Choose Your Multi-Agent Topology Before You Pick a Framework
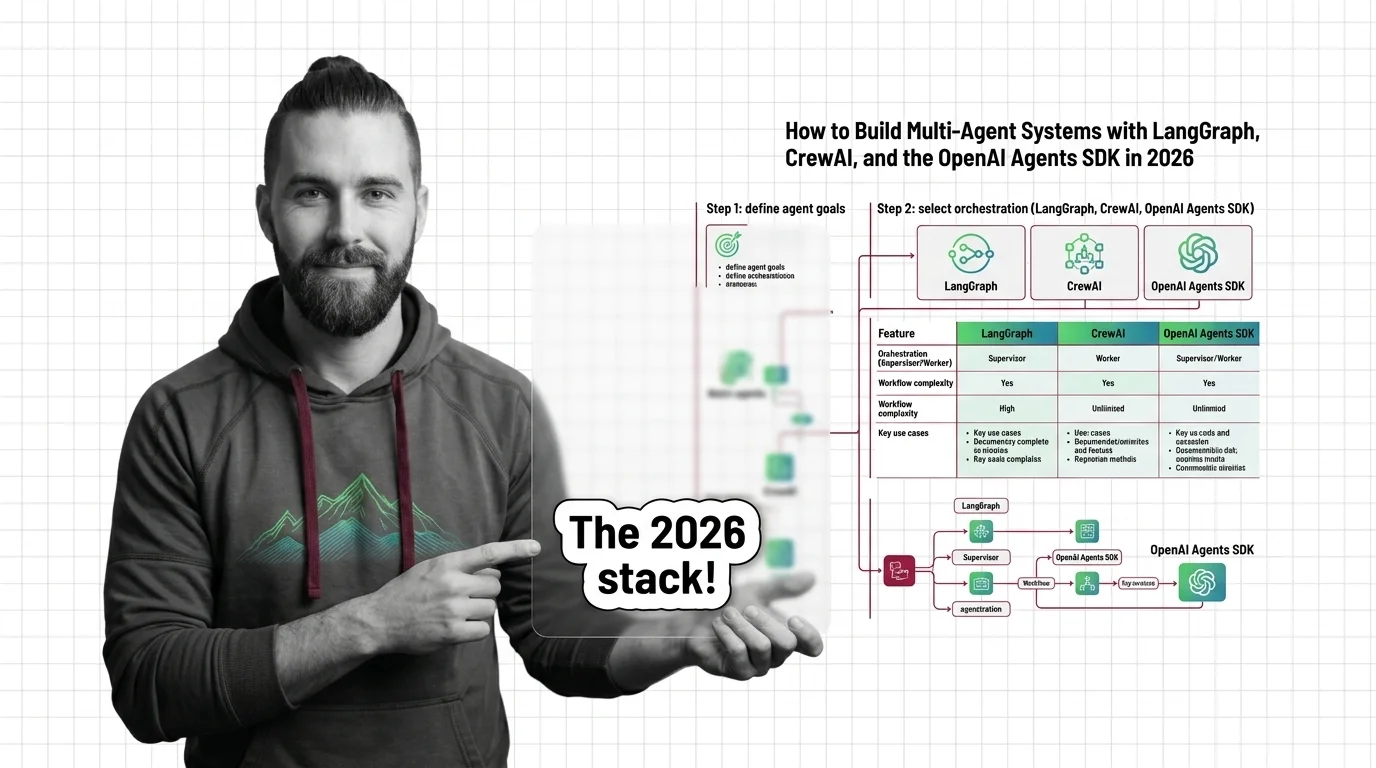
Table of Contents
TL;DR
- Pick the framework based on workflow shape: graph for stateful production, role-based crew for fast prototypes, handoff for transfer-of-control flows.
- The topology — supervisor, swarm, or hierarchy — is your spec. Choose it before you choose a framework.
- Multi-agent debate is a pattern you build on top of a framework, not a feature you toggle inside one.
Six agents. Three frameworks. A demo that worked Friday and broke Monday. The bug isn’t in the framework — it’s in the topology you picked before you picked the framework.
Before You Start
You’ll need:
- An AI coding tool (Cursor, Claude Code, or Codex)
- Familiarity with Multi Agent Systems as separate processes that exchange messages and divide a task
- A clear picture of which agent owns which decision, not just which task
This guide teaches you: how to decompose a multi-agent system into supervisor, specialists, and handoffs before you commit to LangGraph, CrewAI, or the OpenAI Agents SDK.
The Demo That Worked Once
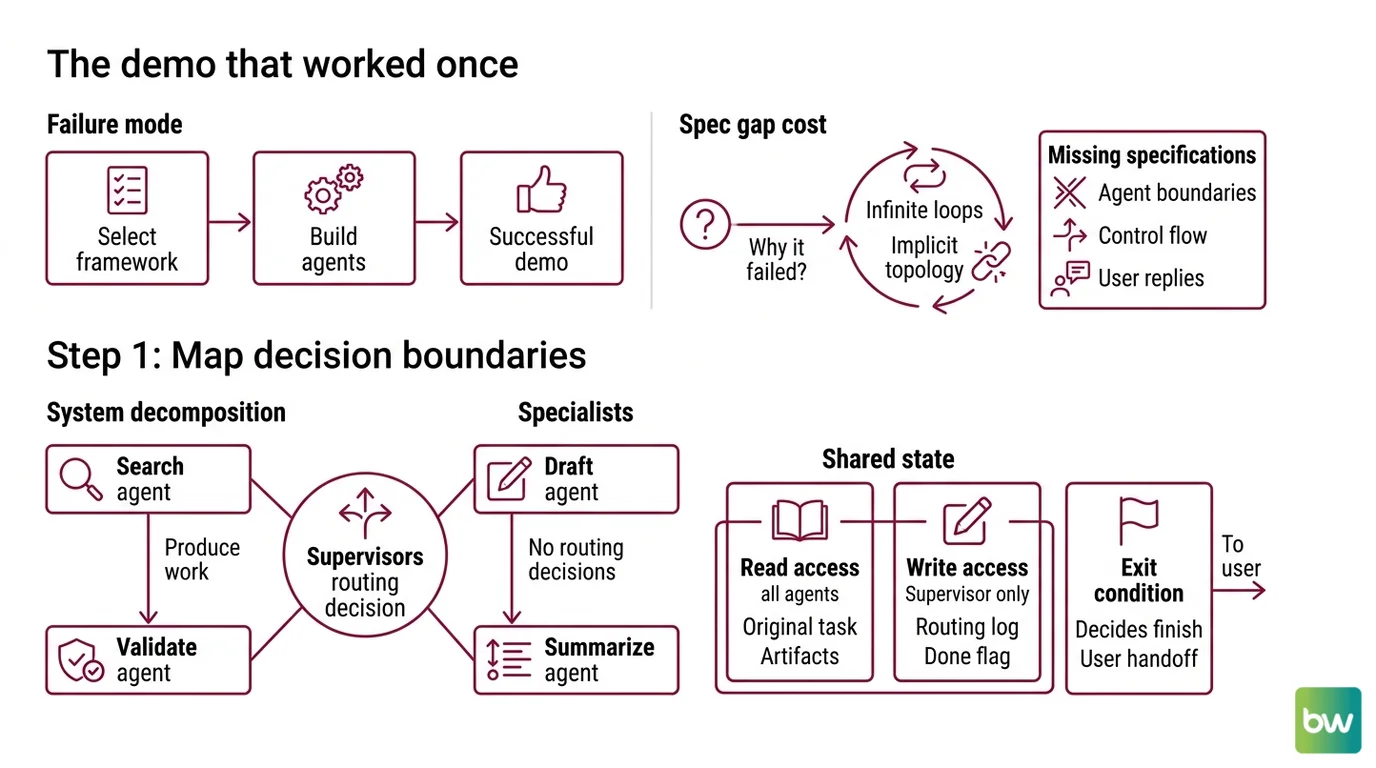
Here is the failure mode I see every week. A team picks a framework on Monday because they liked a tutorial. By Wednesday they have three agents calling each other through a planner. By Friday the demo works. By the next sprint, nobody can explain why agent B sometimes returns control to the planner and sometimes calls agent C directly.
The framework didn’t break. The team never wrote down the topology. They specified roles (“research agent”, “writer agent”) but not boundaries (which agent decides when the task is done, which agent owns the user-facing reply, which agent is allowed to call which other agent). The framework filled in the missing decisions with its defaults — and those defaults are different in Agent Orchestration libraries that look superficially similar.
It worked Friday. On Monday, the writer agent started looping back to the researcher because a prompt change shifted the planner’s preference, and the topology was implicit, not specified. That’s the spec gap that costs you a sprint.
Step 1: Map the Decision Boundaries
Before you compare frameworks, decompose the problem into agents and decisions. Frameworks compete on primitives — graphs, crews, handoffs — but those primitives only help if you already know which decisions belong to which agent.
Your system has these parts:
- The supervisor — owns the routing decision. Reads the user request and current state, picks which specialist runs next. Never produces user-facing output directly.
- The specialists — each owns exactly one capability (search, draft, validate, summarize). They produce work, not routing decisions. They never call each other unless your topology explicitly allows it.
- The shared state — what every agent can read (the original task, intermediate artifacts) versus what only the supervisor writes (the routing log, the “is this done” flag).
- The exit condition — who decides the run is finished, and what they hand back to the caller.
This is the supervisor-worker shape, the most common production topology. The Supervisor Agent Pattern dominates production multi-agent systems precisely because it isolates the routing brain from the doing brains, and that separation is what makes the system debuggable.
There is a second shape — Swarm Architecture — where agents hand off directly to each other without a central planner. The LangChain team recommends swarm for exploratory and research-mode systems, with graph or hierarchy patterns as the production default (LangGraph Swarm GitHub). Pick swarm only when you cannot define a supervisor’s job description in one sentence.
The Architect’s Rule: If you cannot draw the supervisor → specialist → handoff diagram on a whiteboard in five minutes, the framework will absorb the ambiguity and convert it into runtime confusion.
Step 2: Specify the Topology and the Handoffs
Now you turn the diagram into a contract the AI tool can implement. This is where the framework choice starts to matter — because each framework expresses topology in different primitives.
Context checklist:
- Topology shape declared — supervisor, hierarchy (supervisor of supervisors), or swarm
- Per-agent input contract — what the agent receives (JSON schema or typed model)
- Per-agent output contract — what the agent returns, including the structured signal that means “I’m done with my piece”
- Per-handoff condition — under what state value the supervisor routes to which specialist
- Per-handoff timeout — how long before a stuck specialist gets cancelled
- Forbidden routes — which agents are not allowed to call which other agents
- Shared memory model — read-only fields, write-only fields, append-only logs
Now match the topology to the framework primitives.
LangGraph models the system as an explicit state machine over a graph — nodes are agents, edges are conditional routes, and state is checkpointed (LangGraph Docs). LangGraph 1.1.10 shipped on April 27, 2026 (LangGraph PyPI). The supervisor pattern is now built directly via tools rather than the dedicated langgraph-supervisor library, which still works but is no longer the recommended default (LangChain Multi-Agent Docs).
CrewAI models the system as a crew: agents with role descriptions and a task list, plus flows for event-driven structured workflows with explicit state (CrewAI Docs). CrewAI 1.14.4 shipped three days later, on April 30, 2026 (CrewAI GitHub). It is independent of LangChain and supports both MCP and A2A protocols.
The OpenAI Agents SDK models the system as a chain of handoffs. Calling transfer_to_<agent> is itself a tool call — the runtime immediately switches execution and transfers conversation state (OpenAI Agents SDK Docs). Version 0.15.3 shipped on May 6, 2026 (openai-agents PyPI). The SDK is provider-agnostic and runs against 100-plus model providers, not just OpenAI.
The Microsoft Agent Framework reached 1.0 General Availability on April 3, 2026 for both .NET and Python (Microsoft Foundry Blog). It supports sequential handoffs, group chat, and the Magentic-One task-oriented planner, with native MCP and A2A. It supersedes the legacy AutoGen experimental package and Semantic Kernel — greenfield code should target Agent Framework, not those older tracks.
The Spec Test: If your topology is a graph with conditional edges and you pick a handoff-first framework, you will simulate edges in prose and your routing logic will leak into agent prompts. Match the topology to the primitive.
Step 3: Build the Supervisor Before the Specialists
In single-agent work, you build the brain first. In multi-agent work, you build the router first and stub the brains. This inverts most developers’ instincts and is the single biggest reason teams ship working systems faster.
Build order:
- Supervisor with stubbed specialists — the supervisor is real, the specialists return canned responses. Verify the routing graph: does the right specialist get called for the right input? Does the exit condition fire?
- One specialist at a time — replace one stub with a real agent. Validate that the contract holds (it returns the shape the supervisor expects). Move to the next.
- Shared state and Agent Memory Systems — add memory after the routing graph is stable. Memory amplifies routing bugs; if your routing is wrong, memory makes the bug harder to reproduce.
- Cross-cutting concerns last — guardrails, tracing, human-in-the-loop, retry policies. These belong in the framework’s primitives (LangSmith for LangGraph, built-in tracing for OpenAI Agents SDK) rather than in agent prompts.
For each agent, your context must specify:
- What it receives (typed input)
- What it returns (typed output, including a
donesignal) - What it must NOT do (forbidden tool calls, forbidden routes)
- How to handle failure (retry once, then route to supervisor with error context)
This order works because routing bugs masquerade as model bugs. If you build the specialists first and they look smart, you will blame them when the system misbehaves — and the actual bug will be in the supervisor’s conditional edge that you never tested in isolation.
Step 4: Validate the Routes, Not the Outputs
Most agent test suites assert on final answers. They miss the entire class of failures specific to multi-agent systems: wrong-route bugs, infinite-loop bugs, and silent-handoff-state-loss bugs. Validate the topology directly.
Validation checklist:
- Route assertions per scenario — failure looks like: the right answer was produced, but by the wrong specialist (lucky output, broken topology). Caught only by asserting the routing trace.
- Loop bound — failure looks like: the system answers correctly but takes 14 turns when 3 was the budget. Set a hard turn limit and assert it.
- Handoff state integrity — failure looks like: an agent receives partial context after a handoff and quietly invents the missing fields. The OpenAI Agents SDK’s opt-in
RunConfig.nest_handoff_historycollapses prior transcripts into a<CONVERSATION HISTORY>block (OpenAI Agents SDK Docs); if you use it, assert that the receiving agent actually reads it. - Failure-route coverage — failure looks like: a specialist crash takes down the whole run. Inject a simulated failure and assert that the supervisor’s fallback fires.
- Cost ceiling per run — failure looks like: the system passes correctness tests but burns far more tokens than budgeted. Assert max-tokens-per-run as a regression test.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Started with framework choice | Framework primitives shaped the topology you should have chosen yourself | Map decision boundaries first, then pick the framework whose primitives match |
| Single supervisor for many specialists | Routing decisions hit a token-budget ceiling and the supervisor confused itself | Add a second tier of sub-supervisors or split into separate crews |
| No timeout on handoffs | One stuck specialist froze the entire chain silently | Specify a per-handoff timeout and a fallback route in the topology |
| Treated multi-agent debate as a setting | Agent Debate is a pattern, not a framework toggle — single-agent calls happened anyway | Implement debate as an explicit loop on top of the framework, with N agents and K critique rounds |
Pro Tip
The framework is downstream of the topology, and the topology is downstream of the decision boundaries. Sketch the topology first, then choose the framework whose primitives match it most cleanly. Every spec you write at the topology layer makes every framework choice downstream cheaper and more reversible. When the framework changes again next year — and it will — your topology diagram migrates. Your code does not.
Frequently Asked Questions
Q: How to build a multi-agent system step by step in 2026? A: Map decision boundaries first — which agent owns which call. Lock the topology (supervisor, swarm, or hierarchy). Pick the framework whose primitives match. Build the supervisor with stubbed specialists, swap one stub at a time, then add memory and guardrails last. The hardest step is the first: most teams skip decomposition and pay for it in week three.
Q: How to use LangGraph for supervisor-worker agent orchestration?
A: Define the supervisor as a graph node that returns the next worker’s name as a structured tool call, then route via conditional edges. As of LangGraph 1.1.10, the LangChain team recommends building the supervisor directly via tools rather than the langgraph-supervisor library — both still work, but the tools-first approach gives you fewer abstractions to debug at 2 AM.
Q: When should you use CrewAI vs OpenAI Agents SDK vs Microsoft Agent Framework for multi-agent workflows? A: CrewAI fits role-based crew prototypes where agents collaborate by job description. OpenAI Agents SDK fits handoff-heavy flows where state transfers between agents like phone-tree calls. Microsoft Agent Framework fits enterprise .NET stacks with native A2A and MCP — pick by deployment target and team stack, not by feature checklist.
Your Spec Artifact
By the end of this guide, you should have:
- A topology diagram naming each agent, its decision scope, and its handoff partners
- A constraint list per agent: input contract, output contract, error fallback, per-handoff timeout
- A route validation table that asserts which agent must handle which test scenario, plus loop bounds and cost ceilings
Your Implementation Prompt
Use this prompt in your AI coding tool (Claude Code, Cursor, or Codex) once you have your topology diagram from Step 1. Replace each bracketed placeholder with values from your decomposition. Do not delete sections — empty sections are themselves a signal that you skipped a step.
You are pair-programming a multi-agent system in [framework: LangGraph | CrewAI | OpenAI Agents SDK | Microsoft Agent Framework].
TOPOLOGY (from Step 1):
- Supervisor: [name and one-sentence decision scope]
- Specialist agents: [list each with one-line responsibility]
- Handoff edges: [list each as: from-agent → to-agent, condition]
- Shared state: [what every agent reads; what only the supervisor writes]
- Exit condition: [the state value that signals the run is done]
CONSTRAINTS (from Step 2):
- Tech stack and version: [language + framework version]
- Per-agent input contract: [JSON schema or typed model]
- Per-agent output contract: [same, plus the `done` field shape]
- Error fallback per agent: retry once, then route to supervisor with error context
- Per-handoff timeout: [seconds]
- Forbidden routes: [e.g., specialists never call each other; only supervisor writes to external systems]
- Memory model: [none | conversation-only | shared scratchpad | persistent store]
BUILD ORDER (from Step 3):
1. Implement the supervisor and stub each specialist with canned responses keyed to test inputs.
2. Swap one stub at a time for a real agent; validate routing before output quality.
3. Add shared state and memory only after the routing graph passes its tests.
4. Add guardrails, tracing, and human-in-the-loop last.
VALIDATION (from Step 4):
For each scenario in [list test scenarios], assert:
- The supervisor routed to the expected specialist (route assertion, not output assertion)
- The specialist's output matches its contract
- A simulated specialist failure triggers the documented fallback route
- Total turn count stays under [N]
- Total token cost per run stays under [M]
Generate the framework-specific code for the supervisor and the routing logic only. Stub the specialists. Do not add multi-agent debate, persistent memory, or human-in-the-loop yet — those come after route validation passes.
Ship It
You now know that the topology — supervisor, swarm, or hierarchy — is the spec, and the framework is the runtime that executes it. Decompose first. Lock the contracts. Build the routing before the brains. Validate routes, not just outputs. Every multi-agent project you spec this way gets shorter to debug and easier to migrate when frameworks shift again.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors