How to Build and Fine-Tune State Space Models with Mamba-3, Jamba, and Nemotron-H in 2026
TL;DR
- Pure SSMs and hybrid SSM-Transformers have different hardware and fine-tuning contracts — pick the class before you pick the model
- Mamba-2 and Mamba-3 LoRA is experimental; target modules and gradient checkpointing behavior are not stable across implementations
- vLLM V1 does not yet support SSMs for prefix caching or KV-cache offload — your serving spec must not assume drop-in transformer parity
You picked Jamba 1.5 Large for the 256K context window. Eight H100s, plain 4-bit QLoRA, training kicks off. Loss curve looks clean. Ten hours in, evals come back scrambled. The Mixture Of Experts routing layer quietly corrupted two thousand steps back. The fine-tune didn’t fail. Your specification did.
Before You Start
You’ll need:
- A Linux box with an NVIDIA GPU — Mamba Architecture kernels do not run on Windows or macOS, and the official CUDA path is non-negotiable
- Working knowledge of State Space Model mechanics, specifically how Selective Scan differs from attention and why recurrence changes the fine-tuning surface
- A clear picture of your workload: pure long-context sequence modeling, hybrid reasoning at scale, or an edge-deployable distilled variant
This guide teaches you: how to decompose an SSM project into architecture-family selection, runtime contract, fine-tuning strategy, and long-context validation — so the AI coding tool generates configs that survive production, not just dev.
The 256K Context Window That Silently Broke
Most SSM deployment failures look the same. Someone reads “Jamba 1.5 Large — 256K context, up to 2.5× faster on long inputs” (AI21 Blog) and provisions it like a transformer. The config pulls vLLM with prefix caching on. Inference works in single-query tests. At concurrent load, prefix caching corrupts — because Jamba is not fully supported in vLLM V1, and SSM state updates are incompatible with the V1 cache path (vLLM GitHub Issue).
A team tried to fine-tune that same model last month. They reached for QLoRA because it worked for their dense Llama runs. Training loss looked normal for hours. The MoE routing layer was silently degrading the whole time. Your runtime assumptions from transformer-land will betray you here.
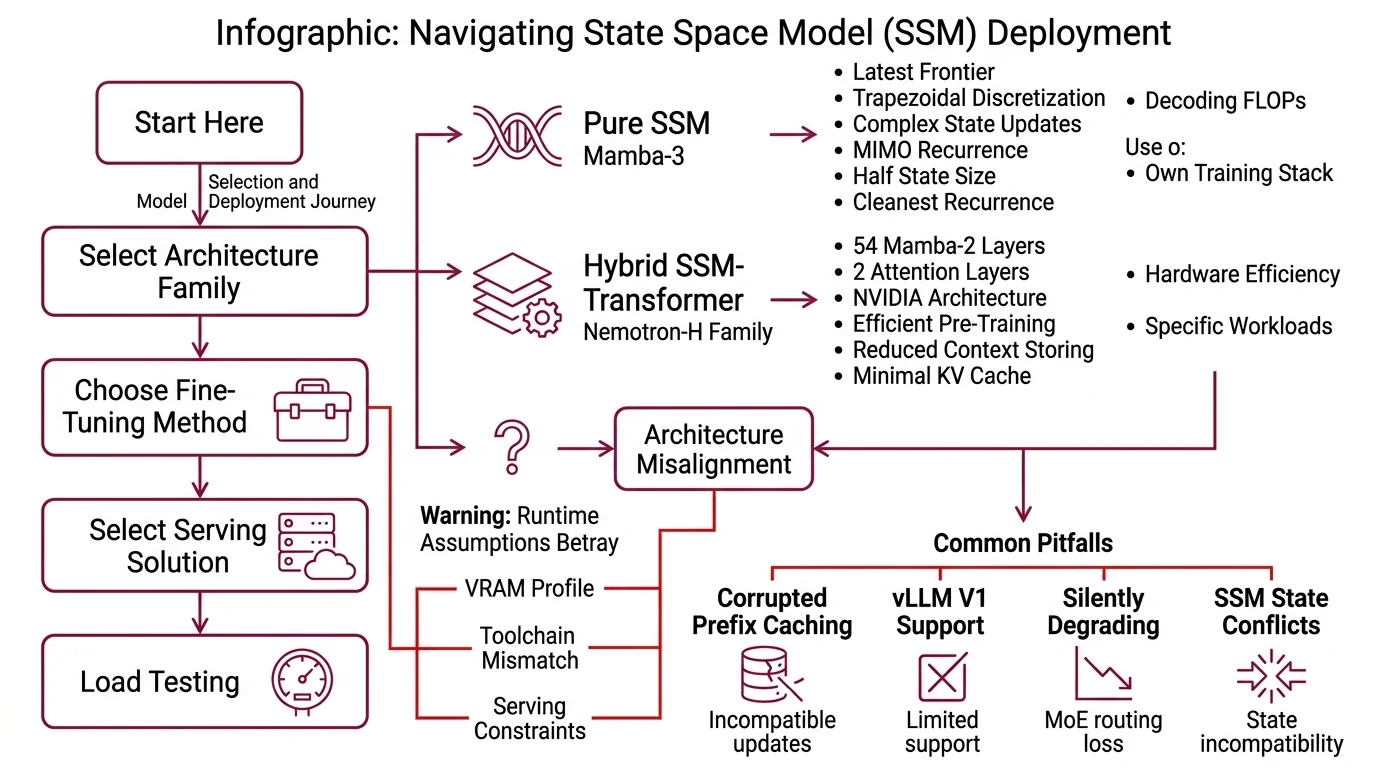
Step 1: Match the Architecture Family to Your Workload
Before you pick a model, pick a class. SSMs split into two camps, and the Hybrid Architecture camp splits further by how it interleaves recurrence and attention. Mix these up and you inherit the wrong VRAM profile, the wrong fine-tuning toolchain, and the wrong serving constraints.
The three families you’re choosing between:
- Pure SSM — Mamba-3 (ICLR 2026, released March 16, 2026, per OpenReview). Latest frontier on the pure-SSM line. Three innovations over Mamba-2: trapezoidal discretization, complex-valued state updates via a RoPE trick on the B/C projections, and MIMO recurrence replacing SISO (OpenReview). At 1.5B scale, Mamba-3 adds 0.6 points over a Gated DeltaNet base and 1.8 points with MIMO, and matches Mamba-2 perplexity at half the state size. The MIMO variant costs up to 4× the decoding FLOPs of Mamba-2 at fixed state size (OpenReview) — accuracy/latency trade-off, not a free win. Use when you need the cleanest recurrence, minimal attention, and you own the training stack.
- Hybrid SSM-Transformer — Nemotron-H family (NVIDIA ADLR). Nemotron-H-56B stacks 54 Mamba-2 layers, 54 MLP layers, and only 10 self-attention layers; pre-trained on 20T tokens in FP8. NVIDIA reports up to 3× faster inference versus Qwen-2.5 and Llama-3.1 at similar scale (NVIDIA ADLR). Nemotron-H-8B Reasoning (released June 6, 2025, per NVIDIA Hugging Face) ships with 128K context and a hybrid Mamba-2 + MLP + 4 attention-layer stack — the practical pick for reasoning workloads that don’t need the 56B budget.
- Hybrid-MoE — Jamba 1.5 Large (AI21 Blog). 94B active parameters out of 398B total, with an 8-layers-per-block structure, a 1:7 attention-to-Mamba ratio, and MoE on top. Fits on a single H100 80GB node with ExpertsInt8 quantization and supports 256K context — at the time of writing, the only open model backed on RULER at that length (AI21 Blog). Note: Jamba 1.5 is the August 2024 generation. AI21 has since shipped Jamba 1.6, Jamba 1.7, and Jamba 2 Mini (AI21 Blog); use 1.5 Large when you need the proven 256K long-context track record and the Jamba Open Model License.
- Hybrid-parallel — Falcon H1 (Falcon LLM, May 20, 2025). Six sizes from 0.5B to 34B, 262K context, and a parallel-hybrid design where attention and SSM run side-by-side within each block and concatenate before the output projection (Falcon LLM Blog). Choose this when you need a scaling ladder and a small-model option on the same architecture family.
The Architect’s Rule: If you can’t name the attention-to-recurrence ratio and the active parameter count of your chosen model, you’re not ready to write the runtime spec.
Step 2: Lock Down the Installation and Runtime Contract
You’ve picked the family. Now nail the runtime specification before the AI coding tool starts generating configs — because the defaults will not match SSM reality.
Context checklist:
- Platform: Linux + NVIDIA GPU +
PyTorch 1.12 or newer. The
mamba-ssmpackage requires CUDA 11.6+, and CUDA 12.x support only arrived in mamba-ssm 1.2.0 (mamba-ssm PyPI). If your base image pins an older version, CUDA 12 toolchains will fail at kernel compile time. - Install path for Mamba-3: the bootstrap command is
MAMBA_FORCE_BUILD=TRUE pip install --no-cache-dir --force-reinstall git+https://github.com/state-spaces/mamba.git --no-build-isolation(Mamba GitHub). Ordinarypip install mamba-ssm[causal-conv1d]gets you the Mamba-2 release line; force-build is what you need when the source tree moves ahead of PyPI. - Serving framework: vLLM supports Jamba, Mamba, Codestral Mamba, Falcon Mamba, Bamba, Zamba2, and Nemotron-H (vLLM Blog). Nemotron-H also runs on HuggingFace Transformers in BF16, TensorRT-LLM in FP8, and NeMo (NVIDIA Developer Blog). Pick the framework that already has native kernels for your model — cross-framework ports lose speed.
- Long-context budget: specify the working context length, not the model maximum. Jamba 1.5 Large advertises 256K, but throughput, concurrency limits, and memory pressure scale with what you actually use.
- Quantization target: for Jamba 1.5 Large, ExpertsInt8 is the recommended MoE quantization that fits the full 256K window on a single 8-GPU node at the lowest latency (AI21 Blog). Do not substitute generic INT8 on the MoE layers.
The Spec Test: If your config enables vLLM V1 prefix caching, KV-cache offload, or prefill-decode disaggregation on an SSM or hybrid model, you will hit incorrect outputs under load — SSM models are not yet native in vLLM V1 (vLLM GitHub Issue).
Step 3: Wire the Fine-Tuning Pipeline for Recurrence, Not Attention
Fine-tuning an SSM is not fine-tuning a transformer with different layers. The recurrence path changes which modules carry the learning signal, which tensors are safe to freeze, and which adapter strategies will silently corrupt the model.
Three strategies that map to the three model families:
- Mamba-2 / Mamba-3 LoRA — experimental. HuggingFace Transformers documents
x_proj,embeddings,in_proj, andout_projas the PEFT target modules for Mamba-2 (HuggingFace Transformers). Treat this as a starting point, not a stable contract. First-class fine-tuning is still being tracked as an open issue in Transformers, gradient checkpointing can break SSM state updates, and CUDA-kernel weight-passing can silently skip your LoRA adapters (HuggingFace Transformers Issue). Run a small-sample validation before any long training run — assume the target module list is not portable across implementations. - Jamba 1.5 Large — qLoRA+FSDP, not plain QLoRA. AI21 explicitly recommends qLoRA combined with FSDP on 8× A100 or H100 80GB for the full model (AI21 Blog). Plain 4-bit QLoRA on the MoE expert layers hits the same BitsAndBytes limitation that breaks other MoE models — the quantization interferes with expert routing. Use qLoRA+FSDP, or drop to bf16 LoRA if your memory budget allows.
- Nemotron-H — NeMo pipeline. NVIDIA ships the 8B, 47B, and 56B variants through NeMo, with HuggingFace Transformers BF16 and TensorRT-LLM FP8 for inference (NVIDIA Developer Blog). The 47B model is a MiniPuzzle distillation of the 56B — about 20% faster with similar accuracy — which is often the better fine-tuning base than the 56B parent (NVIDIA ADLR).
Build order:
- Validate the base model end-to-end first. Run a forward pass at your target context length. Confirm generation quality on a held-out prompt set. If the base model is broken in your runtime, every training metric is contaminated.
- Wire the adapter on a micro-dataset. Train for a few hundred steps on a small shard. Inspect adapter tensors to verify the LoRA layers actually hold weights — on Mamba-2, gradient checkpointing can produce adapters that load but never update.
- Scale to the full fine-tune only after the smoke test. The cost of one ruined multi-day run is higher than the cost of the micro-dataset loop.
Step 4: Validate Long-Context Throughput, Not Just Accuracy
Long-context SSMs promise speed and reach that transformers cannot match. But the validation most teams run — accuracy on a short benchmark — tells you nothing about whether the model holds up at the context length and concurrency you’re deploying at.
Validation checklist:
- Real long-context accuracy — run RULER or a needle-in-haystack suite at your target context. Jamba 1.5 Large is the reference point AI21 reports as the only open model backed on RULER at 256K (AI21 Blog). Compare against your workload distribution, not the headline benchmark.
- Throughput under concurrency — measure p50, p95, and p99 latency at your expected concurrent request rate, not single-query. Hybrid models trade memory savings on the Mamba path for attention cost on the transformer path; the crossover point depends on your batch shape. Failure looks like: clean single-query latency, collapsing tail latency under load.
- Serving-stack sanity — confirm your vLLM or TensorRT-LLM config does not rely on features SSMs don’t yet support. Prefix caching, KV-cache offload, and prefill-decode disaggregation are on the known-incompatible list for SSMs in vLLM V1 (vLLM GitHub Issue). Failure looks like: outputs drift under repeated prefixes that a transformer would cache cleanly.
- Fine-tune regression on general knowledge — compare fine-tuned model against the base on a held-out general-domain set. Mamba-2 LoRA, in particular, can degrade representations outside your target task when target modules shift during gradient checkpointing. Failure looks like: better on your task, worse on the evaluation harness you forgot to re-run.
Security & compatibility notes:
- Jamba 1.5 Large successors: 1.5 Large knowledge cutoff is March 2024 (AI21 Hugging Face). AI21 has since released Jamba 1.6, Jamba 1.7, and Jamba 2 Mini. Pin 1.5 Large deliberately, or migrate to a newer generation.
- mamba-ssm CUDA 12.x: CUDA 12 support requires mamba-ssm 1.2.0 or newer (mamba-ssm PyPI). Older pins fail on CUDA 12 toolchains.
- vLLM V1 SSM support: Jamba, Mamba, and other SSMs are not yet native in vLLM V1 — incompatible with prefix caching, KV offload, and prefill-decode disaggregation (vLLM GitHub Issue). Stay on a V0-compatible path for now.
- Mamba-2 / Mamba-3 PEFT: LoRA target modules are not standardized; gradient checkpointing can break adapter updates (HuggingFace Transformers Issue). Treat as experimental.
- Falcon-H1 licensing: License terms vary across the six model sizes (Falcon LLM). Verify the per-model license before commercial deployment.
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
| Treated Jamba like a dense transformer for fine-tuning | Plain 4-bit QLoRA corrupted MoE routing | Use qLoRA+FSDP on 8× A100/H100 80GB per AI21 guidance |
| Enabled vLLM V1 prefix caching on Mamba-based model | SSM state path is incompatible with V1 cache | Disable V1 optimizations; use V0-compatible serving path |
| Installed mamba-ssm on CUDA 12 without version check | Pre-1.2.0 release fails to build on CUDA 12 toolchain | Pin mamba-ssm 1.2.0+ for any CUDA 12 environment |
| Applied Mamba-2 LoRA with gradient checkpointing on | Adapter weights loaded but never updated | Run micro-dataset smoke test; validate adapter deltas before scaling |
| Chose Mamba-3 MIMO expecting a free accuracy win | Up to 4× decoding FLOPs at fixed state size | Measure decode latency budget; accept the trade-off deliberately |
Pro Tip
Every SSM model has a different recurrence-to-attention ratio. The spec you build for Mamba-3 won’t port to Jamba 1.5 Large, and neither will transfer to Nemotron-H without reworking the fine-tuning target list. What does transfer is the decomposition: family first, runtime contract second, fine-tuning strategy third, long-context validation fourth. Keep that order. Every new SSM release fits the same framework.
Frequently Asked Questions
Q: How to implement a Mamba-3 model from scratch in PyTorch in 2026?
A: Start from the official state-spaces/mamba repository — do not reimplement the Selective Scan kernel from the paper, it relies on CUDA optimizations that shape the reported FLOPs. Install mamba-ssm 1.2.0+ on CUDA 11.6+, confirm PyTorch 1.12 or newer, then wire the Mamba-3 block with MIMO recurrence enabled if accuracy outweighs the decode-FLOPs cost. The released checkpoints are the recommended starting point for downstream work.
Q: How to fine-tune Jamba 1.5 Large for 256K Long Context Modeling tasks? A: Provision 8× A100 or H100 80GB, then use qLoRA with FSDP — AI21’s documented path for full-model fine-tuning. Do not substitute plain 4-bit QLoRA; BitsAndBytes on MoE expert layers silently corrupts routing. Validate on RULER or your own long-context eval before scaling. For serving, ExpertsInt8 quantization fits the full 256K window on a single 8-GPU node.
Q: When should I use a State Space Model instead of a transformer? A: When your workload is dominated by long sequences where attention cost is the bottleneck, or when inference throughput at long context matters more than raw peak quality. Hybrid models are usually the safer production bet — pure Mamba-3 is the bleeding edge. If your context is under 8K and your latency budget is generous, a transformer remains the lower-risk choice.
Your Spec Artifact
By the end of this guide, you should have:
- Architecture-family decision record — which class (pure SSM, hybrid, hybrid-MoE, hybrid-parallel), which model, why
- Runtime contract — platform, CUDA version, serving framework, quantization target, working context length, vLLM feature exclusions
- Fine-tuning spec — adapter strategy, target modules, validation loop, smoke-test protocol before full-run commitment
Your Implementation Prompt
Paste this prompt into Claude Code, Cursor, or your preferred AI coding tool. Fill the bracketed placeholders with values from your architecture decision and runtime contract.
You are configuring a State Space Model or hybrid SSM-Transformer for
inference and fine-tuning. Follow this specification exactly.
ARCHITECTURE FAMILY:
- Class: [pure SSM / hybrid SSM-Transformer / hybrid-MoE / hybrid-parallel]
- Model: [exact name and version, e.g., Jamba 1.5 Large]
- Total parameters: [total, e.g., 398B]
- Active parameters per token: [active, e.g., 94B]
- Attention-to-recurrence ratio: [e.g., 1:7 for Jamba 1.5 Large]
- Context window target: [working length, NOT model maximum]
RUNTIME CONTRACT:
- OS: Linux (required for mamba-ssm kernels)
- GPU: NVIDIA, [type and count, e.g., 8x H100 80GB]
- CUDA: [version — if CUDA 12.x, require mamba-ssm 1.2.0+]
- PyTorch: 1.12 or newer
- Serving framework: [vLLM / TensorRT-LLM / HuggingFace Transformers / NeMo]
- Quantization: [e.g., ExpertsInt8 for Jamba; BF16 / FP8 for Nemotron-H]
- vLLM feature exclusions: no prefix caching, no KV offload, no P/D
disaggregation (SSMs not yet native in vLLM V1)
FINE-TUNING (if applicable):
- Adapter strategy: [qLoRA+FSDP for Jamba / bf16 LoRA / NeMo pipeline]
- Target modules: [for Mamba-2 baseline: x_proj, embeddings, in_proj, out_proj]
- Precision: [match strategy — no plain 4-bit QLoRA on MoE experts]
- Smoke-test protocol: [N steps on micro-dataset, inspect adapter deltas]
VALIDATION CRITERIA:
- Long-context accuracy: RULER or domain needle-in-haystack at target length
- Throughput: p50, p95, p99 latency at [concurrent request rate]
- Regression check: general-domain eval vs base model on held-out set
- Serving sanity: confirm vLLM config does not enable V1-only features
Ship It
You now have a framework for breaking any SSM project into four decisions: architecture family, runtime contract, fine-tuning strategy, and long-context validation. The model names will change — Mamba-4, Jamba 3, the next Nemotron generation. The decomposition won’t.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors