How to Build a Semantic Search Pipeline with Voyage AI, NV-Embed, and Open-Source Models in 2026
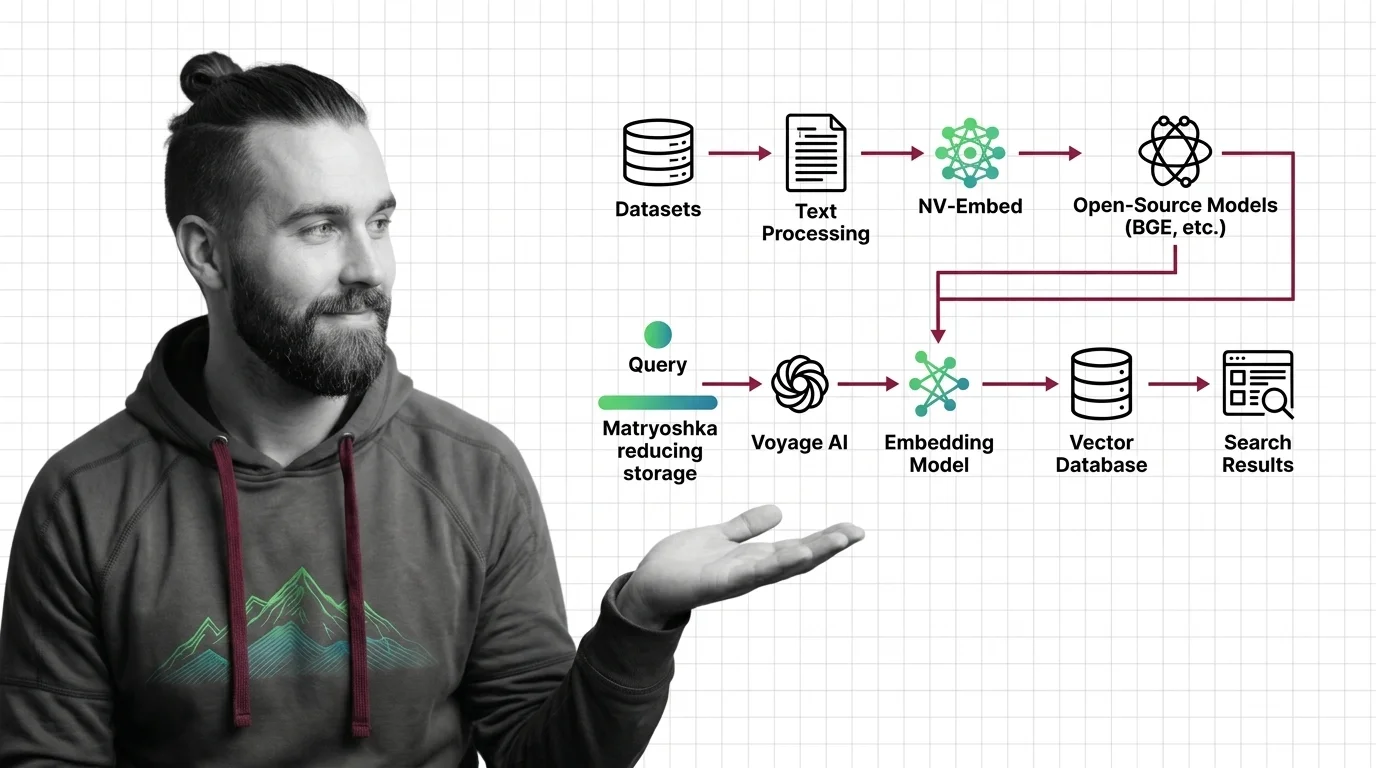
Table of Contents
TL;DR
- Your embedding model choice determines retrieval quality — benchmark scores alone do not predict production performance
- Matryoshka embeddings let you cut vector storage by up to 14x without retraining, but only if your model supports them
- A semantic search pipeline has four specification surfaces: ingest, embed, store, query — skip one and the whole chain breaks
Last week, a team shipped a Semantic Search pipeline built on the top-ranked model from the MTEB leaderboard. Benchmarks looked great. Relevance in production was garbage. Days of debugging later, the root cause: they embedded 12,000-token documents with a model that maxes out at 2,048. Everything past that limit got silently truncated. The model didn’t complain. It just returned vectors for half a document and called it a day.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex)
- A working understanding of Embedding fundamentals — what vectors represent and why dimensions matter
- Familiarity with Cosine Similarity as a retrieval metric
- A Vector Database (Pinecone, Weaviate, Qdrant, or pgvector)
This guide teaches you: how to decompose a semantic search pipeline into four specification surfaces — ingest, embed, store, query — so your AI tool generates a system that retrieves what you actually need.
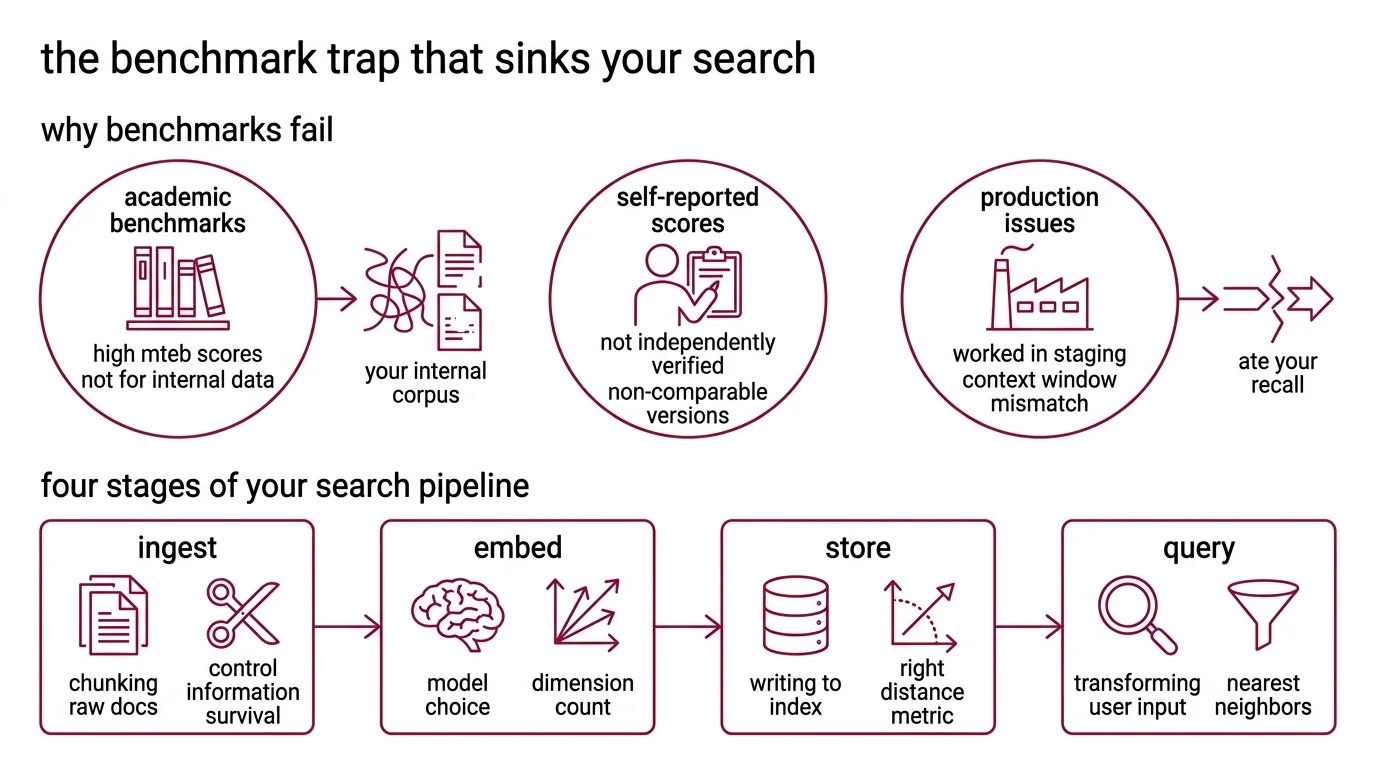
The Benchmark Trap That Sinks Your Search
Here’s the scene I keep finding.
Developer picks the model with the highest MTEB score. Deploys it. Searches for “quarterly revenue analysis” and gets results about “annual expense reports.” Close enough to fool a demo. Not close enough to serve a user.
The model scored well on academic retrieval benchmarks. Your corpus is internal Slack threads, half-finished docs, and PDFs with headers stripped during ingest. Those benchmarks never tested that.
MTEB scores are self-reported by model providers. No independent verification step exists. And the legacy 56-task MTEB benchmark and the current version use different task sets — their scores are not directly comparable. You see a high number next to a lower one and think one model is better. Those numbers measured different things.
It worked in staging. In production, the context window mismatch ate your recall.
Step 1: Map the Four Stages of Your Search Pipeline
Every Word2vec descendant — and that includes every model on this list — converts text to fixed-dimensional vectors. But a semantic search system is not just an embedding model. It is four separate systems pretending to be one.
Your pipeline has these parts:
- Ingest — chunking raw documents into segments the model can actually process. Controls what information survives into the vector.
- Embed — transforming each chunk into a vector. This is where model choice, dimension count, and quantization live.
- Store — writing vectors to an index with the right distance metric. Manages cost, latency, and scale.
- Query — transforming the user’s input into the same vector space and retrieving the nearest neighbors.
Each stage has its own failure modes. Ingest fails silently when chunks exceed the model’s context window. Embed fails when you pick the wrong dimensionality for your latency budget. Store fails when your index uses L2 distance and your model was trained for cosine. Query fails when you embed the question with a different model than the documents.
The Architect’s Rule: If you can’t draw a box around each stage and name its inputs, outputs, and constraints independently — the AI can’t build it either.
Step 2: Nail Down Your Model Contract
This is where most pipelines go wrong. Not in implementation. In selection.
As of March 2026, your realistic options break into three lanes.
Commercial API models:
Voyage 4 ships in four sizes — voyage-4-large, voyage-4, voyage-4-lite, and voyage-4-nano — all sharing a compatible embedding space. That means you can index with voyage-4-large and query with voyage-4-lite to cut inference cost without rebuilding your index (Voyage AI Blog). Pricing runs from $0.12/MTok for voyage-4-large down to $0.02/MTok for lite, with 200M free tokens per account and a 33% batch discount (Voyage AI Pricing). Context window: 32,000 tokens across all variants. The MoE architecture in voyage-4-large delivers roughly 40% lower serving cost versus a dense equivalent (Voyage AI Blog).
OpenAI’s text-embedding-3-large sits at $0.13/MTok with 3,072 default dimensions and native dimension shortening via API. Max context: 8,191 tokens (OpenAI Docs). Fine for short documents. A problem for anything longer.
Gemini Embedding 001 tops the current English MTEB — but maxes out at 2,048 input tokens. That limitation alone disqualifies it for most document-heavy RAG pipelines.
Open-weight models:
NV-Embed-v2 packs 8 billion parameters, 4,096 dimensions, and a 32,768-token context window. But read the license: CC-BY-NC-4.0, which means no commercial use without NVIDIA NeMo Retriever NIMs (Hugging Face).
BGE-M3 runs under MIT license with 1,024 dimensions, 8,192-token context, 100+ languages, and a unique trick — dense, sparse, and ColBERT retrieval from a single model. If you need multilingual and can self-host, it is the least restricted option on the table.
Your model contract must specify:
- Max input tokens per chunk (match your ingest chunking)
- Output dimensions (and whether you will reduce them)
- License constraints (CC-BY-NC kills commercial without NIMs)
- Quantization support (int8, binary, or none)
- Cost ceiling per million tokens
Security & compatibility notes:
- Voyage AI SDK:
get_embeddingandget_embeddingsare deprecated. UseClient.embed()instead.- NVIDIA NIM embedqa: The
llama-3.2-nv-embedqa-1b-v2API endpoint is deprecated as of 2026-05-18. Migrate before that date.
Step 3: Wire Ingest, Index, and Query
Order matters. Build ingest first, because every downstream decision depends on chunk size.
Build order:
- Ingest first — because chunk length constrains model choice. If your documents average 15,000 tokens, you need a model with at least a 16K context window. Set overlap at 10-15% of chunk size to preserve cross-boundary context.
- Embed second — because your ingest output defines the input contract. Specify the model, output dimensions, and quantization here. If your model supports Matryoshka representations, this is where you choose your operating dimension.
- Store third — because dimension count and quantization from the embed stage determine your index schema. Set the distance metric (cosine for normalized embeddings), configure HNSW parameters, and specify metadata fields.
- Query last — because it mirrors the embed stage. Same model. Same dimensions. Same normalization. If you mixed models here, your vectors live in different spaces and cosine similarity returns noise.
Matryoshka embeddings deserve a callout. Kusupati et al. showed that Matryoshka Representation Learning produces embeddings that stay useful at reduced dimensions — up to 14x smaller at equivalent accuracy (Kusupati et al.). In practice, this means you can embed at 1,024 dims and store at 256 for cheaper indexing, then re-rank with the full vector. Voyage 4, OpenAI text-embedding-3, and Nomic Embed v1.5 support this natively. BGE-M3 does not — you would need Dimensionality Reduction as a post-processing step, which loses the training-time guarantee.
For each stage, your context must specify:
- What it receives (raw text, chunked segments, vectors, or queries)
- What it returns (chunks with metadata, vectors with IDs, ranked results)
- What it must NOT do (never embed a chunk longer than the model’s context window)
- How to handle failure (retry on API timeout, log and skip corrupt documents)
Step 4: Prove Retrieval Works Under Pressure
You built it. Now break it.
Not by running ten happy-path queries and nodding. By designing tests that expose the failure modes you specified away in Steps 1 through 3.
Validation checklist:
- Recall at K — run 50+ known query-document pairs. If recall@10 drops below your threshold, your chunking is too aggressive or your dimension reduction went too far. Failure looks like: relevant documents exist in the index but never appear in results.
- Cross-boundary retrieval — query for information that spans two adjacent chunks. Failure looks like: partial answers, missing the second half of a concept. Fix: increase overlap or add parent-document metadata.
- Out-of-domain queries — search for topics not in your corpus. Failure looks like: confident but wrong results instead of empty. This is where your distance threshold matters — set a minimum cosine similarity floor.
- Latency under load — measure p95 query latency with your production index size. Failure looks like: sub-second in dev, multi-second in production because HNSW parameters were tuned for a small index, not a production-scale one.
Common Pitfalls
| What You Did | Why Search Failed | The Fix |
|---|---|---|
| Picked model by MTEB score alone | Benchmark tasks do not match your corpus | Test on your actual documents before committing |
| Embedded 15K-token docs with an 8K-context model | Silent truncation — vectors represent half the content | Match chunk size to model context window |
| Mixed embedding models between index and query | Vectors live in incompatible spaces | Same model, same dimensions, both sides |
| Stored full-dimension vectors without reduction | Storage costs balloon, latency spikes at scale | Use Matryoshka dims or quantization |
| Skipped the license check | CC-BY-NC model in a commercial product | Read the license before writing the first line |
Pro Tip
Your embedding model is not your search system. It is one component in a four-stage pipeline. The developers who build reliable retrieval are the ones who specify the contract between each stage before they write a single line of code. The model is replaceable. The architecture is not.
Frequently Asked Questions
Q: How to build an embedding-powered semantic search pipeline from scratch in 2026? A: Decompose into four stages — ingest, embed, store, query — and specify each before writing code. One detail the article does not cover: start validation on a subset of your corpus first. Index a few hundred documents, run your recall tests, and fix chunking issues before scaling to millions of vectors.
Q: Which embedding model to choose for RAG: Voyage 4, NV-Embed v2, BGE, or OpenAI text-embedding-3 in 2026? A: Match license, context window, and budget to your use case. One detail worth noting: voyage-4-nano is open-weight, so you can run it locally for prototyping and switch to the API variants for production — same embedding space, no re-indexing required.
Q: How to use Matryoshka embeddings to reduce vector storage costs without losing retrieval accuracy? A: Embed at full dimension and truncate for storage. The practical tip the article skips: benchmark your retrieval at multiple truncation points — 256, 512, and 1,024 dims — against your actual queries. The sweet spot varies by corpus. Legal documents tolerate more aggressive reduction than code repositories.
Your Spec Artifact
By the end of this guide, you should have:
- A four-stage pipeline map with explicit boundaries between ingest, embed, store, and query
- A model selection contract specifying context window, dimensions, license, quantization, and cost ceiling
- A validation checklist with recall@K thresholds, cross-boundary tests, and latency benchmarks
Your Implementation Prompt
Paste this into Claude Code, Cursor, or Codex after filling in your specific constraints. Every bracketed placeholder maps to a decision from Steps 1 through 4.
Build a semantic search pipeline with the following specification:
INGEST STAGE:
- Source format: [your document type — PDF, Markdown, HTML, Slack exports]
- Chunking strategy: [fixed-size / semantic / paragraph-level]
- Chunk size: [token count matching your model's context window]
- Overlap: [10-15% of chunk size]
- Metadata to preserve: [title, source URL, timestamp, section heading]
EMBED STAGE:
- Model: [voyage-4 / voyage-4-large / text-embedding-3-large / bge-m3]
- Output dimensions: [full dims or Matryoshka-reduced target]
- Quantization: [int8 / binary / none]
- Batch size: [number of chunks per API call]
- Error handling: retry [N] times on timeout, log and skip corrupt inputs
STORE STAGE:
- Vector database: [Pinecone / Weaviate / Qdrant / pgvector]
- Distance metric: cosine
- Index type: [HNSW / IVF — specify parameters]
- Metadata fields: [list from ingest metadata]
QUERY STAGE:
- Same embedding model as EMBED STAGE
- Top-K: [number of results to return]
- Minimum similarity threshold: [cosine floor]
- Re-ranking: [full-dimension Matryoshka re-rank / cross-encoder / none]
VALIDATION:
- Test with [N] known query-document pairs
- Measure recall@[K] — target: [your threshold]
- Test cross-boundary retrieval with [N] spanning queries
- Measure p95 latency at [expected index size] vectors
Ship It
You now have a four-stage decomposition that separates every failure mode into its own box. The model is a choice inside the pipeline — not the pipeline itself. Next time someone asks which embedding model is best, you have a better question: best for which stage, at what context length, under what license, at what cost?
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors