How to Build a VAE in PyTorch and Apply It to Anomaly Detection and Data Augmentation in 2026

Table of Contents
TL;DR
- A VAE has four separable concerns — encoder, reparameterization, decoder, loss function — and your spec must address each one independently
- The reconstruction-vs-KL balance is the single constraint most AI-generated VAEs get wrong — specify it or the model collapses
- Validate by checking loss components separately, not just the total loss number
You asked your AI coding tool to build a Variational Autoencoder. It gave you an autoencoder. No KL divergence term. No reparameterization layer. Just a compression function that memorizes training data and generates noise when you sample from it. Two days of debugging a model that was architecturally wrong from the first line.
Before You Start
You’ll need:
- An AI coding tool — Claude Code, Cursor, or Codex
- Working knowledge of PyTorch tensor operations and autograd
- Understanding of Neural Network Basics for LLMs — forward pass, backpropagation, loss computation
- Familiarity with Convolutional Neural Network layers (Conv2d, ConvTranspose2d) for image data
- A clear picture of what your VAE should produce — anomaly scores, synthetic samples, or controlled generation
This guide teaches you: how to decompose a VAE into four specification concerns so your AI tool generates each component correctly — and how to extend that spec for anomaly detection and data augmentation.
The Autoencoder That Wasn’t
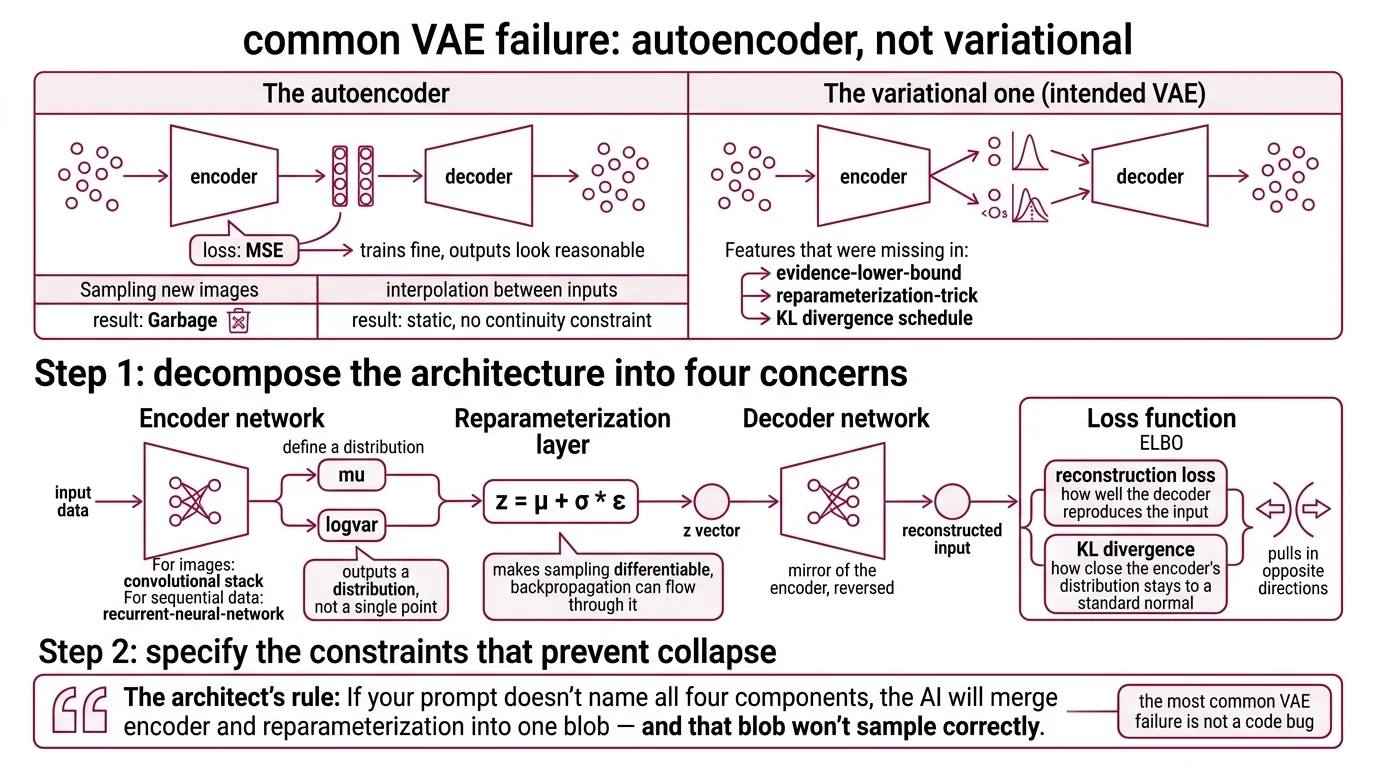
Here is the failure mode I see most often. Developer types: “Build me a VAE in PyTorch for image generation.” AI produces an encoder-decoder pair with an MSE loss. Trains fine. Loss goes down. Outputs look reasonable on the training set.
Then you sample new images. Garbage. The model never learned a structured representation — it learned to copy. The spec never mentioned the Evidence Lower Bound, the Reparameterization Trick, or the KL divergence schedule. The AI built an autoencoder, not a variational one.
It worked on Monday. On Wednesday, you tried interpolating between two inputs and got static — because the encoding had no continuity constraint.
Step 1: Decompose the Architecture Into Four Concerns
A VAE is not one model. It is four components, and each has a different job.
Your system has these parts:
- Encoder network — takes input data, outputs two vectors: mu and logvar. These define a distribution over the encoding, not a single point. For images, this is a convolutional stack. For sequential data, it might use a Recurrent Neural Network instead.
- Reparameterization layer — samples from the distribution using z = mu + sigma * epsilon. This makes the sampling step differentiable so backpropagation can flow through it.
- Decoder network — takes the sampled z vector and reconstructs the original input. Mirror of the encoder, reversed.
- Loss function — the ELBO, combining reconstruction loss (how well the decoder reproduces the input) with KL divergence (how close the encoder’s distribution stays to a standard normal). These two terms pull in opposite directions.
The Architect’s Rule: If your prompt doesn’t name all four components, the AI will merge encoder and reparameterization into one blob — and that blob won’t sample correctly.
Step 2: Specify the Constraints That Prevent Collapse
The most common VAE failure is not a code bug. It is KL collapse — the model ignores the KL term entirely, pushing all information through reconstruction alone. Your spec must prevent this.
Context checklist:
- PyTorch version: 2.11.0 with
torch.compileenabled (PyPI) - Input shape and dtype: exact tensor dimensions
- Latent dimension: 32-256 for images, 8-64 for tabular
- Loss weighting: beta parameter — start at 0.1, anneal to 1.0
- Reconstruction loss: BCE for normalized inputs, MSE for continuous
- KL divergence: closed-form Gaussian against standard normal prior
- Optimizer: Adam, lr 1e-3 to 1e-4
- Model export:
torch.export— TorchScript is deprecated as of PyTorch 2.6
The Spec Test: If your context doesn’t specify the beta schedule, the AI will hardcode beta=1.0. Half the time, the KL term dominates early and the model never learns useful reconstructions. The other half, reconstruction dominates and you get a fancy autoencoder with no generation capability. Specify the annealing schedule or lose the variational part entirely.
Step 3: Wire the Components in Dependency Order
Order matters. Build the contract first, then the components that depend on it.
Build order:
- Loss function first — it defines what “correct” means. Specify reconstruction and KL as separately tracked values. You need to monitor them independently.
- Encoder second — produces mu and logvar, which feed the loss. Specify the output as two separate tensors, not one concatenated vector.
- Reparameterization third — one function, three operations:
std = exp(0.5 * logvar),eps = randn_like(std),z = mu + eps * std(PyTorch Forums). Specify it explicitly or the AI will skip it. - Decoder last — depends on z’s dimensionality, which the encoder and reparameterization define.
For each component, your context must specify:
- What it receives (input tensor shape)
- What it returns (output tensor shape)
- What it must NOT do (encoder must NOT return a single point; decoder must NOT include sigmoid if your loss already includes it)
- How to handle failure (NaN detection, gradient clipping if KL spikes)
Step 4: Prove the VAE Is Actually Variational
Total loss going down means nothing by itself. A regular autoencoder’s loss also goes down. You need to verify the variational part.
Validation checklist:
- KL divergence is non-zero and stable — failure looks like: KL stuck at 0.0 for multiple epochs. Diagnosis: posterior collapse. Fix: lower beta, increase latent dimension, add KL annealing warmup.
- Reconstruction loss decreases independently — failure looks like: reconstruction plateaus while KL drops. The model is encoding everything as the same distribution.
- Samples from the prior look reasonable — sample z from N(0,1), decode. If the output is noise, the decoder never learned to use the structure.
- Interpolations are smooth — encode two inputs, interpolate between their z vectors, decode. Jumpy transitions mean the representation is not continuous.
Extending the Spec: Anomaly Detection
Once your base VAE works, anomaly detection is a specification extension — not a new model.
The principle: a trained VAE reconstructs normal data well and abnormal data poorly. The reconstruction error becomes your anomaly score. Set a threshold at a high quantile of the training loss distribution — the 0.999 quantile is a common starting point.
Add to your spec:
- A separate evaluation pass that computes per-sample reconstruction error
- A threshold computed from the training set’s loss distribution
- A flag for whether you need pixel-level anomaly maps (localization) or sample-level scores (classification)
For production visual data, ViT-VAE variants outperform baseline VAEs across standard benchmarks (Nguyen et al.). If your domain demands localization accuracy, specify a Vision Transformer encoder instead of a convolutional one.
Extending the Spec: Data Augmentation
VAEs generate new samples by decoding from the learned distribution. For augmentation when training data is limited, you expand the dataset with synthetic examples that share the statistical structure of your real data.
The honest trade-off: VAE-generated samples are blurrier than what GANs or diffusion models produce (PMC Review). For tasks where visual fidelity matters — medical imaging, defect detection — consider VQ-VAE variants or InfoVAE. For tabular data or feature-level augmentation, standard VAEs work well.
Add to your spec:
- Number of synthetic samples to generate per class
- Quality threshold: minimum reconstruction quality to accept a generated sample
- Diversity check: ensure generated samples don’t cluster around a few modes
Latent Diffusion models like Stable Diffusion use a VAE as their compression backbone — compressing 512x512x3 images to 64x64x4 representations. If your augmentation needs scale beyond base VAE quality, the specification extends into that territory. Start simple. Get the base right first.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| One-shot “build me a VAE” | AI merged encoder and reparameterization, skipped KL term | Decompose into four components with separate specs |
| No beta schedule specified | AI hardcoded beta=1.0, causing KL or reconstruction collapse | Specify beta=0.1 with linear annealing to 1.0 over first 50 epochs |
Used torch.load defaults | Security warning — weights_only parameter changed in recent PyTorch | Specify torch.load(..., weights_only=True) explicitly |
| Referenced AntixK/PyTorch-VAE directly | Repository dormant since December 2021 — may break on PyTorch 2.x | Use as architecture reference only, rewrite for current APIs |
| Skipped interpolation test | Model trained but encoding is not continuous — sampling produces garbage | Add z-interpolation validation to your spec |
Security & compatibility notes:
- TorchScript: Deprecated as of PyTorch 2.6. Use
torch.exportfor deployment.- torch.load(): Pass
weights_only=True— default changed for security.- AntixK/PyTorch-VAE: 7.6k stars, 18 variants, but dormant since December 2021. May need adaptation for PyTorch 2.x.
Pro Tip
Beta is not a hyperparameter to tune blindly. It is a design decision. For anomaly detection, you want beta slightly below 1.0 — prioritize reconstruction accuracy so anomalies show up as high error. For generation and augmentation, beta at 1.0 or above — prioritize structure so the distribution is smooth enough to sample from.
Specify the downstream task in your prompt. The AI tool picks the right beta value when it knows whether you need faithful reconstruction or smooth generation.
Frequently Asked Questions
Q: How to build a variational autoencoder in PyTorch step by step?
A: Decompose into four concerns: encoder (outputs mu and logvar), reparameterization, decoder, and ELBO loss. Build the loss function first — it defines the contract. Use torch.compile on PyTorch 2.11 for training speed. Beta-anneal from 0.1 to 1.0 to prevent early KL collapse.
Q: How to use variational autoencoder for anomaly detection in production?
A: Train on normal data only, then flag samples with reconstruction error above a threshold — the 0.999 quantile of training loss is a solid baseline. For visual data, specify a ViT-VAE encoder variant. In production, wrap the threshold check in a scoring service and monitor for data drift that shifts the baseline.
Q: How to use VAE for data augmentation when training data is limited?
A: Sample z vectors from the prior and decode to generate synthetic examples. Standard VAEs produce blurrier outputs than GANs, so this works best for tabular data or cases where statistical structure matters more than pixel fidelity. For sharper image augmentation, specify a VQ-VAE variant. Quality-gate synthetic samples before adding them to training.
Q: How to use conditional VAE for controlled image generation with specific attributes?
A: A conditional VAE concatenates class labels or attribute vectors to both encoder and decoder inputs. Specify conditioning dimensions separately from latent dimensions — they serve different purposes. Recent work on Non-Volume Preserving transforms reduced FID by 4% and increased log-likelihood by 7.6% over standard CVAEs (arXiv (NVP-CVAE)).
Your Spec Artifact
By the end of this guide, you should have:
- A four-concern decomposition map — encoder, reparameterization, decoder, loss function, each with defined inputs, outputs, and failure modes
- A constraint checklist — PyTorch version, tensor shapes, beta schedule, loss type, export method, and optimizer settings
- A validation protocol — KL stability, reconstruction quality, prior sampling, and interpolation smoothness
Your Implementation Prompt
Use this prompt in Claude Code, Cursor, or Codex when starting a new VAE project. Fill in the bracketed placeholders with values from your constraint checklist.
Build a variational autoencoder in PyTorch 2.11 with these specifications:
DATA PIPELINE:
- Dataset: [your dataset path or torchvision dataset name]
- Input shape: [B, C, H, W]
- Normalization: [range, e.g., 0 to 1]
- Batch size: [e.g., 128]
ENCODER:
- Architecture: [Conv2d / Linear] layers
- Output: two SEPARATE tensors — mu (B, [latent_dim]) and logvar (B, [latent_dim])
- Weight init: [e.g., Xavier uniform]
REPARAMETERIZATION:
- Separate method: std = exp(0.5 * logvar), eps = randn_like(std), z = mu + eps * std
- Must be differentiable — no detach, no stop_gradient
DECODER:
- Mirror of encoder, reversed. Output shape matches input [B, C, H, W]
- Final activation: [sigmoid for [0,1] inputs / none for MSE loss]
LOSS FUNCTION (ELBO):
- Reconstruction: [BCE for normalized inputs / MSE for continuous]
- KL divergence: closed-form Gaussian KL against N(0,1) prior
- Beta: start at [0.1], anneal linearly to [1.0] over [50] epochs
- Track reconstruction and KL as SEPARATE logged values
TRAINING:
- Optimizer: Adam, lr=[1e-3]. Epochs: [e.g., 100]
- NaN detection: halt on NaN, save last valid checkpoint
- Gradient clipping: [1.0] if KL spikes
- Model export: torch.export (NOT TorchScript)
- Checkpoint loading: weights_only=True
VALIDATION:
- Log reconstruction loss and KL separately per epoch
- Sample 64 z vectors from N(0,1), decode, save grid
- Encode 10 input pairs, interpolate z in 10 steps, decode, save grids
- Flag if KL < 0.01 for 5+ consecutive epochs (posterior collapse)
Ship It
You now have a decomposition framework that prevents the two most common AI-generation failures with VAEs: missing reparameterization and KL collapse. The same four-concern split applies whether you are building for anomaly detection, data augmentation, or controlled generation with a conditional VAE. Spec the components. Spec the loss balance. Validate the parts, not just the total.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors