How to Build a Transformer from Scratch Using PyTorch and Hugging Face
Table of Contents
TL;DR
- Decompose the transformer into five testable components before touching any code
- Specify every constraint — dimensions, masking, positional encoding scheme — or the AI will guess wrong
- Validate attention patterns visually before scaling; broken attention is silent and expensive
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex)
- Working knowledge of Transformer Architecture fundamentals and Multi Head Attention
- Python 3.10+ with PyTorch 2.10 and Hugging Face Transformers 5.x installed via pip — Conda packages are no longer published for PyTorch since version 2.6 (PyTorch Blog)
- A clear picture of what you’re building: a from-scratch implementation, a fine-tuned model, or both — and awareness that State Space Models are an emerging alternative architecture worth watching
This guide teaches you: how to decompose a transformer into individually specifiable components so your AI tool generates each one correctly — instead of hallucinating a monolithic blob that silently fails at training time.
The Problem
You type “build me a transformer in PyTorch” into your AI tool. You get a wall of code. It imports modules that don’t exist in your version. The attention mask is transposed. The positional encoding is hardcoded to a sequence length that doesn’t match your data. Nothing throws an error — it just trains to convergence on garbage.
It worked on Friday. On Monday, the loss curve flatlined because the Context Window assumption changed when you swapped datasets.
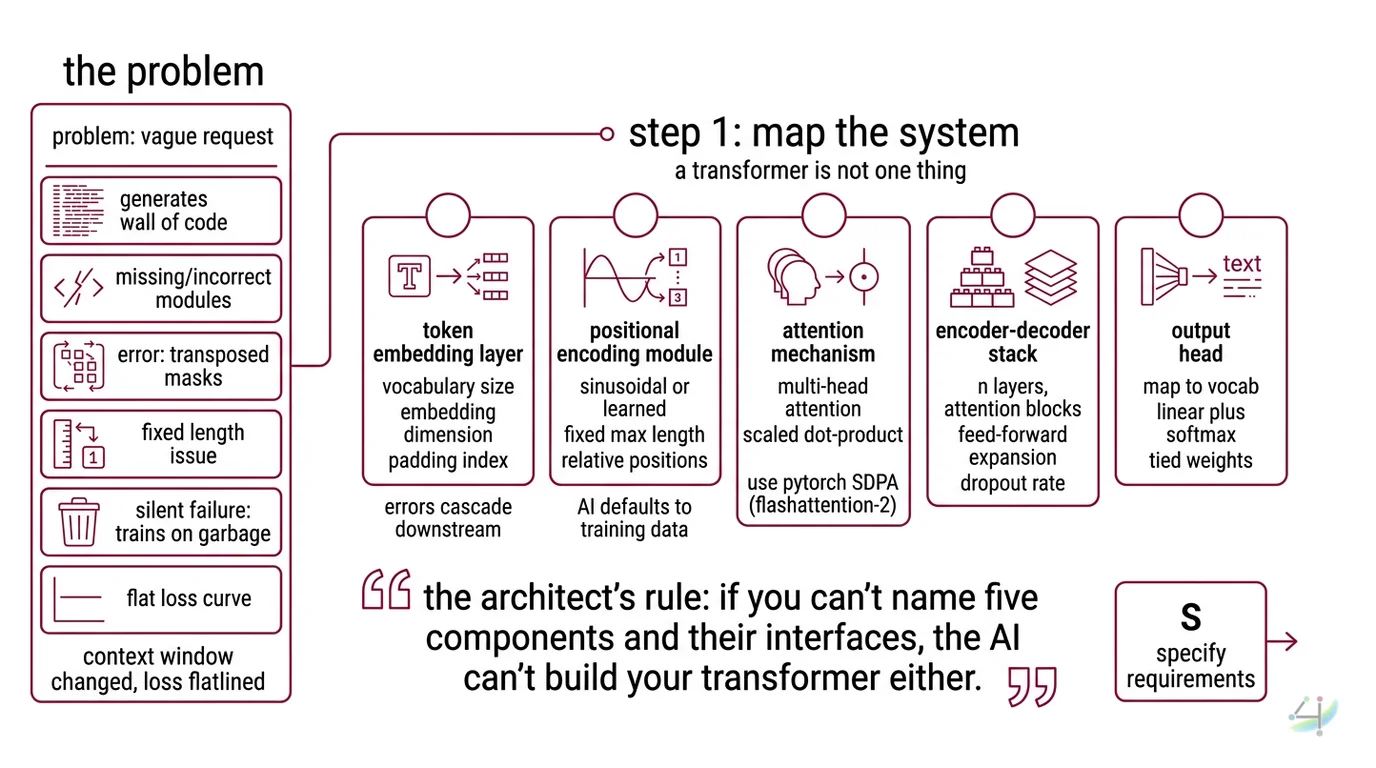
Step 1: Map the System
A transformer is not one thing. It’s five things pretending to be one thing. Your AI tool doesn’t know which five things you mean unless you tell it.
Your system has these parts:
- Token embedding layer — converts raw tokens into dense vectors. This is where Tokenization decisions lock in. Vocabulary size, embedding dimension, padding index. Get this wrong, and every downstream component inherits the error.
- Positional Encoding module — injects sequence order into the embeddings. Sinusoidal or learned. Fixed max length or relative. The AI will default to whatever its training data saw most. That might not be what you need.
- Attention mechanism — the core computation. Multi-head attention with scaled dot-product. PyTorch 2.10 ships
scaled_dot_product_attentionwith FlashAttention-2 integrated (PyTorch SDPA Docs). You want this. You need to specify it. - Encoder Decoder stack — N layers of attention + feed-forward blocks. Layer count, hidden dimension, feed-forward expansion factor, dropout rate. Every number is a constraint. Every unspecified number is a guess.
- Output head — maps decoder output back to vocabulary space. Linear projection plus softmax. Tied weights or separate. This determines whether your model generates text or just burns compute.
The Architect’s Rule: If you can’t name five components and their interfaces, the AI can’t build your transformer either.
Step 2: Define the Constraints
This is where most people skip ahead and pay for it later. Every unspecified constraint becomes a hallucinated default.
Context checklist:
- PyTorch version pinned (2.10.0) and Transformers version pinned (5.3.0, Transformers PyPI) — Transformers v5 is PyTorch-only; TensorFlow and Flax backends were removed (HF Blog)
- Model dimensions:
d_model,n_heads,d_ff,n_layers,max_seq_len,vocab_size - Attention type: vanilla scaled dot-product, or using
torch.nn.functional.scaled_dot_product_attentionfor hardware-accelerated paths - Masking strategy: causal mask for autoregressive, padding mask for variable-length batches, or both
- Weight initialization scheme: Xavier, Kaiming, or Hugging Face defaults
- Dropout rate per component (attention, feed-forward, embedding)
- Device and precision strategy specified — mixed precision (fp16/bf16), device placement
The Spec Test: If your context doesn’t specify
d_modelandn_headstogether, the AI will pick dimensions whered_model % n_heads != 0. Your attention layer will crash at runtime. No warning. Just a shape mismatch three stack frames deep.
Step 3: Sequence the Build
Order matters. Each component depends on the previous one’s output shape. Build out of order, and the AI will invent interface assumptions that don’t match.
Build order:
- Token embedding + positional encoding first — these are foundational. No dependencies. Output shape:
(batch, seq_len, d_model). Every other component consumes this shape. - Single attention head second — because you need to verify the attention computation in isolation before stacking layers. Input and output both
(batch, seq_len, d_model). Masking goes here. - Feed-forward block third — simple expansion and contraction.
d_model → d_ff → d_model. Depends on nothing but dimension specs. - Encoder/decoder layer fourth — composes attention + feed-forward + layer norm + residual connections. This is the integration point. Specify residual connection order (pre-norm vs post-norm).
- Full stack + output head last — N layers stacked, output projection to vocabulary. Tied weights if specified.
For each component, your context must specify:
- What it receives (tensor shapes, dtypes)
- What it returns (tensor shapes, dtypes)
- What it must NOT do (no in-place operations on inputs, no implicit broadcasting)
- How to handle failure (shape assertions at boundaries, not deep inside forward passes)
Step 4: Validate
Don’t just check that it runs. Check that it runs correctly. A transformer that trains without errors but learns nothing is worse than one that crashes — at least crashes are honest.
Validation checklist:
- Shape propagation — pass a dummy batch through each component individually. If any output shape doesn’t match the next component’s expected input, you have a spec gap. Failure looks like:
RuntimeError: mat1 and mat2 shapes cannot be multiplied. - Attention mask correctness — for causal models, future tokens must have zero attention weight. Failure looks like: the model cheats during training and produces suspiciously low loss, then generates garbage at inference.
- Gradient flow — check that gradients reach the embedding layer after one backward pass. Failure looks like: embedding weights never update, model outputs are random regardless of training.
- Positional encoding sanity — swap two tokens in a sequence and verify the output changes. Failure looks like: identical outputs regardless of token order — your positional encoding is dead.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| One-shot “build me a transformer” | Too many concerns; AI picks wrong defaults for every dimension | Decompose into five components, specify each |
| No version pinned | AI generates code for PyTorch 1.x with deprecated APIs | Pin PyTorch 2.10 and Transformers 5.3 in your context |
| Skipped masking spec | AI generates attention without causal mask; model sees future tokens | Specify mask type per attention layer |
Used torch.save / torch.load without weights_only | Default changed to weights_only=True in PyTorch 2.6; old pickle-based checkpoints break silently | Specify weights_only=True explicitly or migrate checkpoint format |
| Tried TorchScript for deployment | Deprecated — your export pipeline breaks on new PyTorch | Use torch.export instead (PyTorch Blog) |
Security & compatibility notes:
- Hugging Face Transformers v5 (BREAKING): TensorFlow and Flax backends removed, tokenizer “fast” vs “slow” distinction eliminated (Rust-only backend), minimum Python raised to 3.10. Existing TF/Flax code will not work. Pin to
transformers>=5.0.- PyTorch
torch.load(since 2.6):weights_only=Trueis now the default. Code relying on pickle-based deserialization will fail. Migrate checkpoints or passweights_only=Falseexplicitly — but never load untrusted checkpoints this way. CVE-2026-24747 (CVSS 8.8) demonstrated aweights_only=Truebypass enabling remote code execution in all PyTorch versions before 2.10.0; upgrade to 2.10.0+ is mandatory (GitHub Advisory).- PyTorch Conda (since 2.6): No longer published on Conda. Use pip for installation.
- TorchScript: Deprecated in favor of
torch.export. Do not use for new deployment pipelines.
Pro Tip
Every transformer component has exactly one job and exactly one output shape. When your AI tool generates a component, check the output shape first. If the shape is right, the logic is probably right. If the shape is wrong, nothing downstream can save it. Shape is the contract. Everything else is implementation detail.
Frequently Asked Questions
Q: How to implement a transformer model from scratch in PyTorch?
A: Decompose into five components — embedding, positional encoding, attention, encoder-decoder layers, output head — and specify interfaces for each before generating code. One extra detail: PyTorch’s built-in nn.Transformer is a reference implementation with limited production features. Use it to learn, plan to replace it.
Q: How to fine-tune a pre-trained transformer with Hugging Face Transformers library?
A: Use the Trainer API with TrainingArguments to specify learning rate, batch size, and evaluation strategy (HF Docs). Load a pre-trained checkpoint, freeze or unfreeze layers selectively, and point the trainer at your dataset. Watch out: Transformers v5 removed the slow tokenizer path — if your data pipeline relies on Python-based tokenizers, it will break silently during preprocessing.
Q: How to use attention visualization to debug transformer models? A: Extract attention weights from your model’s forward pass and plot them as heatmaps. BertViz supports most Hugging Face models for interactive visualization (BertViz GitHub). One caveat: BertViz compatibility with Transformers v5 has not been explicitly confirmed — test on your specific model before building a debug workflow around it.
Your Spec Artifact
By the end of this guide, you should have:
- A component map — five named parts with input/output shapes and interface contracts
- A constraint checklist — every dimension, mask type, initialization scheme, and version pin documented
- A validation protocol — four checks (shape, masking, gradients, positional encoding) with specific failure symptoms
Your Implementation Prompt
Paste this into Claude Code, Cursor, or your AI coding tool of choice. Fill in the bracketed values with your specific constraints from the checklist above.
Build a transformer model in PyTorch 2.10 with the following specification.
## Component 1: Token Embedding + Positional Encoding
- vocab_size: [your vocabulary size]
- d_model: [your model dimension]
- max_seq_len: [your maximum sequence length]
- positional_encoding: [sinusoidal | learned]
- padding_idx: [your padding token index]
- Output shape: (batch, seq_len, d_model)
## Component 2: Multi-Head Attention
- n_heads: [your head count, must divide d_model evenly]
- Use torch.nn.functional.scaled_dot_product_attention
- Masking: [causal | padding | both]
- Dropout: [your attention dropout rate]
- Output shape: (batch, seq_len, d_model)
## Component 3: Feed-Forward Block
- d_ff: [your feed-forward dimension, typically 4 * d_model]
- Activation: [gelu | relu]
- Dropout: [your ff dropout rate]
## Component 4: Encoder/Decoder Layer
- n_layers: [your layer count]
- Norm order: [pre-norm | post-norm]
- Residual connections on attention and feed-forward
- Dropout: [your residual dropout rate]
## Component 5: Output Head
- Weight tying: [yes — share embedding weights | no — separate projection]
- Output: logits over vocab_size
## Constraints
- Device: [cuda | cpu | mps]
- Precision: [fp32 | fp16 | bf16]
- Initialization: [xavier_uniform | kaiming | default]
- No in-place operations on input tensors
- Shape assertions at every component boundary
## Validation
- Include a test function that passes a dummy batch of shape (2, [max_seq_len]) through the full model
- Assert output shape is (2, [max_seq_len], [vocab_size])
- Assert gradients reach the embedding layer after one backward pass
- For causal models: assert future attention weights are zero
Ship It
You now have a decomposition framework for any transformer variant — not just the vanilla one. Encoder-decoder, decoder-only, encoder-only. Same five components. Same constraint checklist. Same validation protocol. The architecture changes. The specification discipline doesn’t.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors