How to Cut Agent Costs with OpenRouter, Helicone, and LiteLLM (2026)

Table of Contents
TL;DR
- Treat the model as a parameter, not a hard-coded constant — every call needs a routing contract that names cheap, default, and escalation tiers.
- Prompt caching is the highest-leverage line item in your invoice. If your gateway is not reading repeated context at a fraction of input price, you are funding entropy.
- Budgets, alerts, and per-key spend limits belong in the gateway, not in a spreadsheet you check on Friday.
The invoice arrives on the first of the month. Your agent worked. Every test passed. The bill is three times what you projected because every step replayed the same 8,000-token system prompt at full input rates, and the orchestration layer routed every call to the flagship model whether it needed flagship reasoning or not. This is the default outcome when Agent Cost Optimization is treated as a runtime concern instead of a specification.
Before You Start
You’ll need:
- A working agent stack — LangGraph, OpenAI Agents SDK, CrewAI, or a hand-rolled orchestrator
- A gateway choice in mind — LiteLLM (self-hosted), Helicone (managed), Portkey (managed), or OpenRouter (managed inference)
- A clear picture of which calls in your graph are cheap-tier-eligible and which genuinely need a frontier model
- Familiarity with Agent Evaluation And Testing so you can prove a cheaper route still ships correct answers
This guide teaches you: how to decompose agent cost into four independent contracts — routing, caching, budget, and observability — so each layer can be specified, tested, and swapped without touching the agent code.
The $30K Month That Should Have Been $4K
You ship the agent. Demo day looks great. The first week of real traffic burns through the projected monthly budget by Wednesday. Nobody is doing anything wrong — every call is real work — but every system prompt is paid at full freight, every tool-decomposition step uses the top-tier model, and there is no alert until finance forwards the invoice.
It worked on Friday. On Monday, the bill broke because the cheap-tier router never shipped and the cached input got invalidated by an unstable timestamp in the prompt.
That is the failure pattern this guide fixes. Cost is a specification, not a side effect. Once the gateway owns routing, caching, and budgets, the agent code stops caring how much it spends.
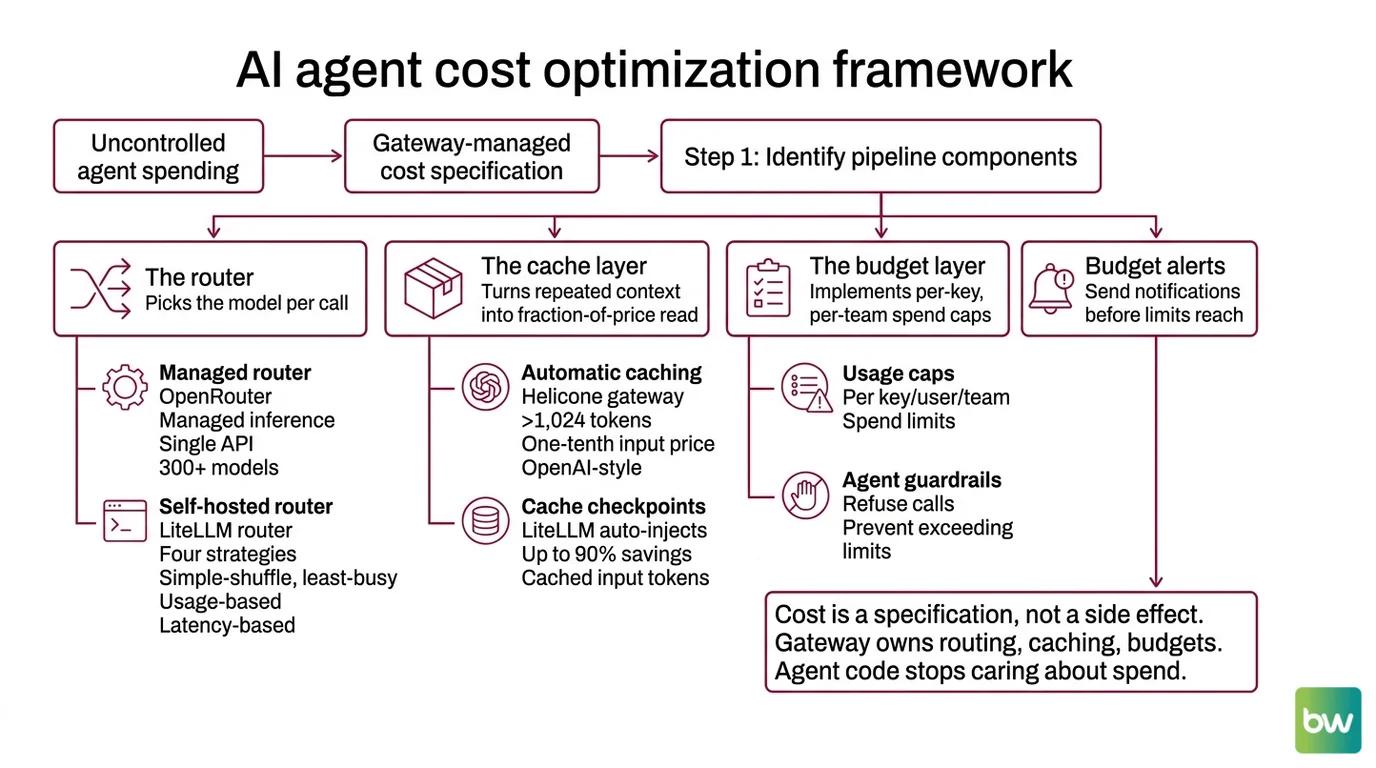
Step 1: Identify the Pipeline Components
Before you wire anything, name the layers. An agent cost stack has four independent components, and confusing them is why “we tried OpenRouter and it was fine” turns into a thirty-thousand-dollar surprise.
Your system has these parts:
- The router — picks the model per call. OpenRouter offers managed inference across 300+ models from 60+ providers behind a single OpenAI-compatible API (OpenRouter Docs). LiteLLM’s router runs in your infrastructure and supports four strategies:
simple-shuffle(default),least-busy,usage-based-routing, andlatency-based-routing(LiteLLM Docs). Pick one based on whether you optimize for cost, throughput, or tail latency. - The cache layer — turns repeated context into a fraction-of-price read. Helicone’s AI Gateway caches prompts above 1,024 tokens automatically and reads at one-tenth of the input price for OpenAI-style providers (Helicone Docs). LiteLLM auto-injects cache checkpoints to drive up to 90% savings on cached input tokens (LiteLLM Docs).
- The budget layer — per-key, per-user, and per-team spend caps with alerts before the limit lands, plus Agent Guardrails to refuse calls that would exceed policy. LiteLLM ships this in the proxy with Slack alerts for budget thresholds, slow responses, and exceptions (LiteLLM Docs). Portkey adds the same as a managed service starting at $49 per month for the platform fee on top of LLM tokens (Portkey Pricing).
- The observability layer — per-call trace with model, tokens in, tokens out, cache hit, route taken, and dollar cost. Without it, every optimization above is a guess.
The Architect’s Rule: If a developer changes models by editing a string in agent code, you do not have a router. You have a configuration leak.
Mixing these into one library — the “AI platform that does everything” — is the same antipattern as one big try/except. Each component has its own contract, its own failure mode, and its own upgrade path.
Step 2: Lock Down the Routing Contract
The router is the line item that compounds. Every call routed to a flagship model that a cheap-tier model could have handled is paid forever. Specify the contract before you wire the gateway.
Routing checklist:
- Tier names defined — at minimum:
cheap,default,escalation. Map each tier to a concrete model, not a vendor. - Per-step tier assigned — the planner step is not the same call as the summarizer step. Assign separately.
- Fallback chain ordered — if the primary model 5xx’s, what is the next? LiteLLM’s
fallbacksparameter handles this declaratively. - Context-length floor and ceiling — Claude Sonnet 4.6 took 1M-token context to GA at standard pricing on February 17, 2026 (Claude Help Center); your cheap tier almost certainly cannot match that. Decide which calls need the ceiling.
- Pricing snapshot recorded — the durable rate, not the promo. DeepSeek V4 Pro’s standard pricing is $1.74/M input and $3.48/M output as of May 2026, after the launch promo ended on May 5 (DeepSeek API Docs). DeepSeek V4 Flash sits at $0.14/M input cache-miss and $0.28/M output, which is the reference point for “cheap tier” decisions.
The Spec Test: If your routing config does not have a per-step tier mapping, you are not routing. You are defaulting.
Real verdicts to write into the spec, as of May 2026:
- MiniMax-M2.7 as your top open-weights tier. It reports 56.22% on SWE-Pro and 1495 ELO on GDPval-AA, the strongest in MiniMax’s M2 line at the time of writing (MiniMax News). Self-hosted, no vendor lock-in.
- DeepSeek V4 Pro and V4 Flash as your managed cheap tier. Standard rates above; cache hits price at one-tenth of the launch input rate across all DeepSeek models (DeepSeek API Docs). A 75% promotional discount is currently active through May 31, 2026 — treat it as a windfall, not a durable rate.
- Claude Sonnet 4.6 as your escalation tier when reasoning quality or 1M-token context actually matters. Anthropic’s release notes confirm 1M context at standard pricing (Claude Help Center).
These are starting points, not gospel. Run them through your evaluation suite on your own task distribution before you wire them as defaults. The same discipline applies to Agent Error Handling And Recovery — a cheaper model with a missing fallback chain is not cheaper, it is just less reliable for less money.
Step 3: Wire the Components — Cache First, Router Second, Budget Third
Order matters. Build the cache layer before you optimize the router, because a 90% input-discount on the wrong model still beats full-price calls to the right one. Then route. Then cap spend.
Build order:
- Prompt cache layer first — pick LiteLLM auto-injection or Helicone’s AI Gateway depending on your hosting model. LiteLLM injects cache checkpoints automatically and claims up to 90% savings on cached input tokens (LiteLLM Docs). Helicone caches prompts over 1,024 tokens and reads at one-tenth of input price for OpenAI, Grok, Groq, DeepSeek, Moonshot AI, and Azure OpenAI; Anthropic’s native caching is monitored automatically (Helicone Docs). DeepSeek’s own cache also reads at one-tenth of launch input price across all DeepSeek models (DeepSeek API Docs).
- Router second — once cache hits are landing, point your stable, cacheable system prompts at the cheap tier. Only escalate to flagship on demonstrated need. With OpenRouter, you get 300+ models behind one OAI-compatible endpoint and a flat 5.5% platform fee with an $0.80 minimum per transaction on card-managed inference, or 5% with no minimum on crypto (OpenRouter Announcements). BYOK runs the first 1M requests per month free and 5% of model cost above that — subject to change, since OpenRouter has announced a future shift to a fixed monthly subscription (OpenRouter Announcements).
- Budget caps third — LiteLLM exposes per-key, per-user, and per-team budgets with Slack alerts for thresholds, slow responses, and exceptions (LiteLLM Docs). Portkey delivers the same as a managed gateway with 1,600+ LLMs from $49 per month on the platform fee (Portkey Pricing, Portkey Gateway GitHub).
- Observability last — wire the chosen gateway’s trace export to your existing pipeline. See Agent Observability for the trace fields you actually need; cost per call is non-negotiable.
For each component, your context must specify:
- What it receives — model name, prompt body, cache key strategy, budget tier
- What it returns — token counts in/out, cache hit boolean, cost in dollars, fallback used
- What it must NOT do — silently rewrite the model, swallow cache invalidations, retry past the budget cap
- How it fails — gateway down, budget exceeded, all fallbacks exhausted
Security & compatibility notes:
- LiteLLM CVE-2026-42208 (CVSS 9.8): Critical SQL injection in proxy auth, affects v1.81.16–v1.83.6, fixed in v1.83.7 (Apr 19, 2026). Actively exploited within 36 hours of disclosure and currently in CISA KEV. Pin to v1.83.7 or later — latest stable is v1.83.14 (LiteLLM Security Blog, LiteLLM PyPI).
- LiteLLM PyPI supply-chain (March 2026): Malicious
litellm==1.82.7and1.82.8packages were live on PyPI for roughly 40 minutes on March 24, 2026 before quarantine. Pin versions and verify package hashes in CI (LiteLLM Security Blog).- OpenRouter BYOK fee model: The current 5% above-1M-requests fee is announced for replacement by a fixed monthly subscription. Date and price are not yet set — recheck before locking pricing copy in your own docs.
- Portkey Enterprise pricing: Third-party analyst figures ($5K–$10K/month range) circulate, but they do not come from Portkey’s own pricing page — treat as approximate.
Step 4: Prove the Savings — and the Quality
A cheaper invoice with a worse agent is not a win. Recovery and routing share the same trap: most teams test the happy path and ship.
Validation checklist:
- Cache-hit-rate test — replay a representative agent trace with cache enabled, then again with cache disabled. Failure looks like: cache hit rate near zero. Usually means an unstable token (timestamp, request ID, randomized example order) is invalidating the cache prefix.
- Tier-eligibility test — for each step, run cheap-tier and default-tier outputs against your eval suite. Failure looks like: cheap tier degrades quality measurably on planner or critique steps. Promote those specific steps; keep the rest on cheap tier.
- Fallback drill — block the primary model with a fault injector. Failure looks like: the gateway throws instead of falling through to the next entry in the chain.
- Budget-cap simulation — fire enough calls under a test key to trip the per-key budget. Failure looks like: calls keep landing after the cap, no Slack alert fires, or the escalation path to Human In The Loop For Agents approval is undefined for spend overrides.
- Promo-rate sanity check — recompute monthly cost using durable rates, not active promotions. Failure looks like: your forecast assumes the DeepSeek 75% discount, which expires May 31, 2026.
Pair every test with the observability trace fields so you can see — per call — model, cache hit, cost, and tier. A cost dashboard with no per-call trace is a black box that will surprise you on the first of the month.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
Hard-coded gpt-5 (or claude-sonnet-4-6) in agent code | Every call paid flagship rates regardless of need; no per-step tiering | Move model selection into the gateway with named tiers and per-step mapping |
| Put a timestamp or request ID into the system prompt | Cache prefix invalidated on every call; reported hit rate near zero | Move volatile fields out of the cached prefix; cache the stable instruction, vary only the user turn |
| Skipped cache for “small” prompts | Helicone’s automatic cache kicks in above 1,024 tokens; calls below the floor never benefit anyway | Reduce per-step prompt size or batch context so the cacheable prefix crosses the threshold |
| Trusted promo pricing in the forecast | Forecast collapses when the promo ends (DeepSeek V4 Pro promo ended May 5, 2026; current discount expires May 31) | Forecast against the durable rate; treat promos as buffer, not budget |
| Ran LiteLLM proxy at v1.83.6 or below | CVE-2026-42208 enables SQL injection in proxy auth — actively exploited | Pin to v1.83.7 or later (latest stable is v1.83.14); verify package hashes in CI |
| No alerts on per-key spend | Finance discovers the overrun before engineering does | Set per-key, per-user, per-team budgets in LiteLLM or Portkey with Slack thresholds below the hard cap |
Pro Tip
Every cost contract has a partner: the cache-stability contract. Before you celebrate a routing optimization, ask one question — does my prompt template keep its prefix byte-identical across calls? If a single character moves (a re-ordered tool list, a re-randomized few-shot block, a millisecond timestamp), the cache prefix breaks and the savings vanish. Lock the prefix. Sort tool definitions deterministically. Pin example order. Keep volatile fields below the cacheable boundary. This single discipline often saves more than picking a cheaper model.
Frequently Asked Questions
Q: How to build a cost-optimized agent pipeline with OpenRouter and LiteLLM in 2026?
A: Use them in layers, not as alternatives. OpenRouter gives you managed access to 300+ models behind an OpenAI-compatible API at a 5.5% platform fee (card) or 5% (crypto). LiteLLM runs in your infra as the budget and routing brain — per-key budgets, Slack alerts, four router strategies. The combination: OpenRouter for breadth of model access, LiteLLM for spend control. Pin LiteLLM at v1.83.7 or later because of CVE-2026-42208.
Q: How to use Helicone and Portkey for prompt caching and budget control in production agents?
A: Helicone’s AI Gateway caches prompts over 1,024 tokens automatically and reads at one-tenth of input price for OpenAI-style providers — wire it before tuning your router. Portkey gives you guardrails plus access to 1,600+ models from $49 per month platform fee. Use Helicone if cache savings are your top lever; use Portkey when guardrails and policy enforcement matter as much as cost.
Q: How to route between cheap and expensive models like MiniMax-M2.7, DeepSeek V4 Pro, and Claude Sonnet 4.6?
A: Tier them in your gateway, not in agent code. As of May 2026: MiniMax-M2.7 as your open-weights cheap tier (top open-source on SWE-Pro and GDPval-AA), DeepSeek V4 Flash as your managed cheap tier at $0.14/$0.28 per million tokens, DeepSeek V4 Pro as your mid tier at $1.74/$3.48, and Claude Sonnet 4.6 as escalation when 1M-token context or top-tier reasoning is required. Promote per-step based on your eval suite, not by feel.
Your Spec Artifact
By the end of this guide, you should have:
- A four-layer cost map naming which library or service owns routing, caching, budget, and observability — no overlaps, no gaps
- A per-step tier mapping (
cheap/default/escalation) with concrete model names, durable pricing, and fallback chains - A validation matrix listing cache-hit-rate, tier-eligibility, fallback drill, budget cap, and promo-rate checks with pass criteria for each
Your Implementation Prompt
Drop this into Claude Code, Cursor, or Codex once you have your four-layer cost map. The prompt mirrors the steps and asks the AI to fill in the specification, not write the gateway code for you.
You are designing the cost-control layer for a production AI agent.
Gateway choice: [LiteLLM self-hosted / Helicone managed / Portkey managed / OpenRouter only]
Pinning: [LiteLLM v1.83.7+ if using LiteLLM; document exact version]
Observability: [Logfire / OpenTelemetry / Langfuse / Helicone built-in]
Step 1 — Component ownership
For each layer, name the library and the contract surface:
- routing: [library, router strategy, fallback chain]
- caching: [library, cache key strategy, minimum-prompt-length floor]
- budget: [library, per-key/user/team caps, alert channel]
- observability: [library, exported fields per call]
Step 2 — Tier mapping per call site
For each step in the agent graph, specify:
- step name: [e.g., planner / executor / critic / summarizer]
- tier: [cheap / default / escalation]
- primary model: [exact model id]
- fallback chain: [ordered list]
- context-length need: [tokens]
- durable price: [input $/M, output $/M — NOT promo rates]
Step 3 — Cache stability contract
List volatile fields that MUST stay outside the cached prefix:
[timestamps, request IDs, randomized examples, user-specific identifiers]
List stable fields that belong inside the cached prefix:
[system instruction, tool definitions sorted deterministically, few-shot examples in fixed order]
Step 4 — Validation tests
Write pass criteria for:
- cache hit rate target on a representative replay
- per-step quality non-regression against the current eval suite
- fallback drill outcome when primary returns 5xx
- budget-cap trip and alert delivery
- forecast recomputed against durable rates, not active promotions
Output: a single markdown spec document with one section per step.
Do NOT generate framework code. Generate the specification only.
Ship It
You now have a four-layer cost model — route, cache, budget, observe. Each layer is its own contract you can specify, test, and replace. The next time the invoice doubles, you will know exactly which contract drifted — and you will fix that layer instead of rewriting the agent.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors