How to Build a Retrieval-Augmented Agent with LangGraph, LlamaIndex, and CrewAI in 2026
Table of Contents
TL;DR
- A Retrieval Augmented Agents system is three contracts, not one pipeline: decide-to-retrieve, retrieve-and-ground, then act.
- Compose frameworks by job. LangGraph owns control flow, LlamaIndex owns documents, CrewAI owns roles.
- Specify the retrieval contract before you pick a framework. The framework is the cheapest decision in the stack.
Friday afternoon. The vanilla RAG demo passes every test the team wrote. Monday morning, a sales engineer asks the same question two ways and gets two answers — one correct, one a confidently hallucinated policy that does not exist in any document. The retriever did its job. The agent did its job. The contract between them was never written down. That is what we are going to fix.
Before You Start
You’ll need:
- An AI coding tool (Cursor, Claude Code, or Codex) with project context turned on
- A working knowledge of Agentic RAG versus vanilla RAG
- A picture of what your agent must DECIDE, not just what it must answer
- Python 3.10+ for LlamaIndex; LlamaIndex deprecated Python 3.9 in March 2026 (llama-index PyPI page)
This guide teaches you: how to decompose a retrieval-augmented agent into three independent specifications before you write a single graph node, retriever, or crew.
The Demo That Lied On Monday
The failure mode is always the same. You wire a retriever to an LLM, ship the demo, and the system answers correctly most of the time. The bad answer, when it comes, is wrong in a way that looks right. No traceback. No retrieval miss. The model retrieved the wrong chunk and committed to it.
It worked on Friday. On Monday, the user phrased the question with a synonym, the retriever returned a near-miss, and the agent never decided whether to retry, rewrite, or refuse. That decision was the agent’s job — and the spec did not include it.
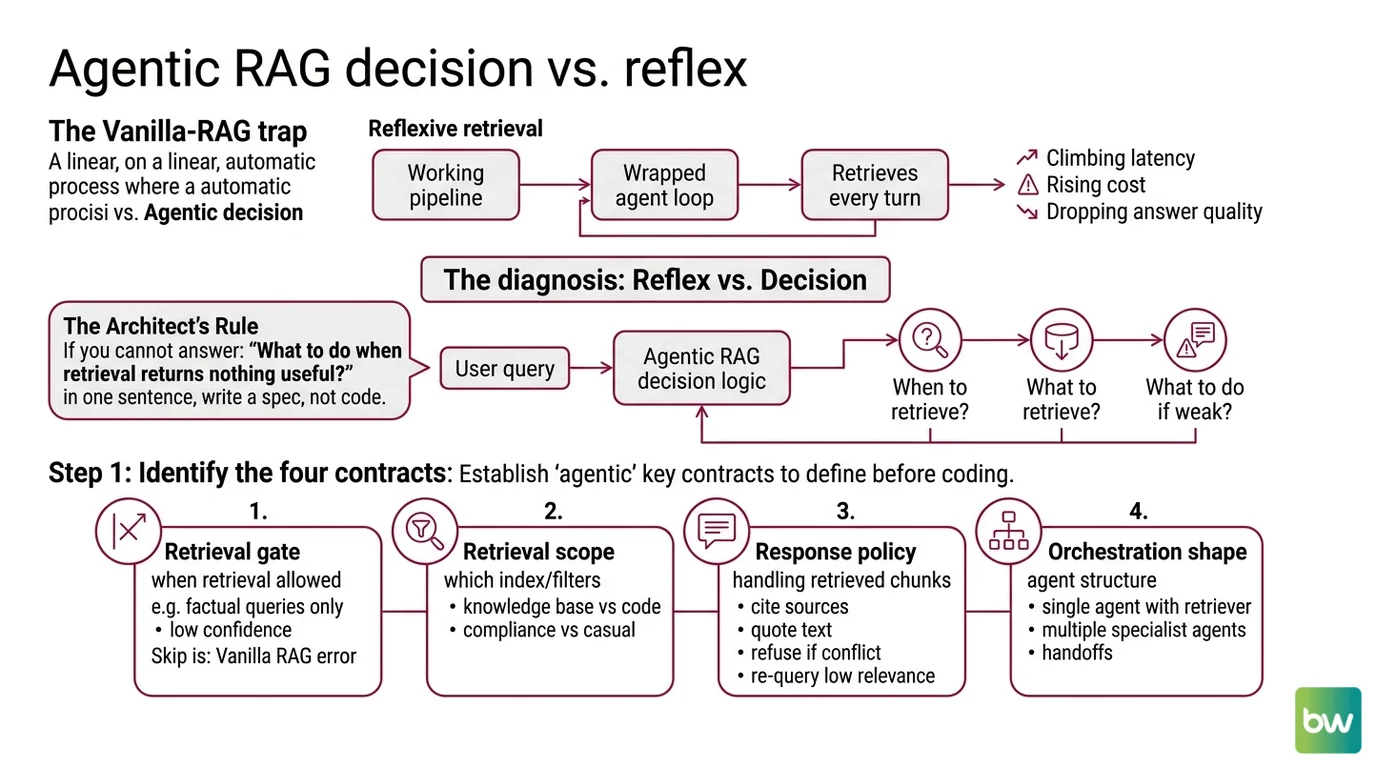
Step 1: Identify the Agent’s Three Decision Layers
A retrieval-augmented agent is not a pipeline. It is a graph of decisions. Before you pick a framework, name the decisions explicitly.
Your system has these parts:
- Router — decides whether the user’s question needs retrieval at all, or whether the model can answer from its own weights. LangChain Docs call this the
generate_query_or_respondnode, where the LLM chooses between invoking the retriever tool or answering directly. - Retriever + grader — fetches candidate documents and judges whether they actually answer the question. LlamaIndex Blog describes this as per-document agents performing embedding search and summarization under a top-level coordinator agent.
- Responder + verifier — synthesizes the answer and checks it against the retrieved context. Hallucination escapes here when no verifier exists.
Three layers. Three contracts. If your spec collapses them into one prompt, you cannot debug a failure when it happens — because every failure looks like “the agent was wrong.”
The Architect’s Rule: If you cannot name which layer failed when the agent lies, you do not have an agent — you have a prompt with extra steps.
Step 2: Lock Down the Retrieval Contract
Before any framework code, write the contract each layer obeys. The retrieval contract is the one that breaks first under production load.
Context checklist:
- Embedding model and version pinned (different versions produce incompatible vectors)
- Chunk size chosen against actual document structure, not a default
- Top-k retrieved, top-n after reranking — two separate numbers, both specified
- Grading criteria: when is a retrieved chunk “good enough” to ground an answer?
- Refusal path: what does the agent do when no chunk is good enough?
- Failure logging: which decision the agent made, and which documents it saw
The grading and refusal paths are where most teams skip the spec. They assume the LLM will “figure it out.” It will not. It will pick the closest chunk and answer with conviction.
The Spec Test: If your context does not name the refusal path, your agent will hallucinate confidently the first time retrieval returns near-misses instead of misses.
Step 3: Wire Each Framework to the Job It Actually Owns
This is where teams pick a single framework, hit its boundary, and start fighting it. Do not. The 2026 consensus from production-tested rankings is that the three leading frameworks do different jobs well, and the best path is composition, not monoliths (Alice Labs).
Build order:
LangGraph for the control layer — Build the router and the grader-driven re-query loop here. LangGraph 1.1.10 (released April 4, 2026) added type-safe streaming, per-node timeouts, and node-level error handlers — exactly the primitives an agent needs when retrieval calls hang or rerankers crash (LangChain’s changelog). Use it because the state machine is explicit, not because it ships every battery you need.
LlamaIndex for the retrieval and grounding layer — LlamaIndex 0.14.22 is the leading framework for document-grounded retrieval, with AgentWorkflow as the current primitive on top of Workflows 1.0 (LlamaIndex Docs). The per-document agent pattern lets each document expose both embedding search and summarization, so your top-level agent can ask “is this answer in document X?” before re-querying.
CrewAI for the role layer, when you need one — If your agent’s behavior depends on roles (researcher, fact-checker, summarizer), CrewAI 1.14.0 gives you the cleanest abstraction (CrewAI’s changelog). Use Flows, not plain Crews, when orchestration is non-trivial. If your agent has one role, skip this layer. A crew of one is just a function call with extra ceremony.
For your control layer, treat Workflow Orchestration For AI as a separate concern from the agent itself — retries, queues, and scheduling sit outside the graph. The same separation applies if your agent dispatches to Code Execution Agents: those are tools the responder calls, not layers inside the agent.
For each layer, your context must specify:
- What it receives (inputs from the upstream layer)
- What it returns (outputs the downstream layer can rely on)
- What it must NOT do (cross-layer concerns to stay out of)
- How to handle failure (timeouts, empty retrievals, grader rejections)
Security & compatibility notes:
- LangGraph RCE (CVE-2026-27794): Remote code execution in checkpoint deserialization, affecting versions <3.0. Fix: upgrade
langgraph-checkpointto 4.0.0 (NVD).- LangGraph SQL injection (CVE-2025-67644): SQL injection in the SQLite checkpoint implementation via metadata filter keys (The Hacker News). Avoid untrusted metadata keys; patch on release.
- LangChain Core secrets exposure (CVE-2025-68664): Unsafe JSON serialization fallback now removed. Patch and audit any custom serializers (NVD).
langgraph-prebuilt1.0.2 breaking change: Requiredruntimeparam added toToolNode.afunc— breaks code that overridesafunc. Pin versions explicitly.- LlamaIndex migration: Pre-2025
OpenAIAgentandReActAgentexamples are superseded byAgentWorkflowandFunctionAgent. Use Workflows 1.0 patterns.
Step 4: Prove Retrieval Quality Before You Trust the Agent
Validation for a retrieval-augmented agent is two-layer: retrieval correctness and agent decision correctness. Most teams only test the second one and then wonder why the agent fails.
Validation checklist:
- Retrieval recall on a labeled question set — failure looks like: the correct chunk exists in your corpus but is not in top-k
- Reranker precision after retrieval — failure looks like: top-k contains the answer but the reranker buries it
- Router accuracy — failure looks like: agent retrieves for questions the LLM should answer from weights, or skips retrieval when it should not
- Grader calibration — failure looks like: grader passes near-misses, agent answers with conviction
- Refusal coverage — failure looks like: zero refusals across a test set that includes adversarial out-of-scope questions
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| One framework for everything | LangGraph forced into retrieval, or LlamaIndex forced into multi-role orchestration | Compose: LangGraph for control, LlamaIndex for retrieval, CrewAI for roles |
| No grader between retriever and LLM | Agent answers from near-miss chunks with full confidence | Add an explicit document grading node before generation |
| Skipped the refusal path | Agent fabricates when retrieval returns nothing useful | Specify “no good chunk” branch in the graph, with a refusal response |
| Pinned framework, not versions | langgraph-prebuilt 1.0.2 changed ToolNode.afunc signature and broke deploys | Pin exact versions; read changelogs before upgrading |
| Self-hosted LangGraph without observability | Bugs surface as silent re-queries, not exceptions | Either run on LangGraph Platform or wire your own tracing — there is no third option |
Pro Tip
The framework is the cheapest part of the stack. The retrieval contract is the most expensive. Most teams reverse this — they spend two weeks choosing between LangGraph and LlamaIndex, then write the retrieval grading prompt in twenty minutes. Flip the budget. Specify what “a correct retrieval” looks like for your domain first. Then pick the framework that lets you encode that spec with the least friction. If you change frameworks later, the spec carries; if you change the spec, every framework choice you made may be wrong.
Frequently Asked Questions
Q: How to build a retrieval-augmented agent step by step in 2026? A: Decompose into three layers (router, retriever-grader, responder-verifier), write the contract for each, then wire LangGraph for control, LlamaIndex for retrieval, and optionally CrewAI for roles. Build the grader before the router — if your grader cannot tell a good retrieval from a bad one, no amount of routing logic will save the agent.
Q: How to use retrieval-augmented agents for enterprise knowledge search? A: Use LlamaIndex’s per-document agent pattern so each document exposes both embedding search and summarization, then put a coordinator agent on top to choose documents per query (LlamaIndex Blog). The trap: enterprise corpora have access controls. Pass user permissions into the retrieval contract from day one, or your agent will surface documents the user is not allowed to see.
Q: When should you use an agentic RAG framework instead of vanilla RAG? A: Use Agentic RAG when retrieval needs decisions — when to retrieve, when to re-query, when to refuse, when to combine sources. Vanilla RAG is fine for single-shot Q&A over homogeneous content. If your evaluation set includes questions that require multi-hop reasoning or refusal, vanilla RAG will silently fail those, and you need the decision layers an agent provides.
Your Spec Artifact
By the end of this guide, you should have:
- A three-layer decomposition of your agent (router, retriever-grader, responder-verifier) with named inputs, outputs, and failure modes for each
- A retrieval contract that specifies embedding model, chunk strategy, top-k/top-n, grading criteria, and refusal path
- A two-layer validation plan covering both retrieval correctness and agent decision correctness
Your Implementation Prompt
Paste this into Claude Code or Cursor at the start of your project. It encodes the three-layer decomposition and forces you to fill in the contracts before any code is generated.
You are helping me build a retrieval-augmented agent. Do not write code until
all sections below are filled in. If a section is empty, ask me for it.
DECOMPOSITION (Step 1)
- Router responsibility: [decide whether retrieval is needed for this query type]
- Retriever-grader responsibility: [fetch and grade documents from this corpus]
- Responder-verifier responsibility: [generate answer and verify against context]
RETRIEVAL CONTRACT (Step 2)
- Embedding model + version: [your value]
- Chunk size + overlap: [your value, justified by document structure]
- Top-k retrieved: [your value]
- Top-n after reranking: [your value]
- Grading criteria — when is a chunk good enough: [your value]
- Refusal response template — when no chunk is good enough: [your value]
- Access control fields to enforce at retrieval: [your value or "none"]
BUILD ORDER (Step 3)
- Control framework: LangGraph (pin langgraph >=1.1.10, langgraph-checkpoint >=4.0.0)
- Retrieval framework: LlamaIndex (pin llama-index-core ==0.14.22; do NOT use OpenAIAgent/ReActAgent — use AgentWorkflow)
- Role framework: CrewAI only if [your value: agent has 2+ distinct roles]
VALIDATION (Step 4)
- Labeled question set with expected retrieval chunks: [path or "to build"]
- Adversarial set including out-of-scope questions: [path or "to build"]
- Pass criteria for retrieval recall: [your value]
- Pass criteria for refusal coverage: [your value]
When generating code, follow this order: validation harness first, then
retrieval layer, then control graph, then responder. Do not generate any layer
before its contract above is filled in.
Ship It
You now have a decomposition that survives framework choices. The router, the retriever-grader, and the responder-verifier are independent contracts — if you change LangGraph for something else next year, the contracts carry. The framework is replaceable. The spec is the asset.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors