Planning Agents in Practice: ReAct, Plan-and-Execute, and Reflexion
Table of Contents
TL;DR
- Pick the planning pattern first — ReAct, Plan-and-Execute, Reflexion, or ReWOO. Pick the framework second.
- LangGraph 1.0 is the production default in 2026, but
langgraph.prebuilt.create_react_agentis deprecated. New code useslangchain.agents.create_agentfor middleware support. - AutoGen is in maintenance mode. For new production multi-agent systems, Microsoft recommends Microsoft Agent Framework 1.0 instead.
A team I sat with last month had an agent that ran for thirty iterations, burned through a four-figure tool budget, and never returned an answer. They blamed the model. The model was fine. The Agent Planning And Reasoning pattern was wrong for the task — and nobody had written down what pattern they were even using.
That’s the failure mode this guide kills.
Before You Start
You’ll need:
- A foundation reasoner — Claude Sonnet 4.5, GPT-5.3 Codex, Gemini 2.5 Pro Experimental, or DeepSeek-R1 are the production-grade options as of April 2026.
- LangGraph 1.0+, CrewAI 1.14+, or AutoGen 0.7.x installed.
- A working understanding of Agent Memory Systems — you’ll need it for Reflexion.
- A task with a binary success criterion. If you can’t define “done,” you can’t ship.
This guide teaches you: How to match a planning pattern to your task shape, then implement it on the right framework without fighting the abstractions.
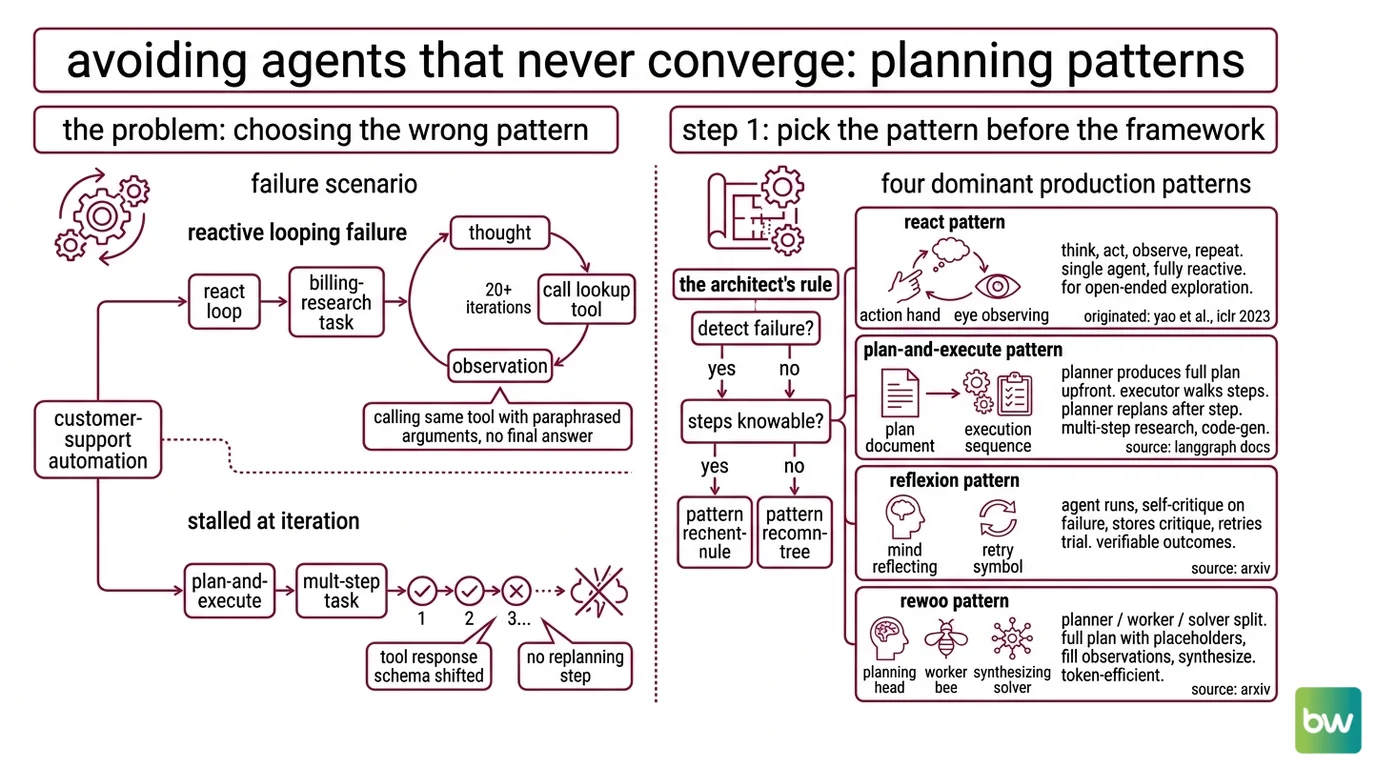
The Agent That Never Converges
Real failure I watched on a customer-support automation: developer wires up a ReAct loop, hands the agent a billing-research task, walks away. Twenty iterations later the agent is still calling the same lookup tool with paraphrased arguments. No final answer. The model wasn’t broken. The pattern was wrong — the task wanted Plan-and-Execute, not reactive looping.
It worked on Friday. On Monday, the same agent stalled at iteration thirty because a tool’s response schema shifted by one field and the planner had no replanning step to recover.
Step 1: Pick the Planning Pattern Before the Framework
The single biggest mistake in 2026 agent builds: choosing the framework first. LangGraph, CrewAI, AutoGen — they’re hosts. The thing that decides whether your agent works is the planning pattern underneath.
Four patterns dominate production agents:
- ReAct — Think → Act → Observe → repeat. Single agent, fully reactive. Good for tasks where you can’t enumerate the steps. Originated in Yao et al., ICLR 2023 (arXiv).
- Plan-and-Execute — A planner produces a full plan upfront, an executor walks each step, and the planner replans after each step. Good for multi-step research and code-gen with knowable structure (LangGraph Docs).
- Reflexion — Agent runs, generates verbal self-critique on failure, stores the critique in episodic memory, retries the trial. Strong on tasks with verifiable outcomes (arXiv).
- ReWOO — Planner / Worker / Solver split. Planner emits a full plan with placeholder evidence, workers fill in observations, solver synthesizes. Significantly more token-efficient than ReAct on benchmarks where the planner can produce sound plans without intermediate observations (arXiv).
The Architect’s Rule: If your task has a measurable outcome and you can detect failure, you can layer Reflexion on top. If exploration is open-ended, ReAct. If steps are knowable upfront, Plan-and-Execute. If token cost dominates and the plan can be sound from the prompt alone, ReWOO.
The pattern is your spec for where uncertainty is allowed to live. Get this wrong and no framework saves you.
Step 2: Lock Down the Contract Before You Touch a Framework
Each pattern needs a different contract. Skip this step and the framework choice doesn’t matter — your agent will fail in framework-specific ways instead of pattern-specific ways.
Context checklist for any agent build:
- Reasoning model named with version (e.g., Claude Sonnet 4.5, GPT-5.3 Codex)
- Tool list with input and output schemas — not just names
- Termination condition (iteration cap and success criterion as a function)
- State you’re persisting (full message history, observations only, or external memory store)
- Error handling for tool failures (retry, replan, escalate, fail fast)
- Cost ceiling per task
The Spec Test: If you can’t write the success criterion as a function
is_done(state) -> bool, you don’t have a spec. You have a hope. Hope-driven agents are how the team I mentioned earlier got to thirty iterations.
How to implement a ReAct agent with LangGraph step by step in 2026?
ReAct on LangGraph 1.0 has one moving part you have to get right: the prebuilt entrypoint changed. Per the LangChain Docs migration guide, langgraph.prebuilt.create_react_agent still functions in v1.x but emits deprecation guidance. New code should use langchain.agents.create_agent, which runs on LangGraph and adds a middleware layer.
The decomposition stays the same:
- Pick the reasoning model and bind tools to it.
- Define tools as type-hinted functions with clear input and output schemas.
- Compose the agent —
create_agent(model, tools=[...], prompt=...). - Add middleware for cost limiting, redaction, and human-in-the-loop without rewriting the graph.
The middleware hooks are the new value, per LangChain Docs: before_model, after_model, modify_model_request, plus @wrap_tool_call, with built-in human-in-the-loop and summarization middleware shipped out of the box. That’s the reason to migrate, not just compatibility.
Security & compatibility notes:
langgraph-prebuilt==1.0.2install break: Adds a requiredruntimeparameter toToolNode.afunc.langgraph==1.0.1does not constrain this dependency, so a fresh install can pull both and break (LangGraph GitHub Issue #6363). Action: pin compatible pairs or upgrade to the matching versions.create_react_agentdeprecation: Still functional in LangGraph 1.x, but new builds should uselangchain.agents.create_agentto access middleware (LangChain Docs).- AutoGen maintenance mode: Use AutoGen 0.7.x for prototyping; new production multi-agent systems should target Microsoft Agent Framework 1.0 (GA April 2026, per Microsoft DevBlogs).
- CrewAI 0.x → 1.x: Tutorials predating October 2025 may use APIs that no longer match
crewai>=1.0(CrewAI Blog).
When to use Plan-and-Execute vs ReAct vs ReWOO for agent workflows?
Three patterns. Three different specs.
Plan-and-Execute fits when:
- The task decomposes into a small set of knowable steps.
- Cost matters more than latency.
- You want auditability — the plan is reviewable before execution.
ReAct fits when:
- You can’t enumerate steps upfront.
- The model needs to react to each observation.
- You want a single-shot answer with iterative tool calls.
ReWOO fits when:
- Token budget is tight.
- Steps are knowable but observations are expensive.
- You want to parallelize the worker step.
The wrong pattern wastes far more tokens than the right one for the same task. ReWOO’s reported token efficiency on HotpotQA (arXiv) only generalizes to tasks where the planner can produce a sound plan from the prompt alone. Use it on open-ended exploration and you’ll get unrecoverable plans.
Step 3: Wire the Framework to the Pattern
Now the framework choice matters. Each one has a sweet spot.
Build order:
- Define the task contract. Input schema, output schema, success criterion. Framework-independent.
- Pick the framework that hosts your pattern cleanly:
- LangGraph 1.0 for graph-shaped agents. ReAct, Plan-and-Execute, Reflexion, and ReWOO all map to its node-and-edge model. Per LangChain Blog, v1.0 went GA on 2025-10-22 with an LTS commitment of no breaking changes until 2.0; the 0.x line stays in maintenance through December 2026.
- CrewAI 1.14.4 for role-based
Multi Agent Systems with explicit role/goal/backstory agents and sequential, hierarchical, or consensual processes (CrewAI Docs). Flows add an event-driven layer with
@start,@listen,@router,or_, andand_. - AutoGen 0.7.x for prototyping conversational multi-agent loops. AgentChat is the high-level API; Core is the event-driven actor layer from v0.4. Treat it as a research and prototyping tool — not the strategic forward path for new production work.
- Build the smallest end-to-end loop first. One model, one tool, one termination condition. Get a single happy-path run before you add planning, memory, or human-in-the-loop.
- Add durability last. LangGraph ships checkpointing, persistence, streaming, and human-in-the-loop as first-class primitives in v1 (LangChain Docs). Use them. Don’t reinvent.
For each component, your context must specify:
- What it receives — planner input, worker input, solver input.
- What it returns — plan format, tool-call format, final-answer schema.
- What it must NOT do — recursion depth limits, tool allow-lists, write-side restrictions.
- How to handle failure — retry with new plan, escalate to human, or fail fast.
How to add Reflexion self-correction to an existing agent in 2026?
Reflexion is a layer, not a framework. You add it on top of any of the four patterns above.
The decomposition:
- Trial loop — your existing agent runs the task.
- Evaluator — judges success or failure with a measurable criterion (test suite passes, output matches schema, ground-truth match).
- Reflector — on failure, generates verbal self-critique: what went wrong, what to try next.
- Episodic memory — stores reflections across trials; the next trial’s prompt includes the previous critiques.
In LangGraph 1.0, the natural shape is a graph with three nodes (act, evaluate, reflect) and a conditional edge that loops back to act when evaluate returns failure and the trial counter is below the cap. The reflector’s output appends to a list in graph state.
The non-negotiable spec: Reflexion only works if the evaluator is reliable. If the evaluator is noisy, the reflector is critiquing nothing. Shinn et al.’s strong pass@1 result on HumanEval (arXiv) used unit tests as the evaluator — a hard, binary signal. Replicate that fidelity in your domain or skip the pattern.
Step 4: Prove It Works Before You Trust It
Validation for an agent is not “did it return something.” It’s “did it return the right thing within the budget.”
Validation checklist:
- Termination correctness — failure looks like: agent exits before
is_doneis true, or runs to the iteration cap on every task. - Token-budget compliance — failure looks like: 95th-percentile cost per task is several times higher than the median, signalling unbounded retry loops.
- Tool-call shape — failure looks like: agent calls tools with malformed arguments on a fraction of runs (typically a planner hallucinating fields).
- Pattern fidelity — failure looks like: a Plan-and-Execute agent that never replans, or a Reflexion agent whose critiques don’t actually change subsequent prompts.
- Foundation-model swap — failure looks like: agent works on Claude Sonnet 4.5 but falls apart on Gemini 2.5 Pro at the same temperature. That’s a sign your prompt overfit one model’s idiosyncrasies.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Started with “I’ll use LangGraph” | Picked host before pattern; ended up forcing ReAct on a task that wanted Plan-and-Execute | Decide pattern from task shape first; framework second |
| Copied a tutorial from early 2025 | CrewAI 0.x APIs don’t carry to 1.x; LangGraph prebuilt examples emit deprecation guidance | Read the migration guide for your framework’s current major version before starting |
| Set a high iteration cap “to be safe” | Agent burned budget on broken loops instead of failing fast | Cap iterations and require monotonic progress per step (e.g., observation count, plan completion) |
| Bet AutoGen as the strategic forward path | AutoGen is in maintenance mode as of 2026 | Prototype on AutoGen 0.7.x; target Microsoft Agent Framework 1.0 for new production multi-agent systems (Microsoft DevBlogs) |
| Skipped the evaluator on Reflexion | Reflector critiqued nothing because failure detection was noisy | Make is_done and is_failure binary, deterministic functions before adding self-correction |
Pro Tip
Every planning pattern is a contract about where the model gets to be uncertain. ReAct says: be uncertain about each next step. Plan-and-Execute says: be uncertain about steps but commit to a plan. ReWOO says: be uncertain about evidence but not about plan shape. Reflexion says: be uncertain across trials, certain within a trial.
Decide where uncertainty lives in your task, and the pattern picks itself.
Frequently Asked Questions
Q: How to implement a ReAct agent with LangGraph step by step in 2026?
A: Use langchain.agents.create_agent with your reasoning model, tool list, and a system prompt that names the success criterion. The legacy langgraph.prebuilt.create_react_agent still works but emits deprecation guidance and skips the middleware layer. Watch out for the install issue in #6363 — pin langgraph and langgraph-prebuilt versions together so a fresh install doesn’t pull a mismatched pair.
Q: When to use Plan-and-Execute vs ReAct vs ReWOO for agent workflows? A: Plan-and-Execute when steps decompose into a small set of knowable items and you want an auditable plan. ReAct when next steps depend on observations. ReWOO when token cost dominates and the planner can produce a sound plan without intermediate evidence. One subtlety the article doesn’t cover: ReWOO’s worker step parallelizes naturally on async runtimes, so latency wins compound on top of the token-efficiency gains.
Q: How to add Reflexion self-correction to an existing agent in 2026? A: Wrap your existing agent in a trial loop with an evaluator and a reflector node, and store reflections in episodic memory that feeds back into the next trial’s prompt. The make-or-break detail: the evaluator must produce a binary, deterministic success signal. Reflexion fails silently when the evaluator is noisy — the reflector ends up critiquing the wrong thing across trials and confidence in the system erodes without an obvious symptom.
Your Spec Artifact
By the end of this guide, you should have:
- A pattern selection decision — ReAct, Plan-and-Execute, Reflexion, or ReWOO — with a one-sentence reasoning.
- A filled-in context checklist — model, tools, termination condition, persisted state, error handling, cost ceiling.
- A validation criterion — a binary
is_donefunction, a token budget, and pattern-fidelity checks.
Your Implementation Prompt
Drop this into Claude Code, Cursor, or Codex when you’re ready to scaffold the agent. It mirrors the four steps above. Fill in the brackets with your specific values before running it.
You are scaffolding a planning agent. Build it in this order.
## Step 1 — Pattern (chosen)
Pattern: [ReAct | Plan-and-Execute | Reflexion | ReWOO]
Reasoning for choice: [one sentence — why this pattern matches the task shape]
## Step 2 — Contract
Reasoning model: [model name + version, e.g., Claude Sonnet 4.5]
Tools: [list each with input schema and output schema]
Termination: [iteration cap N AND success criterion as a binary function is_done(state) -> bool]
State persisted: [full messages | observations only | external memory store]
Error handling: [retry policy | replan policy | escalation rule]
Cost ceiling per task: [USD or token count]
## Step 3 — Framework + Build
Framework: [LangGraph 1.0 | CrewAI 1.14+ | AutoGen 0.7.x | Microsoft Agent Framework 1.0]
Build order:
1. Smallest end-to-end loop with one tool, one model, one termination condition.
2. Add the chosen pattern's required nodes and edges.
3. Add durability (checkpointing, persistence, human-in-the-loop) only after the smallest loop runs green.
For each agent or node, specify:
- inputs (schema)
- outputs (schema)
- forbidden actions (recursion depth, tool allow-list)
- failure handling (retry, replan, escalate, fail fast)
## Step 4 — Validation
Write tests that fail loud on:
- termination correctness (no early exit, no iteration-cap exhaustion)
- token-budget compliance (P95 within 2x of P50)
- tool-call shape (no malformed arg payloads)
- pattern fidelity (Plan-and-Execute actually replans; Reflexion actually changes prompts across trials)
- foundation-model swap (works on a second reasoner without prompt rewrite)
Output: working agent + validation harness, no code outside these constraints.
Ship It
You now have a decision framework, not a tutorial. The pattern fits the task. The framework hosts the pattern. The spec keeps the AI from filling gaps with its own assumptions. Future builds compound on this — the failure modes you’ll hit next are different ones, not the same ones again.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors