Agent Evaluation Pipeline: LangSmith, Braintrust, DeepEval (2026)

Table of Contents
TL;DR
- Agent evaluation is not LLM evaluation. You score trajectories — plan, tool calls, arguments, final answer — not just text.
- One platform will not cover the surface area. You need a CI test layer, an experiments layer, and a production trace layer running together.
- Specify the contract before you wire the tools. Decide what “correct trajectory” means before you pick a metric.
A support agent ships on Friday. It calls lookup_customer, then get_balance, then drafts a reply. By Wednesday it is calling get_balance first with a fabricated customer ID, getting a permission error, then apologizing fluently. The final message looks fine. The trajectory is broken. Nobody saw it because the only thing being scored was the last reply.
That is the failure mode this guide is built around — and it is the reason Agent Evaluation And Testing is its own discipline now, not a corner of LLM eval.
Before You Start
You’ll need:
- A working agent (LangGraph, OpenAI Agents SDK, CrewAI, or your own loop) you can instrument
- Understanding of Deepeval or comparable Pytest-style eval framework concepts
- A frozen set of representative tasks — at least a dozen — with known-good trajectories
- Python 3.10+, a CI runner you control, and the ability to add an SDK to the agent process
This guide teaches you: how to decompose agent quality into three eval surfaces — pre-merge regression tests, experiment-driven prompt and model changes, and production trajectory monitoring — and how to specify each so the AI tool you ask to wire it up actually wires it up correctly.
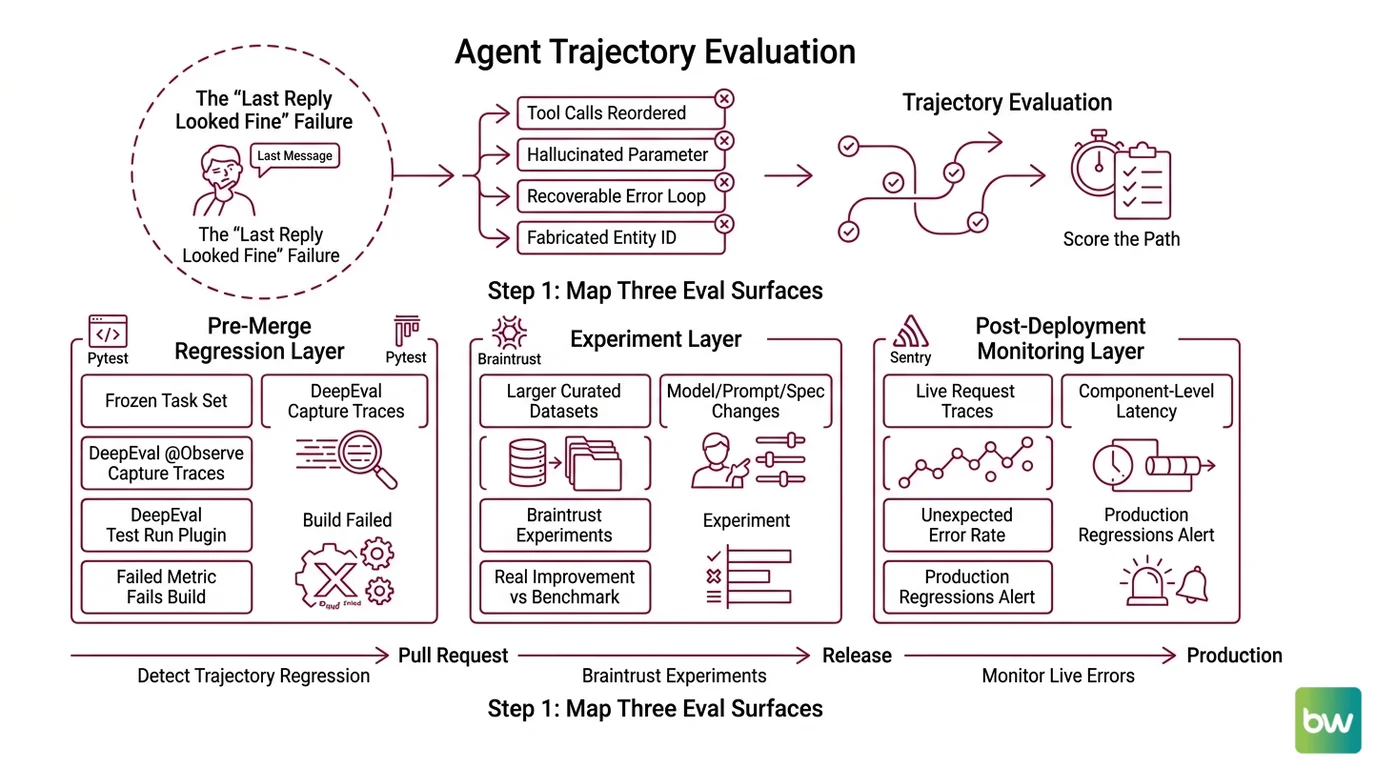
The “Last Reply Looked Fine” Failure
Most agent pipelines are validated by the developer running ten scripted scenarios in a notebook and squinting at the final assistant message. That is not evaluation — it is reading the last page of a detective novel and grading the plot.
What breaks in production is consistent. The agent reorders tool calls. It hallucinates a parameter. It loops twice on a recoverable error and gives up. It fabricates an entity ID, swallows the failure, and produces a polite, useless answer. Each of those failures is invisible if you only score the final string. The original LangChain AgentExecutor pattern is now deprecated in favor of LangGraph (LangChain release policy), and tutorials still teaching the old loop are stale — your spec needs to match the runtime you actually ship.
You will not catch trajectory regressions by reading outputs. You catch them by scoring the path the agent took, automatically, on every pull request and again on every live request.
Step 1: Map the Three Eval Surfaces
Agent evaluation is not one platform. It is three jobs running at three different times against three different inputs, and they fail differently. Decompose before you specify.
Your system has these parts:
- Pre-merge regression layer — runs on a frozen task set inside Pytest. Tells you whether a code change to the planner, the prompt, or a tool wrapper made trajectory quality go up or down. This is where DeepEval lives. DeepEval’s
@observedecorator captures component-level traces, anddeepeval test runworks as a Pytest plugin so a failed metric fails the build (DeepEval Docs). - Experiment layer — runs offline against larger curated datasets when you change a model, a system prompt, or a tool spec. Tells you whether the change is a real improvement or a benchmark coincidence. This is Braintrust’s slot. Braintrust is positioned as eval-first with CI/CD blocking, datasets, experiments, and a prompt playground (Braintrust homepage), and the Pro plan starts at $249/month with unlimited trace spans (Braintrust’s pricing page).
- Production trajectory layer — captures every live agent run, scores it asynchronously, and surfaces the regressions the first two layers missed. LangSmith owns this slot because of full trajectory capture — steps, tool calls, intermediate decisions — with evaluators that can score reasoning, not just final answers (LangSmith Docs). The Plus tier is $39/seat/month with 10,000 base traces (LangChain’s pricing page).
These layers do not substitute for each other. The Pytest layer tells you the agent can execute the task. The experiment layer tells you a change is an improvement. The production layer tells you what the first two layers did not anticipate.
The Architect’s Rule: If a regression fires and you cannot point to the layer that should have caught it, you do not have a pipeline. You have three dashboards.
Step 2: Lock Down What “Correct Trajectory” Means
Before you install a single SDK, write the contract. The reason teams adopt three eval platforms, get a forest of green checks, and still ship broken agents is that they never specified what a correct trajectory looks like for their domain.
Context checklist:
- Plan quality. Did the agent decide on a sensible sequence of steps before acting? DeepEval ships a
PlanQualityMetricand aPlanAdherenceMetricfor exactly this distinction — the first scores the plan, the second scores whether the agent stuck to it (DeepEval Docs). - Tool correctness. Was the right tool called for the right step? Were the arguments well-formed and grounded in the user’s input?
ToolCorrectnessMetricandArgumentCorrectnessMetriccover this layer in DeepEval. - Execution efficiency. Did the agent finish in a reasonable number of steps without redundant retries?
TaskCompletionandStepEfficiencyclose out the metric stack. - Final answer faithfulness. Does the answer reflect what the tools actually returned, or did the model paraphrase it into something else?
- Pass threshold for CI. If trajectory score drops below X on the regression set, the build fails. Pick X before you measure, not after.
- Pass threshold for production alerts. When an online evaluator fires, what happens? Page someone? Open an issue? Rewrite the response? Each is a different spec.
- Ground truth source. Are reference trajectories human-authored, generated by a stronger model, or both? Mixing without labeling is how datasets rot.
The Spec Test: If you cannot answer “what should the agent have done?” for every task in your eval set, you are not measuring correctness. You are measuring agreement with whatever the agent did first.
Step 3: Wire the Components in the Right Order
Build the layers from the cheapest signal to the most expensive. Order matters because each layer’s failures inform the next layer’s spec.
Build order:
- DeepEval first — it runs locally and in CI without external infrastructure. Wire
@observeinto the agent’s planning and tool-calling functions, write metrics for plan quality, tool correctness, and task completion against the frozen task set, and gate the build withdeepeval test run. This catches the regressions a unit test author would expect to catch. - Braintrust second — once the regression layer is green, you can run experiments. Push the same task set as a Braintrust dataset, then run experiments when you swap models, change the system prompt, or rewrite a tool description. This is where you decide whether
gpt-5.1-miniactually beatsclaude-sonnet-4-7for your agent before you ship it. - LangSmith third — instrument the deployed agent, capture full trajectories, and configure online evaluators that score live runs against the same metric definitions you used in CI. Production traces flow back into the regression set when they reveal failure modes nobody specified.
For each layer, your context must specify:
- What it observes — which agent functions are wrapped, which intermediate state is captured
- Which metrics run — by name, with thresholds and weights
- What “fail” does — block the merge, block the deploy, page on-call, or just record
- How datasets flow back — production failures must become regression cases, or the loop is open
Security & compatibility notes:
- LangSmith / LangChain tracing: Traces from
langchain-coreversions before 1.2.4 lose token-count and cost metadata, and.transform()/.atransform()inputs may not appear in the dashboard. Pin tolangchain-core>=1.2.4(LangChain GitHub issue #34689).- LangChain agents: The pre-1.0
AgentExecutoris deprecated; use LangGraph for new agents and treat any tutorial that importsAgentExecutoras out of date (LangChain release policy).- Langfuse self-host: Langfuse v3 requires a six-service stack —
langfuse-web,langfuse-worker, ClickHouse, MinIO, Redis 7, PostgreSQL 17 — because trace storage moved from PostgreSQL to ClickHouse for fast aggregation (Langfuse Docs). Single-container deployment guides no longer match the supported topology.
Step 4: Validate That the Pipeline Catches What It Should
A pipeline you cannot break on purpose is a pipeline you cannot trust. Before you call any of this done, run the failure drill.
Validation checklist:
- Inject a planning regression. Force the agent to skip a step. Does the regression layer fail with a
PlanAdherenceMetricdrop? Failure looks like: build still green, metric dashboard flat. - Inject a tool argument bug. Pass a malformed parameter to a known-good tool. Does
ArgumentCorrectnessMetriccatch it? Failure looks like: tool error logs only, no eval signal. - Swap to a weaker model in the experiment layer. Does Braintrust show the regression as a measurable score delta, not a vibe? Failure looks like: the team argues for a week about whether the new model is “actually worse.”
- Disable the response gate, send a known-bad live request. Does the LangSmith online evaluator fire? Failure looks like: the trace is captured but no evaluator runs.
- Promote a production failure to a regression case. Pull a real failed trace, freeze it as a CI test, confirm DeepEval reproduces the failure offline. Failure looks like: the failure cannot be reproduced because production state was not captured.
If any one of those drills passes silently, the layer is decorative. Fix it before you trust the green check.
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
| Scored only the final assistant message | Tool-call regressions are invisible at the output layer | Score the trajectory: plan, tool selection, arguments, completion |
| Picked one platform for everything | Each platform is strongest at one of the three eval surfaces | Use DeepEval for CI, Braintrust for experiments, LangSmith for production |
| Wrote metrics after measuring | Thresholds calibrated to current behavior cannot detect regressions | Define pass thresholds and metric weights before the first run |
| Promoted prod failures into bug tickets, not regression tests | The same failure ships again next quarter | Every confirmed prod failure becomes a frozen DeepEval case |
| Trusted vendor leaderboards uncritically | No live ELO leaderboard exists for agent eval platforms — rankings are editorial, not measured | Re-evaluate tools against your task set, not someone else’s |
Pro Tip
The metric set is part of the spec, not the implementation. Treat metric definitions like API contracts: version them, review them in pull requests, and refuse changes that move thresholds without an attached experiment. A team that quietly lowers a faithfulness threshold to make CI pass has not improved the agent. They have improved the dashboard. Make that change visible.
Frequently Asked Questions
Q: How to build an agent evaluation pipeline step by step? A: Decompose into three layers: DeepEval in Pytest for regression, Braintrust for experiments on model and prompt changes, LangSmith for production trajectory traces. Specify metric thresholds before you measure. Watch out: hosting all three platforms simultaneously costs more than one strong layer plus disciplined dataset hygiene.
Q: How to use LangSmith for agent regression testing?
A: LangSmith captures the full trajectory — steps, tool calls, intermediate reasoning — and runs evaluators on intermediate decisions, not only final outputs (LangSmith Docs). Pin langchain-core>=1.2.4 or token-count and cost metadata go missing from your traces. Without that pin, regression dashboards lie.
Q: When to choose Braintrust vs Langfuse vs Arize Phoenix for agent eval? A: As of May 2026, editorial consensus places Langfuse v3 as the OSS leader (widest framework coverage), Braintrust as the eval-first CI gate, and Arize Phoenix as the OpenTelemetry-native option for OpenAI Agents SDK stacks (Phoenix Docs). Pick by where you sit on self-hosting and CI gating, not marketing.
Your Spec Artifact
By the end of this guide, you should have:
- A three-layer eval map naming which agent functions each layer observes and which metrics each layer runs
- A constraint list — pass thresholds, alert behavior, ground truth provenance, dataset feedback loop — versioned in your repo
- A failure-drill checklist that proves each layer catches the class of regression it owns
Your Implementation Prompt
Drop this into Claude Code, Cursor, or Codex when you are ready to wire the pipeline. Replace the bracketed placeholders with the values from your Step 2 contract, then let the AI tool generate the scaffolding. Treat the output as a first draft to review against your map, not finished code.
Build the agent evaluation pipeline below. Do not implement before
restating the contract back to me.
Agent runtime: [LangGraph | OpenAI Agents SDK | CrewAI | custom loop]
Agent functions to instrument: [planner_fn, tool_router_fn, finalizer_fn]
Frozen task set location: [path/to/tasks.jsonl]
Layer 1 — Pre-merge regression (DeepEval, Pytest):
Metrics: [PlanQualityMetric, PlanAdherenceMetric, ToolCorrectnessMetric,
ArgumentCorrectnessMetric, TaskCompletion, StepEfficiency]
Thresholds: [trajectory_score >= X, tool_correctness >= Y]
Fail action: [block PR merge]
Layer 2 — Experiments (Braintrust):
Dataset name: [agent_eval_v1]
Triggers: [model swap, system prompt change, tool spec change]
Pass criterion: [score delta >= Z vs. last shipped baseline]
Layer 3 — Production (LangSmith):
Pin: langchain-core>=1.2.4
Online evaluators: [trajectory_faithfulness, tool_correctness]
Alert action: [page on-call | open issue | record only]
Feedback loop:
Every confirmed production failure must be promoted to a frozen
DeepEval test case in [path/to/tasks.jsonl] within [N] business days.
Build order: Layer 1, then Layer 2, then Layer 3.
For each layer, output: instrumentation code, metric configuration,
fail-action wiring, and one failure-drill test that proves the layer
catches its own class of regression.
Ship It
You now have a mental model that separates three eval surfaces — pre-merge, experiment, production — and three platforms that each do one of those jobs well. You can decompose any agent quality question into the layer that should have caught it, which means you can answer “did our eval pipeline fail, or did our agent regress?” without guessing.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors