How to Build an LLM-as-a-Judge Eval with DeepEval, Braintrust, and Atla Selene in 2026
Table of Contents
TL;DR
- An LLM judge is only as good as the rubric you hand it. Vague criteria produce inflated, drifting scores.
- Pick the judge for the job: a frontier model for nuanced calls, a dedicated judge like Atla Selene for cost and volume.
- A judge you have not calibrated against human labels is an opinion, not a metric. Measure agreement before you trust a score.
Your eval suite is green. Every assertion passes. Then a user pastes a support transcript and your chatbot confidently quotes a refund policy that does not exist. Exact-match tests never caught it, because “correct” here is not a string — it is a judgment call. That is the gap an LLM-as-a-Judge fills, and the gap where most teams wire one up wrong.
Before You Start
You’ll need:
- An eval framework: Deepeval (open source, Pytest-style) or a hosted platform like Braintrust
- A judge model — a frontier LLM or a dedicated judge model
- A small set of hand-labeled examples — your Ground Truth — to calibrate against
- A clear idea of what “good output” means for your specific app
This guide teaches you: how to treat an LLM judge as a specified system — rubric, model, scorer, calibration — instead of a vague “rate this 1 to 10” prompt.
The Judge That Rated Everything 8/10
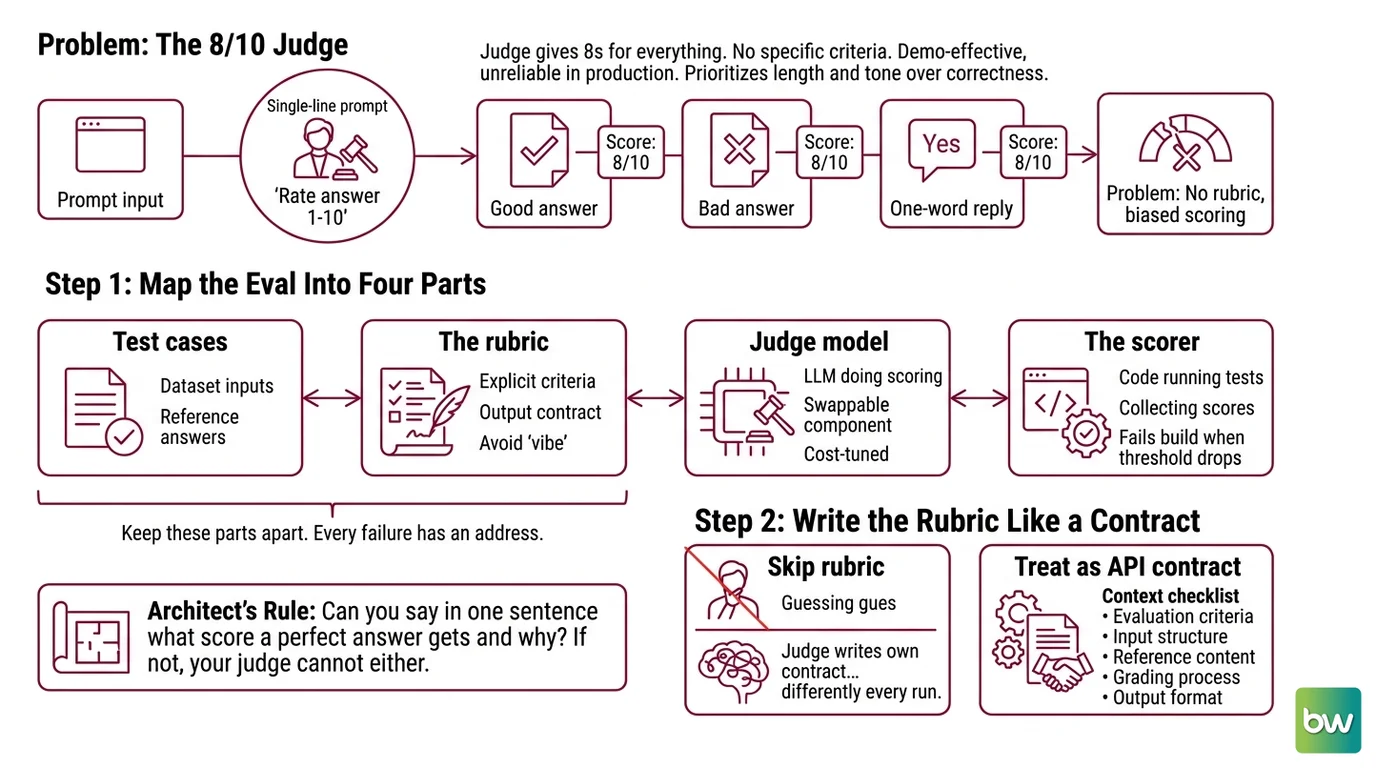
You wire up a judge with one line: “Rate this answer from 1 to 10.” It returns 8s. For good answers, bad answers, and one reply that is just the word “yes.” The judge has no rubric, so it falls back on instinct — and instinct clusters around 8.
A pass/fail benchmark like SWE Bench tells you whether code runs — not whether a support reply is helpful, grounded, and on-brand. So you reach for a model to judge quality, and the judge becomes the new unreliable thing.
It worked in the demo. In production, the same prompt scored a Hallucination-laden answer higher than the correct one — because it was longer and sounded more sure of itself.
Step 1: Map the Eval Into Four Moving Parts
Before you write a single criterion, name the parts. An eval that scores quality is not one prompt — it is four components with clean boundaries. Mix them up and you cannot tell whether a bad score came from a bad answer, a bad rubric, or a bad judge.
Your system has these parts:
- Test cases — the inputs being judged, with a reference answer where one exists. This is your dataset, and it is a separate concern from how you score it.
- The rubric — the explicit criteria the judge scores against. This is your output contract for the judge, not an afterthought.
- The judge model — the LLM doing the scoring. Swappable, and the part you tune for cost.
- The scorer — the code that runs each case through the judge, collects scores, and fails the build when a threshold drops.
The Architect’s Rule: If you cannot say in one sentence what score a perfect answer gets and why, your judge cannot either.
Keep these four apart and every failure has an address.
Step 2: Write the Rubric Like a Contract
The rubric is the contract between you and the judge. Skip it and the judge writes its own — differently every run. Treat it like an API contract, not a vibe.
Context checklist:
- Evaluation criteria named explicitly — for a RAG reply that means Faithfulness to the retrieved context and Answer Relevancy to the question, not “is it good”
- A defined scale with anchors — state what a top score means and what a failing score means, not just the range “1 to 10”
- Rules for partial credit, and what to do when no reference answer exists
- Chain-of-Thought required — make the judge explain its reasoning before it commits to a number
- Bias guards — randomize answer position, and do not let length stand in for quality
This is where G-Eval earns its place. DeepEval’s G-Eval metric runs an LLM judge on your custom criteria using chain-of-thought plus token-probability weighting, in about five lines of code (DeepEval Docs). The reasoning step is not decoration — making the judge reason before it scores is what separates a defensible number from a coin flip.
The Spec Test: If your rubric does not say what to do with a partially correct answer, the judge will improvise — and improvise a different way on every run.
Step 3: Sequence the Build — Framework, Then Model, Then Tracking
Order matters. Get one trustworthy score before you optimize anything.
Build order:
- The framework and one metric first — wire DeepEval with a single G-Eval metric on one criterion. One score you trust beats ten you do not.
- The judge model next — because the metric has to work before cost is worth tuning. DeepEval defaults to OpenAI’s GPT when none is set, and swaps to Anthropic, Gemini, Ollama, Azure, or a custom model with a config change (DeepEval Docs). As of mid-2026, GPT-5 and Claude Sonnet 4.5 are the go-to general judges — verify the current model strings at build time, since these names move fast.
- Tracking and CI last — pipe scores into Braintrust so regressions show up across runs, not just in one terminal.
For each component, your context must specify:
- What it receives (inputs)
- What it returns (a score and its reasoning)
- What it must NOT do (no scoring without a rubric, no silent fallback model)
- How to handle failure (a malformed judge response is a test error, not a passing score)
A frontier model judges well but bills per token on every case. For high-volume CI runs, a dedicated judge changes the math. Atla Selene Mini is an 8B model fine-tuned from Llama 3.1 8B Instruct, with open weights on HuggingFace and Ollama (Atla’s Selene Mini paper). It is the highest-scoring 8B model on Rewardbench, tops Judge Arena, and beats GPT-4o-mini across eleven out-of-distribution benchmarks. Its API runs about $3 per 1,000 calls — roughly 2x faster and 3x cheaper than the flagship Selene 1 (Atla AI). Selene Mini shipped in early 2025 and remains Atla’s current open judge as of mid-2026. The flagship, based on Llama-3.3-70B, outperforms frontier models across eleven benchmarks; its per-call price is not publicly itemized, so budget for it as a frontier-tier cost.
If you develop locally, Atla exposes Selene judges through the Model Context Protocol, so you can call the judge from your editor without standing up a service.
Setup & compatibility notes (Braintrust, as of 2026):
- API keys moved to the UI: You can no longer mint Braintrust API keys or service tokens through the public API — the
POST /v1/api_keyand service-token endpoints were removed. Create keys in the dashboard, then reference them from your pipeline (Braintrust’s changelog).- Anthropic cache metrics renamed: If you track prompt-cache token fields, the names changed (for example
cache_creation_ephemeral_5m_input_tokensbecameprompt_cache_creation_5m_tokens). Update any dashboard that parses them.- Pricing is indicative: Braintrust’s Starter tier is $0/month ($10 credits, 1 GB data, 10k scores, 14-day retention); Pro is $249/month (5 GB data, 50k scores, 30-day retention, basic RBAC); Enterprise is custom. Check the current pricing page before you write a cost constraint into a spec.
Step 4: Calibrate the Judge Against Humans
A judge that has never been compared to a human is a confident stranger. Calibration turns its scores into a metric you can put on a dashboard.
Validation checklist:
- Agreement with human labels measured — failure looks like: judge scores diverge from your labeled set with no pattern you can explain
- Position and verbosity bias checked — failure looks like: the longer answer or the first option wins regardless of quality
- Score stability across runs — failure looks like: the same input gets a 6, then an 8, with no rubric change
- Resistance to gaming — failure looks like: answers tuned to flatter the criteria score high while being wrong
Score a few dozen examples by hand first. Run the judge over the same set and measure how often the two agree. Cohen’s kappa is the standard here because it corrects for agreement that happens by chance — raw percent-agreement flatters a judge that rates everything 8. When the judge and your humans disagree too often, the fix is almost always the rubric, not the model.
Two failure modes to watch. Reward Hacking is when outputs get tuned to the judge’s stated criteria instead of to being correct — the score climbs while quality does not. And if your human labelers disagree with each other, fix that before you blame the judge: low inter-annotator agreement means the task itself is underspecified, and no judge can be more consistent than the people it learned from. It is the same discipline behind RAG Evaluation — grounded scores, checked against humans before anyone trusts them.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| “Rate this 1 to 10” with no rubric | Judge falls back on instinct; scores cluster high and drift run to run | Define each score level with explicit anchors |
| Scored without chain-of-thought | Judge picks a number first and rationalizes never | Require reasoning before the score (G-Eval does this by default) |
| Never compared to human labels | A confident-but-wrong judge looks identical to a good one | Calibrate against a hand-labeled set and measure agreement |
| One frontier judge for every CI run | Token bill scales with test volume; runs get throttled | Route high-volume cases to a dedicated judge like Selene Mini |
Pro Tip
Version your rubric like code. The day you change a criterion or move a score anchor, every historical score becomes incomparable — you have quietly moved the goalposts. Store the rubric next to the eval, tag it, and record which rubric version produced which scores. A judge with an unversioned rubric is a thermometer whose scale shifts when you are not looking.
Frequently Asked Questions
Q: How do you build an LLM-as-a-judge evaluation pipeline step by step with DeepEval? A: Define one G-Eval metric with explicit criteria, point it at your test cases, set a passing threshold, and run it like a Pytest suite. Start with a single criterion. One watch-out: G-Eval needs a clear evaluation_steps list, or it invents its own.
Q: How do you use LLM-as-a-judge to evaluate RAG and chatbot answer quality? A: Score retrieval-grounded answers on faithfulness (does it stick to the retrieved context) and answer relevancy (does it address the question). DeepEval ships both as metrics. Watch out: faithfulness needs the actual retrieved chunks passed in, not just the final answer.
Q: What are the best LLM-as-a-judge tools and frameworks in 2026? A: DeepEval for open-source, code-first evals; Braintrust for hosted tracking and CI dashboards; Atla Selene as a dedicated judge model when cost and volume matter. They compose — Selene can be the judge inside DeepEval. Pick by where your bottleneck is.
Your Spec Artifact
By the end of this guide, you should have:
- A rubric document — named criteria, a defined scale with anchors, and rules for partial credit and missing reference answers
- A judge configuration — which model judges, its fallback, and the cost tier each class of test routes to
- A calibration record — your hand-labeled set and the agreement score your judge has to beat before it ships
Your Implementation Prompt
Paste this into your AI coding tool (Claude Code, Cursor, Codex) when you scaffold the eval. Fill every bracket with your own values — each one maps to a checklist item from Steps 1 through 4.
You are setting up an LLM-as-a-judge evaluation for [your app: e.g., a RAG support chatbot].
1. COMPONENTS — Treat the eval as four parts:
- Test cases: [where they come from; with or without reference answers]
- Rubric: the criteria below
- Judge model: [model], fallback [model]
- Scorer: DeepEval G-Eval, fail the build below [threshold, e.g., 0.7]
2. RUBRIC (the contract) — Score each output on:
- Criteria: [e.g., faithfulness to retrieved context, answer relevancy, tone]
- Scale with anchors: [what a top score means]; [what a failing score means]
- Partial credit: [how to score partially correct answers]
- No reference: [what to do when no ground-truth answer exists]
- Require chain-of-thought reasoning BEFORE the score.
- Bias guards: randomize answer position; do not reward length.
3. BUILD ORDER — Implement one criterion first and confirm its scores are
stable across repeated runs. Then add the remaining criteria. Then route
[high-volume test class] to [dedicated judge, e.g., Atla Selene Mini] for cost.
4. VALIDATE — Before trusting any score, run the judge over my hand-labeled
set of [N] examples and report agreement (Cohen's kappa). If agreement is
below [target], stop and revise the rubric, not the model.
Ship It
You can now measure quality that string matching never catches — and prove the measurement itself is trustworthy. An LLM judge is not a black box you bolt on at the end; it is a specified system: rubric, model, scorer, calibration. Build it in that order and your scores start to mean something.
Deploy safe, Max.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors