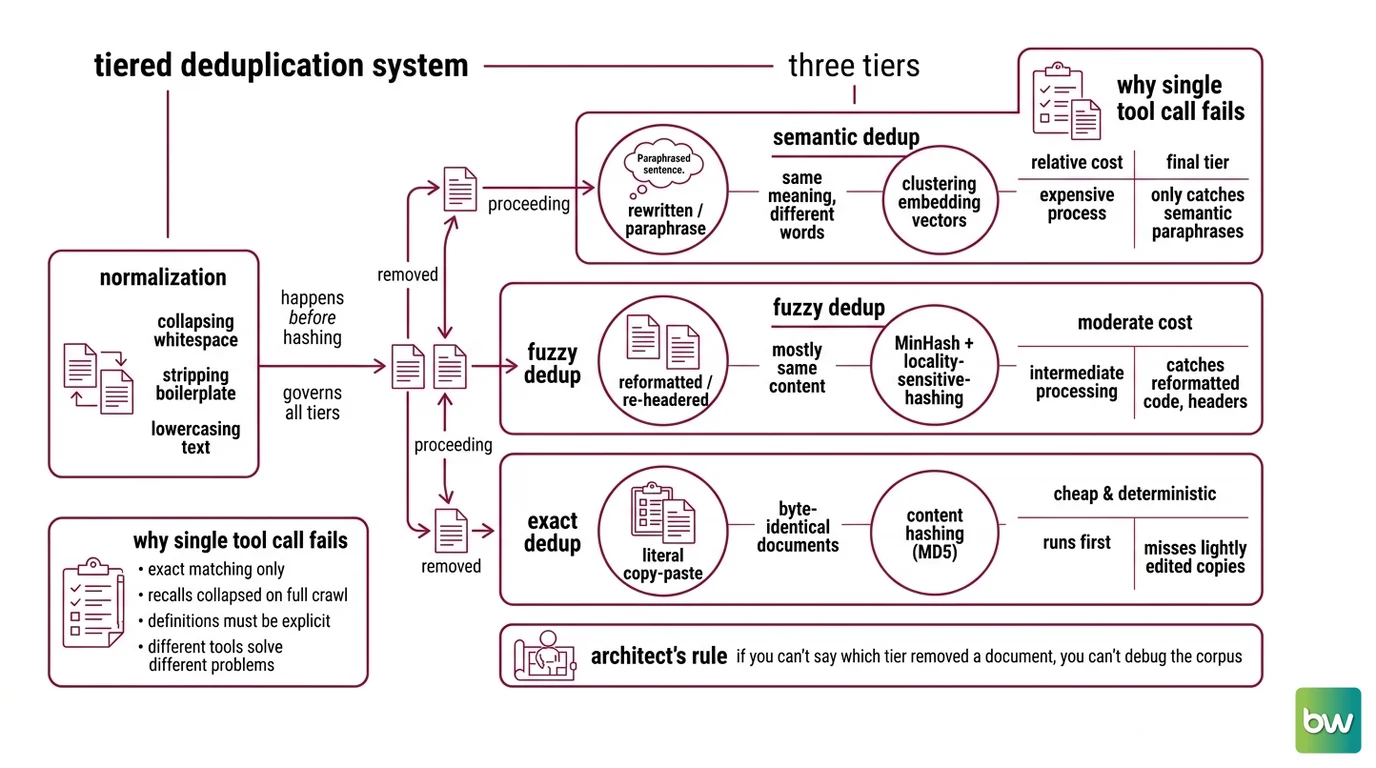
Here’s the failure I see most. Someone runs an exact-match hash over a web crawl, sees a modest drop, and calls the corpus clean. Then the model still regurgitates boilerplate, still overweights the most-copied documents, still memorizes. Exact matching only catches byte-identical copies. It misses the same article republished with a different header, the same code with reformatted whitespace, the same paragraph paraphrased across ten SEO farms.
It worked on the demo corpus. On the full crawl, recall collapsed — because “duplicate” was never defined. Byte-identical? 80% token overlap? Same meaning, different words? Those are three different problems, and a single tool call answers only one of them.
Step 1: Map the Three Tiers of Duplication
Before you touch a library, decompose the problem. Deduplication is not one operation. It is three, stacked from cheapest to most expensive, each catching what the previous tier misses.
Your system has these parts:
- Exact dedup — removes byte-identical documents via a content hash (MD5 or similar). Cheap, deterministic, runs first. Catches the literal copy-paste.
- Fuzzy / near-duplicate dedup — removes documents that are mostly the same using MinHash plus Locality Sensitive Hashing. This is where reformatted, re-headered, and lightly-edited copies die.
- Semantic dedup — removes documents that mean the same thing in different words, by clustering Embedding vectors. The paraphrase tier. Semantic Deduplication is the only one that catches a rewritten article.
There’s a fourth component that isn’t a tier but governs all three: normalization. Lowercasing, whitespace collapsing, and boilerplate stripping happen before hashing, or your exact tier misses copies that differ by a trailing newline.
The Architect’s Rule: If you can’t say which tier removed a given document, you can’t debug the corpus it produced.
The reason order matters: each tier is more expensive than the last. Exact matching is a hash lookup. MinHash LSH is a sketch-and-bucket pass. Semantic dedup means embedding every document and running similarity clustering on the whole set. Run the cheap filters first so the expensive one processes less data.
Step 2: Lock Down the Dedup Contract
This is the step everyone skips, and it’s the one that makes a run reproducible. The AI — or the next engineer — needs every one of these specified, or the pipeline guesses. And it guesses differently each time.
Context checklist:
- Normalization rules — exact casing, whitespace, and Unicode handling, applied identically across all tiers
- Similarity threshold — the Jaccard cutoff for “near-duplicate.” NeMo Curator’s fuzzy method targets roughly 80% similarity as its default working point (NeMo Curator Docs)
- MinHash configuration — number of permutations, and the LSH banding. NeMo Curator’s fuzzy defaults are num_bands=20 with minhashes_per_band=13, a balanced recall/precision starting point (NeMo Curator Docs)
- Suffix-array option — whether you also strip verbatim substrings. The Suffix Array approach from Lee et al. 2021 removes repeated substrings of 50 tokens or longer, catching duplication within documents that document-level dedup ignores (arXiv)
- Tool versions and hardware — which library, which version, CPU or GPU. This is not a footnote; it changes which tool is even viable
The Spec Test: If your context doesn’t pin the LSH banding, two runs over the same corpus produce two different “clean” datasets — and you’ll never reproduce the model that worked.
A note on thresholds: I gave you NeMo’s defaults as a starting point, not a law. The right Jaccard cutoff depends on your corpus. Code and legal text tolerate aggressive deduplication; creative or conversational data gets damaged by it because near-identical phrasing is legitimately common. Start at the documented defaults. Measure what gets removed. Adjust.
Step 3: Sequence the Build and Match the Tool to the Scale
Now wire the tiers in order, and here’s the part the docs won’t tell you straight: the tool you reach for is decided by your corpus size, not by feature lists.
Build order:
- Normalize, then exact dedup first — because it’s the cheapest pass and shrinks the input to every later stage. NeMo Curator’s exact method uses MD5 hashing for this (NeMo Curator Docs).
- Fuzzy dedup second — because MinHash LSH operates on the already-shrunk set. This is the highest-value tier for web data.
- Semantic dedup last — because embedding the corpus is the most expensive operation, so you want it running over the smallest possible set.
Match the tool to the scale:
- datasketch — the library-grade foundation. Version 1.10.0, needs Python 3.9+, NumPy 1.11+, and SciPy (datasketch Docs). It ships MinHash, MinHash LSH, LSH Forest, LSH Ensemble, Weighted MinHash, HyperLogLog, and HNSW, and its LSH index can be backed by Redis or Cassandra for sets too big for memory (datasketch’s GitHub repository). Reach for it when you’re prototyping the fuzzy tier or embedding dedup inside your own pipeline.
- text-dedup — a collection of per-algorithm CLI scripts that take a HuggingFace dataset and read config from TOML (text-dedup Docs). It covers MinHash+LSH, 64/128-bit SimHash, suffix-array substring matching, and Bloom-filter exact dedup. Its MinHash is largely based on the datasketch implementation (text-dedup Docs), so you’re getting the same core math with a dataset-shaped wrapper. Reach for it when your corpus already lives as a HuggingFace dataset and fits one machine.
- NeMo Curator — NVIDIA’s GPU-accelerated curation toolkit, version 26.02. It covers all three tiers in one pipeline: exact (MD5), fuzzy (MinHash+LSH), and semantic (embeddings plus clustering), and installs with
uv pip install "nemo-curator[text_cpu]"(NeMo Curator Docs). Reach for it when the corpus is too large for a single node and you have GPUs to throw at it.
For each tier, your context must specify:
- What it receives (normalized documents, or the survivors of the previous tier)
- What it returns (the deduplicated set plus a removal log — you want to know what got cut)
- What it must NOT do (don’t let semantic dedup touch documents the fuzzy tier already flagged)
- How to handle failure (a tier that removes more than your sanity threshold should halt, not silently proceed)
Security & compatibility notes:
- text-dedup (retiring): The author is gradually retiring the PyPI package and states it is not intended as a general-purpose library — they recommend reading or forking the scripts rather than depending on the package (text-dedup Docs). Treat it as reference code you vendor, not a pinned dependency.
- NeMo Curator 26.02 (Ray upgrade): Version 26.02 raised the minimum Ray from 2.50 to 2.54 — upgrade Ray before you install or the pipeline won’t start. The backend is now Ray, not the Dask + RAPIDS cuDF stack described in pre-26.x tutorials (NeMo Curator Docs). If you’re following an older guide, the API has moved.
Step 4: Prove the Corpus Is Actually Cleaner
Don’t trust a “done” message. Dedup that removes too little is useless; dedup that removes too much quietly destroys your dataset. Verify with evidence.
Validation checklist:
- Removal ratio per tier — failure looks like: exact dedup cutting an implausibly large share (your normalization is probably merging distinct docs) or semantic dedup cutting near zero (your similarity threshold is too tight to fire)
- Spot-check the pairs — pull 20 documents each tier flagged as duplicates and read them. Failure looks like: pairs that a human would call clearly different, meaning your Jaccard threshold is too loose
- Jaccard distribution — failure looks like: a flat distribution with no gap between “duplicate” and “unique,” which means your MinHash permutation count is too low to discriminate
- Downstream Memorization check — the real test. Models trained on deduplicated data emit memorized text roughly 10× less frequently than models trained on the raw set (arXiv). If your dedup didn’t move that needle, a tier isn’t doing its job
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
| Ran only exact-match dedup | Caught byte-identical copies, missed every reformatted and paraphrased duplicate | Stack all three tiers — exact, fuzzy, semantic |
| Skipped normalization | Exact hash treated the same doc with a trailing newline as unique | Normalize casing and whitespace before any hashing |
| Left MinHash banding unspecified | Each run produced a different “clean” corpus | Pin num_bands and minhashes_per_band in the spec |
| Used one Jaccard threshold for all data | Aggressive cutoff that fit code destroyed conversational data | Set the threshold per source type, measure, adjust |
| Followed an old NeMo tutorial | Pre-26.x guides assume the Dask backend that no longer applies | Target the Ray backend; upgrade Ray to 2.54+ first |
Pro Tip
Always emit a removal log, not just a clean corpus. Every tier should write which documents it cut and why — the matching document ID, the tier, the similarity score that triggered it. When your model later memorizes something or your eval drops, that log is the only artifact that tells you whether dedup was too aggressive, too loose, or innocent. A dedup pipeline that throws data away without a receipt is a pipeline you can’t debug. This habit transfers to every data-curation job you’ll ever build.
Frequently Asked Questions
Q: How to deduplicate a training dataset step by step with text-dedup? A: Run its per-algorithm scripts in order — exact first, then MinHash+LSH — each pointed at your HuggingFace dataset with parameters in a TOML config. One catch the docs bury: vendor the scripts into your repo, because the author is retiring the PyPI package and won’t maintain it as a library.
Q: How to use MinHash LSH to clean web-scraped corpora before pretraining? A: Build MinHash signatures per document, then bucket them with LSH so only similar documents get compared — avoiding an all-pairs blowup. The detail that breaks people: your band count sets the recall/precision trade-off, so a corpus of mixed sources often needs the threshold tuned per source, not one global value.
Q: How to apply semantic deduplication with embeddings for dataset curation? A: Embed every document, cluster the vectors, and drop near-identical neighbors within each cluster — catching paraphrases that MinHash misses. Run it last and only on survivors of cheaper tiers, since embedding a full corpus is the costliest step. NeMo Curator’s SemDedup packages this clustering approach directly.
Your Spec Artifact
By the end of this guide, you should have:
- A three-tier dedup map naming which tiers your corpus needs and in what order
- A constraint list: normalization rules, Jaccard threshold per source, MinHash permutations, and LSH banding
- A validation criteria sheet: expected removal ratio per tier, plus the downstream memorization check that proves it worked
Your Implementation Prompt
Paste this into your AI coding tool once you’ve filled the brackets with your corpus’s real values. It mirrors the three tiers from Step 1, the constraints from Step 2, the build order from Step 3, and the validation from Step 4.
Build a text deduplication pipeline for a training corpus. Decompose it into
three ordered tiers and produce a removal log for each.
CORPUS:
- Source mix: [e.g. Common Crawl + GitHub + forums]
- Approximate size: [token count or GB]
- Hardware available: [single CPU machine / single GPU / multi-GPU cluster]
- Tool: [datasketch (prototype) / text-dedup scripts (HF dataset, one node) /
NeMo Curator 26.02 (GPU scale — requires Ray 2.54+)]
NORMALIZATION (apply identically across all tiers, before hashing):
- Casing: [lowercase / preserve]
- Whitespace: [collapse runs / preserve]
- Boilerplate stripping: [headers, footers, nav — list what to remove]
TIER 1 — EXACT (run first):
- Method: content hash (MD5)
- Output: deduplicated set + log of removed document IDs
TIER 2 — FUZZY / NEAR-DUPLICATE (run on Tier 1 survivors):
- MinHash permutations: [e.g. 128]
- LSH banding: num_bands=[20], minhashes_per_band=[13]
- Jaccard threshold: [per source, e.g. code 0.8 / prose 0.7]
- Optional suffix-array substring removal: [yes/no, min length 50 tokens]
TIER 3 — SEMANTIC (run last, on Tier 2 survivors only):
- Embedding model: [your choice]
- Clustering + near-neighbor drop within clusters
- Constraint: do NOT re-evaluate documents already removed upstream
VALIDATION (must pass before output is accepted):
- Report removal ratio per tier; halt if any tier removes more than [%]
- Emit 20 sample duplicate pairs per tier for human spot-check
- Confirm Jaccard distribution shows a clear duplicate/unique gap
Ship It
You now see deduplication the way it should be specified: three independent tiers, ordered cheapest-first, each with its own contract and removal log. You can look at any corpus, decide which tiers it needs, and pick the tool by scale instead of by hype. That’s the difference between a model that memorizes its training data and one that learned from it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors