How to Build Agentic RAG with LangGraph, LlamaIndex & Haystack in 2026
TL;DR
- Agentic RAG is a pipeline of bounded layers, not a single framework choice — pick tools per layer, not as a monolith.
- The 2026 production pattern is Hybrid Search + cross-encoder rerank + a loop with an explicit iteration budget and confidence gate.
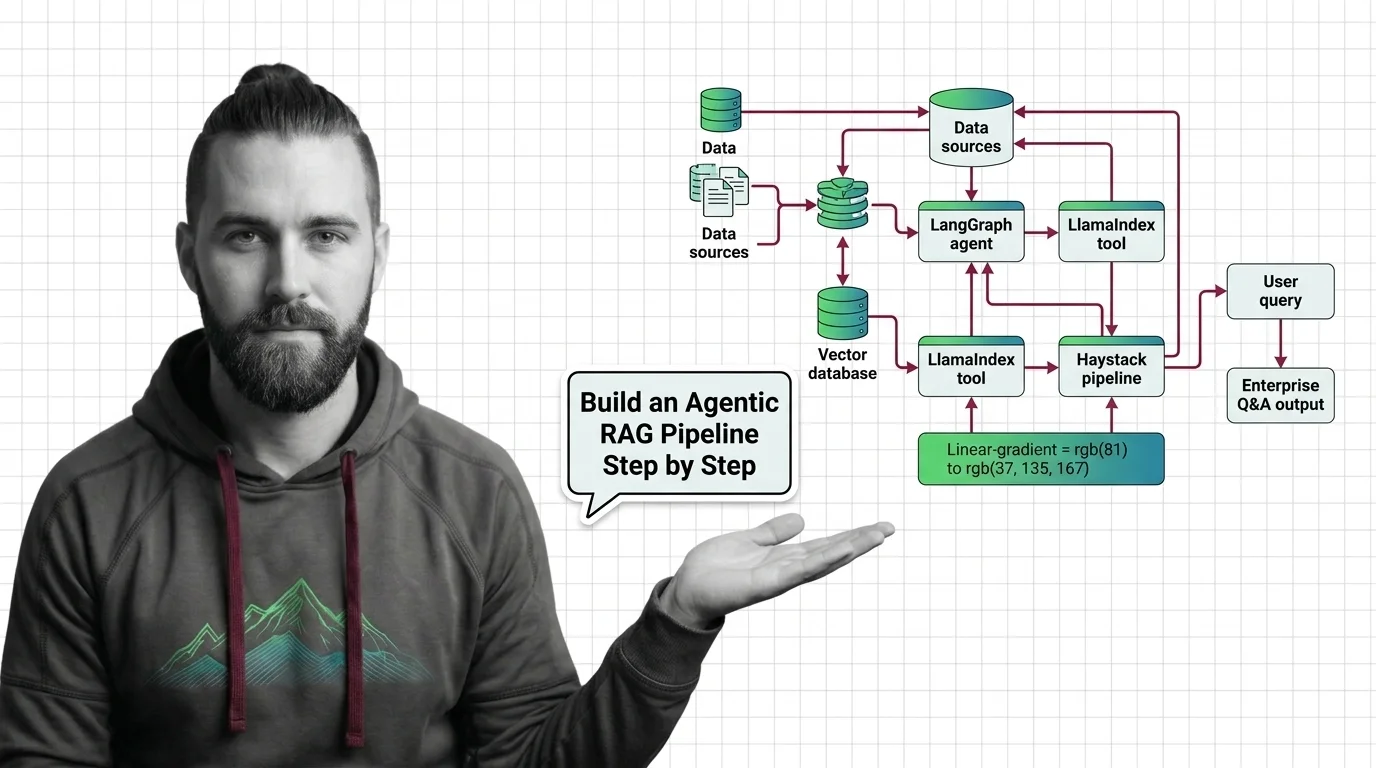
- LangGraph, LlamaIndex, and Haystack are complementary — orchestration, retrieval, pipeline composition. The spec decides who owns what.
A team I reviewed last quarter stood up an agentic RAG demo on a Friday. Looked great. Single-shot answers, citations, the whole pitch. By Wednesday their token spend was up 8x and the eval suite kept regressing on the same five questions. The system wasn’t broken. It just had no spec — no iteration cap, no confidence gate, no contract for what the critic was supposed to return. The agent reflected itself into a hole.
That’s the failure mode this guide fixes. Not “which framework should I use.” That’s the wrong question. The right question is: what does my pipeline have to do, layer by layer, before I let any framework hold the wiring together?
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex) — you’ll be drafting components, not hand-typing them
- Working understanding of Retrieval Augmented Generation as a baseline pattern
- A document corpus you actually want to query, with a known eval set of 30–50 question/answer pairs
- API keys for an LLM provider and a reranker (or a self-hosted cross-encoder)
This guide teaches you: how to decompose an agentic RAG system into five spec-able layers, then sequence the build so cost and quality are measurable from the first commit.
The Build That Reflects Itself Into Bankruptcy
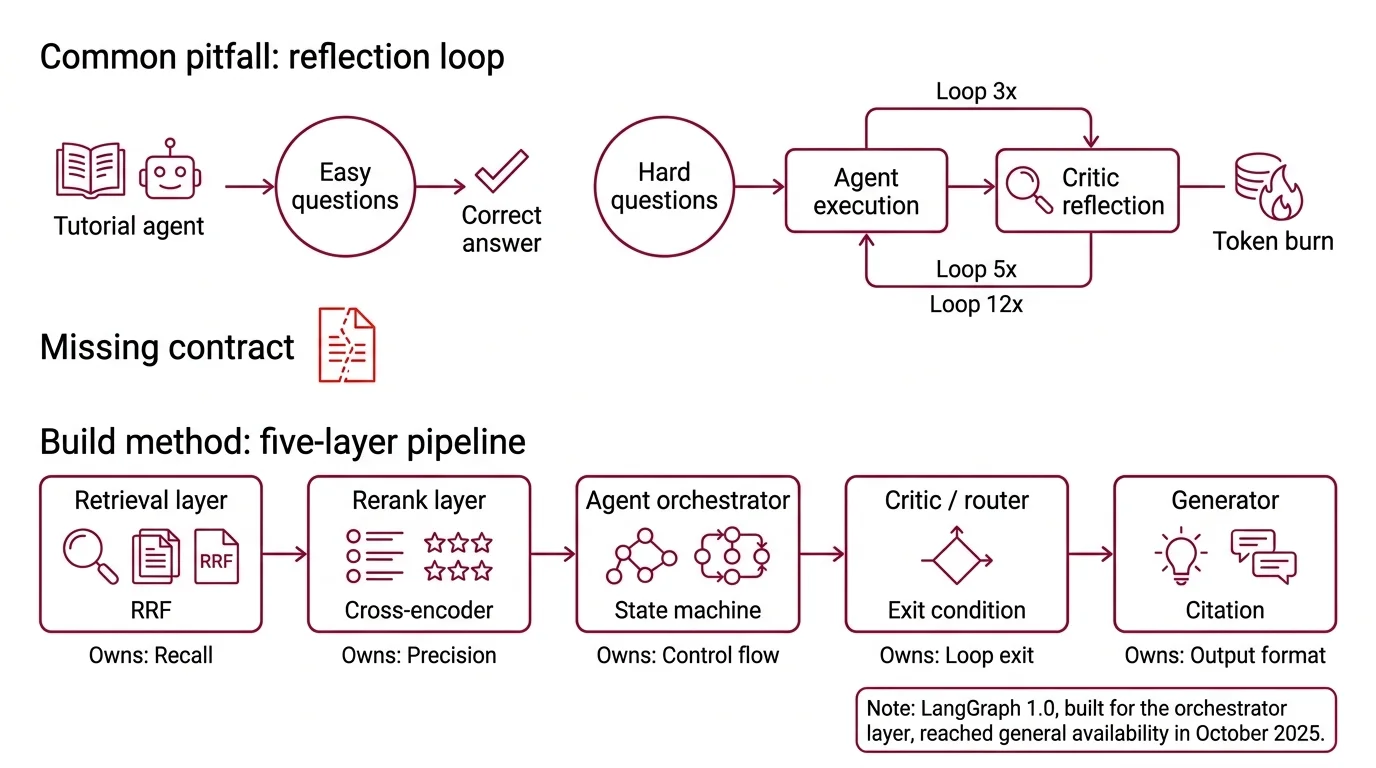
Here’s the pattern I see every other code review. Developer reads a “build an agent in 30 lines” tutorial. Wires LangGraph. Adds a reflection step. Ships to staging. The agent answers correctly on easy questions and loops three, five, twelve times on hard ones — burning tokens with each pass.
It worked on the demo set. On the production traffic, latency spiked because the critic kept saying “not confident, try again,” and nobody wrote down what “confident” means.
That’s not a model problem. That’s a missing contract.
Step 1: Decompose the Pipeline Into Five Layers
Stop thinking “agent framework.” Start thinking “pipeline of layers, each with a contract.” An agentic RAG system has five concerns and they belong in separate components.
Your system has these parts:
- Retrieval layer — runs Hybrid Search (BM25 + dense embeddings, fused with reciprocal rank fusion) over your corpus and returns a candidate set. Owns recall.
- Rerank layer — a cross-encoder scores each candidate against the query and reorders. Owns precision.
- Agent orchestrator — a graph state machine that holds the loop, routes between tools, and persists state. Owns control flow.
- Critic / router — decides whether the current context is enough to answer, whether to re-query, or whether to call a different tool. Owns the loop exit condition.
- Generator — the LLM that produces the final answer from the retained context. Owns output format and citation.
These are five different jobs. If your code has them tangled into one agent.run() call, the AI tool you’re working with cannot reason about where a failure originated. Neither can you at 2 AM.
This is also where the framework choice clicks into place. LangGraph is built for the orchestrator layer — graph state, durable checkpoints, explicit edges. The LangChain Changelog notes that LangGraph 1.0 reached general availability in October 2025, with built-in checkpointing so agents resume from their last state after a restart. LlamaIndex owns the retrieval layer — its Workflows 1.0 release, announced on the LlamaIndex Blog in June 2025, ships as a lightweight standalone framework with typed state and resource injection, and AgentWorkflow handles multi-agent handoff. Haystack Docs describe Haystack 2.28.0 as a modular pipeline composer where retrieval, routing, memory, and generation are wired explicitly — the deepset Studio visual builder is the giveaway that pipeline composition is the design center.
The Architect’s Rule: Pick frameworks per layer. The 2026 production pattern is LangGraph for orchestration, LlamaIndex for retrieval, Haystack for pipeline composition — not one framework to rule them all.
Step 2: Lock Down the Five Contracts Before You Write a Loop
Every layer needs a written contract. Without them the agent will improvise — and improvisation is what spikes your bill.
Context checklist for the retrieval layer:
- Embedding model and dimension specified (and pinned)
- Chunk size and overlap chosen (start at 512 tokens, measure, adjust)
- BM25 + dense fusion weights set explicitly (not “default”)
- Query Transformation rules: when do you rewrite, decompose, or expand
- Top-K candidate count fixed (typically 20–50 before rerank)
Context checklist for the rerank layer:
- Reranker model named and version pinned. Cohere Pricing lists Rerank 3.5 at $2.00 per 1,000 searches — and a “search” is one query against up to 100 documents, not per document. Miscount this and your cost model is off by two orders of magnitude.
- Top-N retained after rerank (typically 3–10)
- Score threshold for rejection (or explicit “always return top-N”)
Context checklist for the agent loop:
- Maximum iteration budget (hard cap, e.g., 4 loops)
- Confidence threshold for early exit
- Token budget per loop step
- Tool list with input/output schemas
- Contextual Retrieval state — what gets carried across iterations vs. discarded
Context checklist for the critic:
- Output is a structured JSON schema, not free text
- Schema fields:
confidence: float,missing_info: string,next_action: enum,done: bool - Failure mode for unparseable output (default to exit, don’t loop)
Context checklist for the generator:
- Output schema (JSON or strict markdown structure)
- Citation format — which fields from the retained context get rendered
- Refusal behavior when context is insufficient
The Spec Test: If your spec doesn’t name an iteration budget and a structured critic schema, the Vellum agentic-workflows guide reports that multi-step reflection loops typically consume 3–10x the tokens of classic RAG. Tiered orchestration with small-model routing can reclaim 40–60% of that. Both numbers depend on your traffic mix — measure on your eval set before you trust either.
Step 3: Build Retrieval First, Loop Last
Build order is not a preference. It’s a debugging strategy. If you wire the agent loop before the retrieval layer is solid, every loop iteration amplifies retrieval noise — and you can’t tell whether the agent is dumb or the index is.
Build order:
- Retrieval + rerank, no agent — get the hot path working as classic RAG. Measure recall@10 and precision@5 on your eval set. The Superlinked VectorHub benchmark reports hybrid-with-rerank reaching roughly 91% recall@10, versus 79% for hybrid alone and 58% for BM25 only. If your numbers are far from that order of magnitude, the index is the problem, not the agent.
- Generator with retrieved context — single-shot answer, no loops. Measure faithfulness and answer relevancy. Now you have a baseline cost-per-query and a baseline quality. Every later layer has to justify itself against this number.
- Agent loop with hard budget — wire LangGraph (or LlamaIndex Workflows, or Haystack Agent — pick one) with
max_iterations=1first. Yes, one. Prove the routing works before you let it iterate. - Critic with structured output — add the JSON-schema critic. Test that the parser fails closed (returns “done”) on bad output. Now raise
max_iterationsto your real budget. - Reflection / re-query — only now do you let the loop actually loop. Watch the iteration count distribution on your eval set. If most queries hit the cap, your confidence threshold is wrong.
For each component, your context must specify:
- What it receives — query, candidate set, prior loop state, etc.
- What it returns — typed schema, never free dict
- What it must NOT do — the critic doesn’t generate answers; the generator doesn’t re-query; the orchestrator doesn’t reformulate prompts
- How it fails — what’s the default exit when this component throws
Step 4: Prove It With RAGAS Before You Trust the Demo
Validation is not “I tried five questions and they looked right.” Validation is an automated eval suite running on every change, with thresholds that block merge.
Validation checklist:
- Faithfulness — does the answer cite only retrieved context. Ragas Docs target: > 0.9. Failure looks like: hallucinated quotes, invented dates, statistics that don’t appear in any retrieved chunk.
- Answer Relevancy — does the answer address the actual question. Target: > 0.85. Failure looks like: tangentially related information, partial answers, restating the question.
- Context Precision — are the top-ranked chunks the ones the answer actually used. Target: > 0.8. Failure looks like: high recall but low precision — the right chunk is in the candidate set but the rerank put it at position 9.
- Topic Adherence and Tool Call F1 — Ragas Docs added these in the v0.2 release in October 2024 specifically for agentic and tool-use evaluation. Failure looks like: agent called the wrong tool, or stayed on-topic but never reached the answer.
- Loop count distribution — log iterations per query. Failure looks like: long tail at the iteration cap. Means your critic is too pessimistic or your retrieval is too thin.
- Cost per query — token accounting at every layer. Failure looks like: P95 cost is 5x P50 — a few queries are eating the budget.
Security & compatibility notes:
- LangChain Core LangGrinch (CVE-2025-68664, CVSS 9.3): Serialization injection enabling secret extraction. The Hacker News reports the patch ships with breaking changes —
load()/loads()defaults now enforce an allowlist,secrets_from_env=False, and Jinja2 is blocked. Audit any pickled prompt templates.- LangGraph SQLite checkpoint (CVE-2025-67644, CVSS 7.3): SQL injection via metadata filter keys. Upgrade
langgraph-checkpoint-sqliteto ≥3.0.1.- LangChain path traversal (CVE-2026-34070): Legacy
load_prompt()andload_prompt_from_config()are deprecated and slated for removal in 2.0.0. Migrate now.- LangGraph 1.0 deprecation:
langgraph.prebuiltwas deprecated in October 2025 — functionality moved tolangchain.agents. Tutorials older than that will need updating.- Haystack 2.28.0: HTTP layer migrated from
requeststohttpx. Code catchingrequests.exceptions.RequestExceptionfrom Haystack components must move tohttpxexceptions.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Asked the AI to “build an agentic RAG system” in one prompt | It picks one framework, tangles all five layers in one file, no contracts | Decompose into five layers first; spec each contract before generating code |
| Skipped the iteration budget | Critic kept asking for “more context”; agent looped until rate limits hit | Hard max_iterations cap and a JSON-schema confidence gate |
| Used vector search only | Recall@10 too low; agent compensated by re-querying, burning tokens | Hybrid (BM25 + dense) with RRF fusion, then cross-encoder rerank |
| Free-text critic | Unparseable “the context seems insufficient” responses; ambiguous routing | Structured JSON: {confidence, missing_info, next_action, done} with closed-fail parser |
Imported from langgraph.prebuilt in 2026 | Broken or deprecated paths after the LangGraph 1.0 migration | Import from langchain.agents instead; pin LangGraph to 1.1.x |
| Quoted Cohere Rerank cost as per-document | Estimated cost 100x lower than reality, blew the budget in week one | Per-search pricing: 1 query × up to 100 docs = 1 search at $2/1K |
Pro Tip
Wire the eval harness before the agent loop. I see this skipped every time. Developers build the agent, get excited about a working demo, then add evaluation last as an afterthought — by which point the eval set is contaminated by the same questions they used to debug. Build RAGAS first, freeze a holdout set you never look at during development, and treat every metric drop as a regression to investigate before merge. The Liu et al. “lost in the middle” paper documents roughly a 30% accuracy drop when the relevant chunk lands in the middle of a long context — which is exactly the kind of subtle regression you’ll miss without a sealed eval.
Frequently Asked Questions
Q: How to build an agentic RAG pipeline step by step in 2026?
A: Decompose into five layers (retrieval, rerank, orchestrator, critic, generator), spec each contract, then build retrieval first and the agent loop last. The non-obvious sequencing rule: wire your RAGAS eval harness with a frozen holdout set BEFORE the agent loop exists. Otherwise you’ll debug the agent against the same questions you evaluate it on, and your faithfulness numbers will be sandbagged from day one.
Q: How to use agentic RAG for enterprise document Q&A?
A: Same five-layer decomposition, plus an ACL filter applied at retrieval time — never at the rerank or generation stage. The trap teams hit: filtering after retrieval looks correct in dev but leaks document existence (the rerank scores reveal that a forbidden chunk was in the candidate set). Filter inside the BM25 + dense queries so unauthorized chunks never enter the pipeline.
Q: How to apply agentic RAG to multi-source customer support workflows?
A: Promote the router from “decide when to re-query” to “decide which source to query” — knowledge base, ticket history, product docs, live status APIs. Each source becomes a tool with its own retrieval contract. Watch out for staleness: cache the KB index, but never cache live-status tool results. A confidently wrong “service is up” answer from a five-minute-old cache is worse than no answer.
Your Spec Artifact
By the end of this guide, you should have:
- A layer map — five named components with their inputs, outputs, and explicit non-responsibilities
- A contract checklist per layer — embedding pin, fusion weights, top-K, iteration budget, critic schema, generator output format
- A validation contract — RAGAS thresholds, agentic metrics, loop-count distribution, and per-query cost ceiling that blocks merge
Your Implementation Prompt
Drop this into Claude Code or Cursor at the start of a new agentic RAG project. It encodes the five-layer decomposition, every contract category, and the build order from this guide. Replace each bracketed placeholder with your concrete value — every bracket maps to a checklist item from Step 2.
Build an agentic RAG pipeline as five separate, contract-bound modules.
Do NOT generate a monolithic agent.run() entry point.
LAYER 1 — Retrieval (LlamaIndex):
Corpus: [path or vector-store URI]
Embedding model: [model name + dimension, pinned version]
Chunk size: [token count] / overlap: [token count]
Hybrid: BM25 + dense, RRF fusion weights [bm25_weight, dense_weight]
Query transformation: [none | rewrite | decompose | expand]
Returns top-K: [20-50] candidates
LAYER 2 — Rerank (Cohere Rerank 3.5 OR cross-encoder):
Model: [cohere/rerank-3.5 OR sentence-transformers model name]
Returns top-N: [3-10] after rerank
Score threshold: [float OR "always return top-N"]
LAYER 3 — Orchestrator (LangGraph 1.1.x):
max_iterations: [hard cap, e.g., 4]
Persistence: built-in checkpointing, store: [sqlite|postgres]
Tools: [list with input/output JSON schemas]
State carried across iterations: [list of fields]
LAYER 4 — Critic (structured output):
Output schema: { confidence: float, missing_info: string,
next_action: enum["retrieve","rewrite","answer"], done: bool }
Confidence threshold for early exit: [float, e.g., 0.85]
Unparseable output behavior: exit with done=true (fail closed)
LAYER 5 — Generator:
Output format: [strict JSON schema OR markdown template]
Citation format: [field list from retained context]
Refusal behavior when context insufficient: [explicit refusal string]
BUILD ORDER:
1. Layer 1 + 2 + 5, no agent. Measure recall@10, precision@5, faithfulness.
2. Add Layer 3 with max_iterations=1. Verify routing.
3. Add Layer 4 critic. Verify fail-closed parser.
4. Raise max_iterations to budget. Measure loop distribution.
VALIDATION (RAGAS, blocking on merge):
Faithfulness > [0.9]
Answer Relevancy > [0.85]
Context Precision > [0.8]
Tool Call F1 > [your threshold]
P95 cost per query < [$ ceiling]
Loop-count cap hit rate < [your threshold]
CONSTRAINTS:
- Do NOT import from langgraph.prebuilt (deprecated; use langchain.agents).
- Do NOT catch requests.exceptions from Haystack components — use httpx.
- Pin langgraph-checkpoint-sqlite >= 3.0.1.
- Critic NEVER generates answers. Generator NEVER re-queries.
Ship It
You no longer have an agentic RAG project — you have five modules with five contracts and a build order. The framework choice is now mechanical: LangGraph for the orchestrator, LlamaIndex for retrieval, Haystack for pipeline composition. The cost is now measurable because the iteration budget is in the spec, not in the agent’s mood. Ship the retrieval layer first. Earn the loop later.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors