How to Build an Active Learning Loop with modAL, Cleanlab, and Prodigy in 2026
TL;DR
- Active learning pays off only when you label what the model is uncertain about — random sampling wastes your budget on examples the model already gets right.
- The loop is three jobs and three tools: modAL picks the next batch, Cleanlab catches bad labels, Prodigy puts a human in the seat. Specify the contract between them before you wire anything.
- modAL still works but is effectively unmaintained — pin your versions, test against your scikit-learn, and know that scikit-activeml is the active fallback if that’s a dealbreaker.
You had a budget for 50,000 labels. You spent it. The model got better — a little. Then you looked at what you actually paid to annotate, and half of it was examples the model was already calling correctly with 99% confidence. You paid human annotators to confirm what the model already knew. That’s the failure mode Active Learning exists to kill, and most teams reintroduce it the moment they skip the part where you specify which examples are worth a human’s time.
Before You Start
You’ll need:
- A Pool Based Sampling setup — a large pool of unlabeled data plus a small seed set of labeled examples to train the first model
- A Scikit Learn-compatible base model (the loop is built around that interface)
- Three tools installed: modAL for query strategy, Cleanlab for label-quality checks, and Prodigy for annotation
- A working understanding of Uncertainty Sampling and why model confidence is the signal that drives the whole loop
This guide teaches you: how to decompose an active learning loop into four stages with clean contracts between them, so each tool does exactly one job and you can debug the loop when — not if — it stalls.
The 50,000-Label Budget You Already Wasted
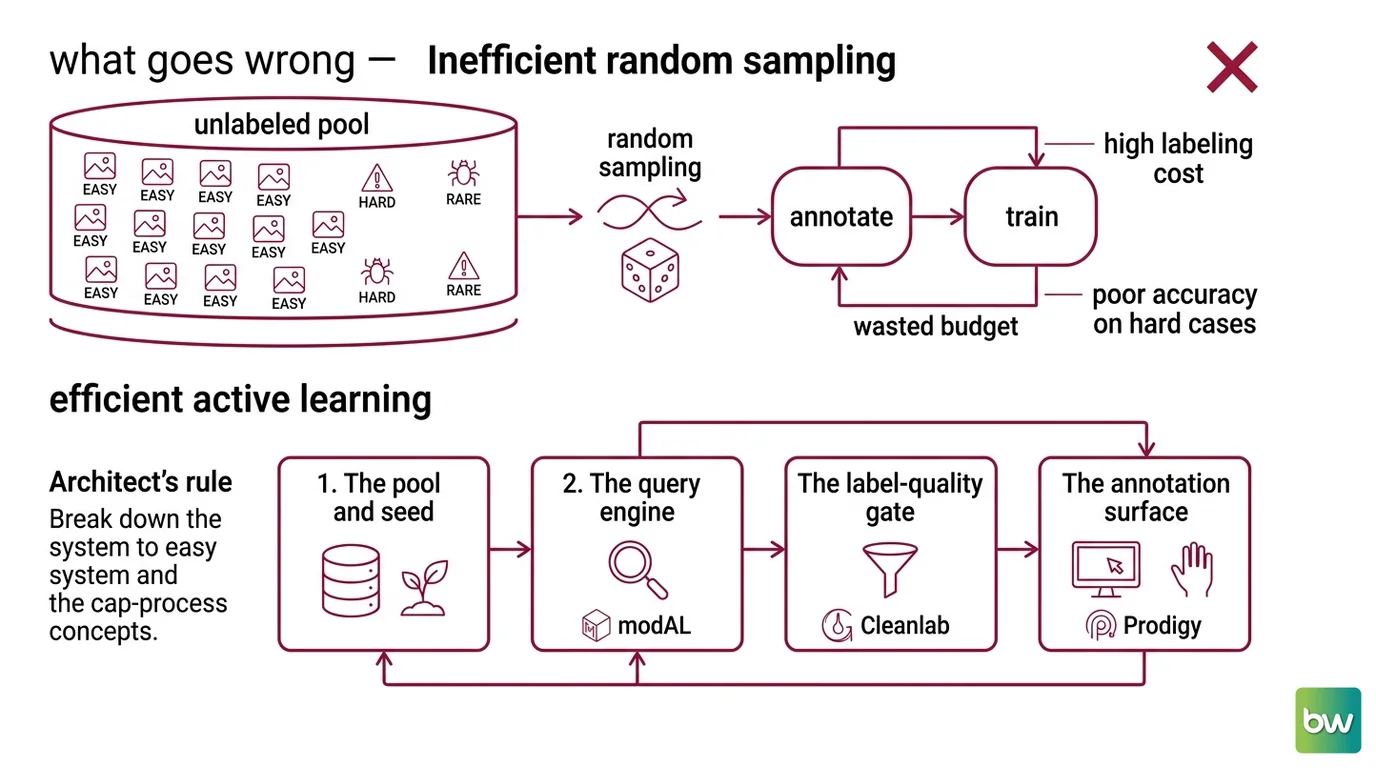
Here’s what goes wrong. You take your unlabeled pool, send a random sample to annotators, train, and repeat. It feels like progress because the labeled count goes up. But random sampling spends most of your money on the easy middle of the distribution — examples the model would have classified correctly anyway. The hard cases, the ambiguous ones, the rare classes that actually move accuracy — those show up at their natural (low) frequency, which is to say almost never.
It worked fine in the demo on Friday. On Monday someone pointed at the confusion matrix and asked why the minority class still had garbage recall after 50,000 labels. The answer: the loop never specified that uncertain examples should be prioritized, so it never saw enough of them.
Step 1: Decompose the Loop Into Four Stages
Before you install anything, draw the loop. An active learning system is not one program — it’s four stages passing data to each other, and most people fail because they treat it as a single script that “does active learning.”
Your system has these parts:
- The pool and seed — the unlabeled pool you draw from and the small labeled seed that trains the first model. This is a separate concern because the Cold Start Problem lives here: too small a seed and your first model’s uncertainty estimates are noise.
- The query engine — modAL. It takes the current model plus the pool and returns the next batch to label. Its only job is ranking. It does not train, label, or clean.
- The label-quality gate — Cleanlab. It inspects labels coming back from humans (and the seed itself) for errors, outliers, and duplicates. It interfaces between annotation and training.
- The annotation surface — Prodigy. A human sits here. It receives modAL’s batch and returns labels. Its contract is input (examples to label) and output (labels), nothing more.
The Architect’s Rule: If you can’t explain the loop in four stages with one input and one output each, the AI tool you’re prompting can’t build it either. Decomposition is the spec.
modAL is built on top of scikit-learn with modular query strategies, a detail confirmed in modAL Docs — which is exactly why it slots in as a pure ranking stage without owning your model.
Step 2: Specify the Query Strategy Contract
This is where most loops are won or lost. The Query Strategy is the rule that decides which examples are “worth it.” Specify it explicitly, because the default is rarely right for your data.
Context checklist — what the query engine must know before it ranks anything:
- The base model’s prediction interface — modAL needs
predict_probaor a decision function to estimate uncertainty - Which strategy — pure Uncertainty Sampling, Diversity Sampling, Query By Committee, or a hybrid
- Batch size — how many examples per round, which trades off retraining cost against annotator idle time
- Stopping criterion — when the loop ends (accuracy plateau, budget exhausted, uncertainty floor reached)
- The cold-start handling — how the first batch is chosen before the model is trustworthy
The single most important decision here: uncertainty sampling finds hard examples; diversity sampling finds the full shape of your data. Uncertainty alone will happily hand you a hundred near-identical ambiguous examples from the same cluster. That’s redundant labeling, just dressed up as work.
The Spec Test: If your query strategy is pure uncertainty and your pool has tight clusters, the AI will build a loop that asks humans to label the same confusing example a dozen times. Add a diversity term to the contract, or your annotation budget drains into one corner of the distribution.
Step 3: Sequence the Build From Seed to Loop
Order matters because each stage depends on the output of the one before it. Build out of order and you’ll be debugging a loop whose first iteration was already poisoned.
Build order:
- The seed and label-quality gate first — because your seed labels train the first model, and a model trained on dirty labels produces dirty uncertainty estimates. Run Cleanlab on the seed before anything else. Cleanlab detects label errors, outliers, and near-duplicates and is model-agnostic across PyTorch, sklearn, XGBoost, and HuggingFace, per Cleanlab Docs.
- The query engine next — because it depends on a trained model’s probability outputs. Wire modAL only after you have a clean seed and a fitted model.
- The annotation surface last — because Prodigy consumes modAL’s ranked batch. Prodigy is built by Explosion, the makers of spaCy, and ships cloud-free with built-in active-learning recipes, according to Prodigy — which means the annotation stage and the query stage can speak the same language.
For each stage, your context must specify:
- What it receives (inputs)
- What it returns (outputs)
- What it must NOT do (the query engine must not mutate labels; the annotation surface must not retrain)
- How to handle failure (an empty pool, a tie in uncertainty scores, an annotator skip)
Every round, the new labels flow back through Cleanlab before they reach training. That gate is what keeps Training Data Quality from degrading as the loop accumulates human error.
Security & compatibility notes:
- modAL (maintenance): As of mid-2026, modAL’s last release was 0.4.2 (June 2024) — roughly two years stale, with dozens of open issues and pull requests per modAL’s GitHub repository. It still installs and runs, but pin your version and test against your current scikit-learn release rather than assuming compatibility.
- modAL alternative: If an unmaintained dependency is a blocker for production, scikit-activeml is an actively developed library covering the same query strategies. Swap it in at the query-engine stage — the loop contract doesn’t change.
- Cleanlab (version): Use cleanlab 2.9.0 (January 2026), which requires Python 3.10+. Drop any legacy Python 3.8/3.9 examples you find in older tutorials.
Step 4: Prove the Loop Actually Saves Labels
A loop that runs is not a loop that works. You need to prove it beats the baseline, or you’ve built an expensive random sampler.
Validation checklist:
- Compare against random sampling — failure looks like: your active learning curve tracks the random-sampling curve. If labeling the “uncertain” examples doesn’t beat labeling random ones, your query strategy is broken or your model’s confidence is uncalibrated.
- Check label quality every round — failure looks like: accuracy climbs, then stalls or drops. That’s human label error compounding. Run Cleanlab each round and watch the flagged-error count, not just the model score.
- Watch for redundant queries — failure looks like: Cleanlab’s Data Deduplication flags many near-duplicates in your labeled set. Your query strategy is over-sampling one region; add diversity.
- Confirm minority-class movement — failure looks like: overall accuracy rises but per-class recall on rare classes stays flat. The loop is optimizing the easy majority. Re-weight the query strategy toward the classes you actually care about.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| One-shot “build me active learning” | Too many concerns in one script; the AI fused query, clean, and label into a tangle you can’t debug | Decompose into four stages with explicit contracts first |
| Pure uncertainty sampling | AI over-samples one ambiguous cluster; budget drains into redundant labels | Add a diversity term to the query-strategy spec |
| Skipped the seed clean | First model trains on dirty labels; every uncertainty estimate downstream is noise | Run Cleanlab on the seed before fitting the first model |
| Assumed modAL is current | AI generates code against an API that may not match your sklearn version | Pin versions; test against your stack, or swap in scikit-activeml |
| No baseline comparison | You can’t tell if the loop beats random; you ship an expensive coin flip | Plot the active learning curve against random sampling every run |
Pro Tip
Treat calibration as a precondition, not an afterthought. Every query strategy that ranks by uncertainty assumes the model’s confidence scores mean something. A model that’s 99% confident and wrong half the time will send your annotators straight to the easy examples while skipping the hard ones. Before you trust the loop, check that predicted probabilities track actual accuracy. If they don’t, calibrate first — otherwise you’ve built a loop that confidently selects the wrong work, and no amount of clever sampling fixes a lying confidence score.
Frequently Asked Questions
Q: How to build an active learning loop with modAL step by step? A: Clean your seed with Cleanlab, fit a scikit-learn model, then let modAL rank the pool by uncertainty, label the top batch in Prodigy, retrain, repeat. The step most people skip: re-run Cleanlab on returned labels every round, not just on the seed — human error accumulates and quietly poisons later uncertainty estimates.
Q: How to use active learning to cut annotation costs on a limited labeling budget? A: Spend labels only where the model is uncertain instead of sampling randomly, and stop the loop the moment the accuracy curve plateaus rather than burning the full budget. Watch out for the cold start: with too small a seed, early uncertainty scores are noise, so your first few rounds may waste labels before the signal stabilizes.
Q: How to choose between uncertainty sampling and diversity sampling for your dataset? A: Use uncertainty sampling when your data is spread out and you want the hardest cases; use diversity sampling when your pool has tight clusters that uncertainty alone would over-sample. The practical answer is usually a hybrid — uncertainty to find hard examples, diversity to keep them from all coming from the same corner of the distribution.
Your Spec Artifact
By the end of this guide, you should have:
- A four-stage loop map — seed/pool, query engine, quality gate, annotation surface — with one input and one output defined per stage
- A query-strategy contract specifying strategy type, batch size, stopping criterion, and cold-start handling
- A validation plan that compares your loop against random sampling and tracks label quality and minority-class recall every round
Your Implementation Prompt
Drop this into Claude Code, Cursor, or your AI tool of choice once you’ve filled the brackets with your own values. It mirrors the four-stage decomposition above so the tool builds the loop you specified, not the one it guessed at.
Build an active learning loop in Python with four separate, testable stages.
Do not fuse them into one script.
STAGE 1 — SEED & QUALITY GATE
- Base model: [your scikit-learn-compatible model]
- Seed set: [size and source]
- Run Cleanlab (2.9.0, Python 3.10+) on the seed to flag label errors,
outliers, and near-duplicates BEFORE fitting the first model.
STAGE 2 — QUERY ENGINE
- Library: modAL [pin version 0.4.2; test against my scikit-learn X.X]
OR scikit-activeml if modAL is incompatible.
- Strategy: [uncertainty | diversity | query-by-committee | hybrid]
- Batch size: [N per round]
- Stopping criterion: [accuracy plateau | budget exhausted | uncertainty floor]
- Constraint: ranking only. Must not train or mutate labels.
STAGE 3 — ANNOTATION SURFACE
- Tool: Prodigy with an active-learning recipe.
- Input: modAL's ranked batch. Output: labels. Must not retrain.
- Every returned batch passes back through Cleanlab before training.
STAGE 4 — VALIDATION
- Plot the active learning curve against a random-sampling baseline.
- Report per-class recall, not just overall accuracy.
- Flag redundant queries via Cleanlab deduplication each round.
Edge cases to handle: empty pool, tie in uncertainty scores, annotator skip,
cold start with an undersized seed.
Ship It
You now have a mental model that turns “do active learning” into four stages with contracts you can specify, test, and debug independently. You can look at a stalled loop and know whether the problem is a dirty seed, an over-eager query strategy, or a model whose confidence is lying to you. That’s the difference between a loop that saves labels and one that just spends them in a fancier order.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors