How to Choose and Use Claude Code, Codex, Cursor, and Devin for Real Engineering Work in 2026
Table of Contents
TL;DR
- The tool isn’t the choice. The autonomy level is. Interactive pair-coding, semi-autonomous tasks, and fully autonomous tickets each want a different agent.
- A coding agent is only as good as the context you hand it. Stack, contracts, tests, and MCP Server wiring are the spec — everything else is decoration.
- Benchmarks rank models, not workflows. Pick by where the tool runs (terminal, IDE, sandbox VM) and what it can touch, then by score.
It’s Tuesday. You have three subscriptions running on the same machine. Cursor is open in one window. Claude Code is in your terminal. Devin is grinding through a ticket in a sandbox VM somewhere. By Friday you’ll have shipped a feature, a half-finished refactor, and a bill you don’t want to explain. The problem isn’t the tools. The problem is that nobody specified which tool owns which job — that’s not engineering, that’s Vibe Coding with extra steps.
Before You Start
You’ll need:
- One paid subscription to Claude Code, Codex CLI, Cursor, or Devin — pick after Step 1, not before
- A working understanding of Agentic Coding as a category (an agent reads, writes, executes, and iterates — not just autocompletes)
- A repo you actually know. AI tools amplify clarity; they amplify confusion too
- Git on a feature branch. Nothing in this guide is safe to run on
main
This guide teaches you: how to match autonomy level to task, then specify context tightly enough that the agent does what you meant — not what its training data assumed.
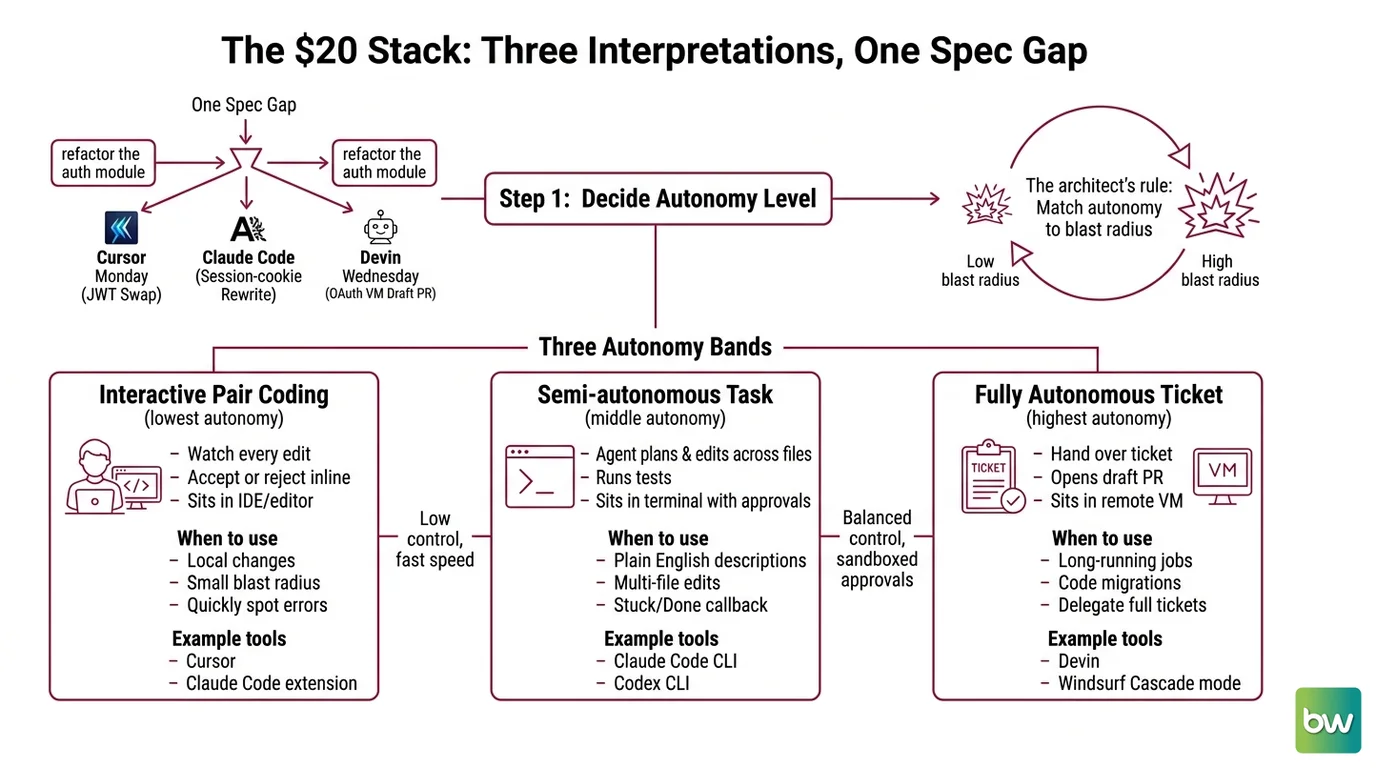
The $20 Stack That Built Three Different Things
You typed “refactor the auth module” into Cursor on Monday. You got a working JWT swap. You typed the same sentence into Claude Code on Tuesday. You got a session-cookie rewrite with three new dependencies. You typed it into Devin on Wednesday. Devin spun up a VM, opened a draft PR, and added an OAuth provider you never asked for.
Three tools. Three interpretations. One spec gap.
The agents weren’t broken. The prompt never told them which auth pattern your repo already uses, which dependencies are off-limits, and what “refactor” means in your team’s vocabulary. Each tool filled the gap with its own default — and each default came from a different training set.
It worked on Monday because Cursor’s IDE-mode let you stop it after 30 seconds. It broke on Wednesday because Devin doesn’t stop. That’s the whole game.
Step 1: Decide Which Autonomy Level the Task Wants
Stop picking by brand. Pick by how much rope you want the agent to have.
There are three autonomy bands:
- Interactive pair coding — you watch every edit, accept or reject inline. Tool sits in your IDE or editor. Use it when the change is local, the blast radius is small, and you can spot a wrong turn in five seconds. Cursor and the Claude Code VS Code extension live here.
- Semi-autonomous task — you describe the work in plain English, the agent plans, edits across files, runs tests, comes back when it’s stuck or done. Tool sits in your terminal with sandboxed approvals. Claude Code CLI and Codex CLI live here.
- Fully autonomous ticket — you hand over a ticket, the agent opens a draft PR. Tool sits in a remote VM you don’t manage. Devin lives here, and this is also the band where long-running AI Code Migration jobs (framework upgrades, language ports) finally make sense to delegate. Windsurf’s Cascade mode is heading the same direction now that Cognition owns both.
The Architect’s Rule: Match autonomy to blast radius. Hot path, prod-adjacent code, schema migrations — keep the human in the loop. Boilerplate, scaffolding, deterministic refactors — let the agent run.
Pricing-band sanity check (current rates): Cursor Pro is $20/month, Cursor Ultra is $200/month per Cursor Docs. Claude Code Pro is $20/month, Max 5x is $100/month, Max 20x is $200/month per the Anthropic Claude Code page. Devin Pro dropped to $20/month, Devin Max sits at $200/month per the Devin pricing page. Windsurf Pro is $15/month per the Windsurf pricing page. Same price band, very different products — Cursor Ultra and Devin Max both cost $200, but one gives you an IDE and the other gives you a remote engineer.
Step 2: Lock Down the Spec Before You Pick a Tool
A coding agent doesn’t read minds. It reads context. The context you provide is the contract — and most “AI failed me” stories are contract failures.
Context checklist — every agent needs all of this:
- Tech stack and versions (Node 22, Python 3.13, Postgres 16 — be exact)
- Framework conventions (your team’s lint rules, naming, file layout)
- The change boundary (which files it can touch, which it cannot)
- Input/output contracts (function signatures, API shapes, schema versions)
- Test commands and what “green” looks like
- Failure handling (raise, log, retry — the agent will guess otherwise)
- Off-limits patterns (no new deps, no
any, noeval)
Where each tool reads context from:
- Claude Code —
CLAUDE.mdat repo root plus per-folderCLAUDE.mdfiles. Skills 2.0 and subagents pull from.claude/skills/and.claude/commands/, both unified per Claude Code Docs (changelog). Subagents run with isolated context windows so a research probe doesn’t poison your main session. - Codex CLI —
AGENTS.mdat repo root, an MCP server config, and CLI flags. The TUI shows approval prompts before each sandboxed action per OpenAI Codex Docs. - Cursor —
.cursorrulesfile plus the chat history of your current session. Max Mode opens the context window to 1M tokens for supported models per Cursor Docs, which is the only setting where you can drop an entire mid-sized repo into a single turn. - Devin — repo readme, ticket text, and whatever it reads on its own when it boots the sandbox. The agent doesn’t pause to ask, so the spec has to be in the ticket.
The Spec Test: If your context file does not specify the framework version and the error-handling pattern, the agent will pick what it has seen most often in training. That choice will be plausible. It will also be wrong about half the time.
Step 3: Wire the Agent Into Your Stack via MCP
A naked agent reads files. A wired agent reads your database, your Linear board, your Sentry errors, your design system. That’s the difference between “wrote some code” and “shipped a working feature.” The protocol that does the wiring is the Model Context Protocol.
Build order for an agentic workflow:
- Start with the agent’s native tooling. Claude Code and Codex CLI both ship with file edits, shell exec, and a sandbox. That is enough for 80% of work — do not over-engineer the wiring before you need it.
- Add one MCP server at a time. Per Claude Code Docs (MCP), MCP defines three primitives: tools (functions the agent can call), resources (data the agent can read), and prompts (templates the agent can invoke). Pick the one connector that unblocks your next task — usually GitHub, a database, or a project tracker.
- Pin transports. Per Claude Code Docs (MCP), MCP supports local stdio and HTTP (recommended for remote). Use stdio for local dev tools, HTTP for anything that lives outside your machine. Mixing them without a spec is the fastest way to get “connection refused” at 11pm.
- Source servers from a known registry. The official catalog is the
modelcontextprotocol/serversrepo on GitHub per the MCP GitHub source. Third-party servers exist but get the same scrutiny as any other dep — read the code, scope the credentials.
For each MCP server you wire in, the context must specify:
- What it receives (which queries, which write scopes)
- What it returns (data shape — JSON, plain text, paginated)
- What it must NOT do (no destructive ops without confirmation, no cross-tenant queries)
- How to handle failure (timeout, retry, surface to the user)
Codex CLI added MCP support in the same release wave per OpenAI Codex Docs, so the same servers work across Claude Code and Codex. Cursor reads MCP servers too. The spec travels — the tool is interchangeable.
Security & compatibility notes:
- Claude Code billing change (June 15, 2026): Per FindSkill.ai, programmatic Claude Code usage moves to a separate monthly credit pool at API rates — Pro gets $20 credit, Max 5x gets $100, Max 20x gets $200. Heavy automation workflows will see a real cost change. Action: meter your background subagent usage before the cutover and budget the API spend separately.
- Windsurf is no longer independent: Per Verdent Guides, Cognition (maker of Devin) acquired Windsurf and the roadmap is now merged with Devin tooling. Action: do not bet a multi-year workflow on standalone Windsurf — assume convergence with Devin’s autonomous agent model.
Step 4: Validate the Agent Did What You Asked
You ran the agent. It says “done.” That’s a claim, not proof. Now test the claim.
Validation checklist:
- Does the code compile and lint? — failure looks like: red squiggles, type errors, the agent left a
TODO: fix importsit forgot to circle back to - Do the tests pass? — failure looks like: agent wrote tests for the happy path only, skipped the edge cases listed in your spec, or stubbed assertions
- Does the diff stay inside the change boundary? — failure looks like: edits in files you said were off-limits, new dependencies in
package.json, drift into unrelated modules - Does it actually do the thing? — failure looks like: agent wrote a function with the right name and wrong behavior; happens more than you’d think
- Does the agent’s plan match what shipped? — failure looks like: the plan said “swap auth provider,” the diff also rewrote your logger. Read the diff against the plan, not against your assumptions
For autonomous agents the validation step is the whole job. Devin opens a draft PR — review it like a junior engineer’s PR. SWE-bench scores tell you the ceiling, not the floor. Per llm-stats, Claude Sonnet 4.5 leads the agentic SWE-bench Verified leaderboard at 77.2%, and per Morph LLM the same top models score far lower on contamination-free SWE-bench Pro (around 45.9% for the Mythos Preview leader). Treat the high number as a best case under ideal benchmark conditions, not a promise for your repo.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| “Refactor X” with no boundary | Agent decided what “refactor” means — usually more than you wanted | List files in scope and files off-limits in the prompt |
| Picked the tool by leaderboard score | Benchmarks measure model capability, not workflow fit | Pick by autonomy band first, model score second |
| Ran Devin without a sharp ticket | Autonomous agents do not pause to ask — the spec is the whole interface | Write the ticket like a contract: acceptance criteria, off-limits, test command |
| Wired five MCP servers on day one | Each server is a new attack surface and a new failure mode | Add one server, validate it, then add the next |
| Trusted “tests pass” without reading the tests | Agent can write green-by-default tests that assert nothing | Read the test bodies before you trust the green |
Pro Tip
The agent that reviews the diff should not be the same agent that wrote it. Pair a writer agent (Claude Code, Codex) with a reader agent (a fresh Claude Code session, a Cursor inline review, or human eyes) and the catch rate jumps. Same model, different context window, no shared assumptions. The diff stops being self-marking homework and starts being a real review.
Frequently Asked Questions
Q: How to use Claude Code for full-stack development in 2026?
A: Run Claude Code in your terminal with one CLAUDE.md at the repo root and a per-folder CLAUDE.md for each major surface (frontend, API, infra). Wire MCP servers for your database and your project tracker so the agent can read schema and tickets directly. The 1M-token context window (GA March 2026 per CloudZero) means you can fit a mid-sized repo in one turn — but you still need the spec files, because the model treats them as priority context. Watch the June 15, 2026 billing change if you script background subagent runs.
Q: When should you choose Devin or Windsurf over Cursor for autonomous coding tasks? A: Choose Devin when the task can be specified as a ticket — clear acceptance criteria, no mid-flight decisions, fine with a draft PR you’ll review. Choose Cursor when you want to watch the agent edit and intervene live. Windsurf’s Cascade mode sits between them, but per Verdent Guides Cognition’s acquisition means Windsurf and Devin are converging — assume the autonomous mode will look more like Devin over time, not less.
Q: How to set up an agentic coding workflow with Claude Code and MCP servers?
A: Install Claude Code, add a CLAUDE.md with stack, conventions, and test commands. Pick one MCP server from the official modelcontextprotocol/servers repo — usually GitHub or your database. Configure it with a least-privilege scope. Validate the agent can read what it needs and cannot write what it shouldn’t. Then add the next server. Wiring five servers on day one is how you ship a security incident, not a feature.
Your Spec Artifact
By the end of this guide, you should have:
- A decision map — which tool owns interactive, semi-autonomous, and autonomous work in your stack, written down where your team can read it
- A context contract per tool —
CLAUDE.md,AGENTS.md,.cursorrules, or ticket template with stack, conventions, boundaries, tests, and off-limits - A validation checklist — the five questions you ask every agent diff before merge
Your Implementation Prompt
Paste this into Claude Code, Codex CLI, or Cursor at the start of a new task. Fill in the brackets with your own values. The structure mirrors Steps 1-4 so the agent can follow the same plan you did.
You are working in a [Node 22 / Python 3.13 / your stack here] repo.
The change boundary is: [list of files or folders the agent CAN edit].
Off-limits: [list of files, folders, or patterns the agent must NOT touch].
Conventions: [link to or paste your lint config, naming rules, file layout].
Contracts: [function signatures, API shapes, schema versions this change must respect].
Off-limits dependencies: [packages or patterns banned in this repo].
Failure handling: [raise / log / retry — pick one and name it].
Tests pass when: [exact command, e.g. "npm test -- --runInBand" returns 0].
Task: [one sentence describing what you want].
Plan first. Show me the file list and the approach before you edit.
Stop and ask if any of the constraints above conflict with the task.
When done, summarize the diff against the plan, not against the task.
Ship It
You now have a decision frame that survives the next model release. Tools will swap models. Models will swap leaderboards. Prices will shift again before the year ends. What stays is the spec — the autonomy band, the context contract, the validation checklist. Write those once per project and the next agent that ships in six months slots into the same workflow.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors