Reproducible Image-Prompt Testing 2026: Promptfoo, Seeds, A/B

TL;DR
- A reproducible image- Prompt Engineering For Image Generation pipeline is a contract, not a script. Spec the seed, the provider version, the assertion suite, and the CI gate before you call a single API.
- Promptfoo gives you the matrix view and the GitHub Action; it does not give you a first-class “seed” assertion for image providers. You wire seeds through provider config and validate with image-similarity assertions you choose.
- “Same seed = same image” is a managed-API marketing line, not a guarantee. OpenAI’s seed is best-effort, Midjourney’s is similar-not-identical, and Diffusers can drift across CUDA versions. Your spec must pick a determinism tier and assert against it.
A designer reruns last week’s hero-shot prompt. Same words. Same seed. Different image. The team blames the model, then the moon phase, then the intern. The truth is duller: the OpenAI backend system_fingerprint rotated overnight, the Promptfoo config moved from 0.121.4 to 0.121.7 in CI, and the assertion that was supposed to catch this drift was a thumbs-up emoji on a Notion page. Nothing crashed. Everything is unreproducible.
Before You Start
You’ll need:
- An AI coding tool (Claude Code, Cursor, or Codex) for specification-assisted implementation
- Working knowledge of prompt engineering for image generation and how prompt-level changes interact with sampler-level randomness in Diffusion Models
- A clear list of which image providers you actually ship through — managed APIs, self-hosted Diffusers, or both — and which downstream tasks (cover art, AI Image Editing, AI Background Removal, Image Upscaling) consume the output
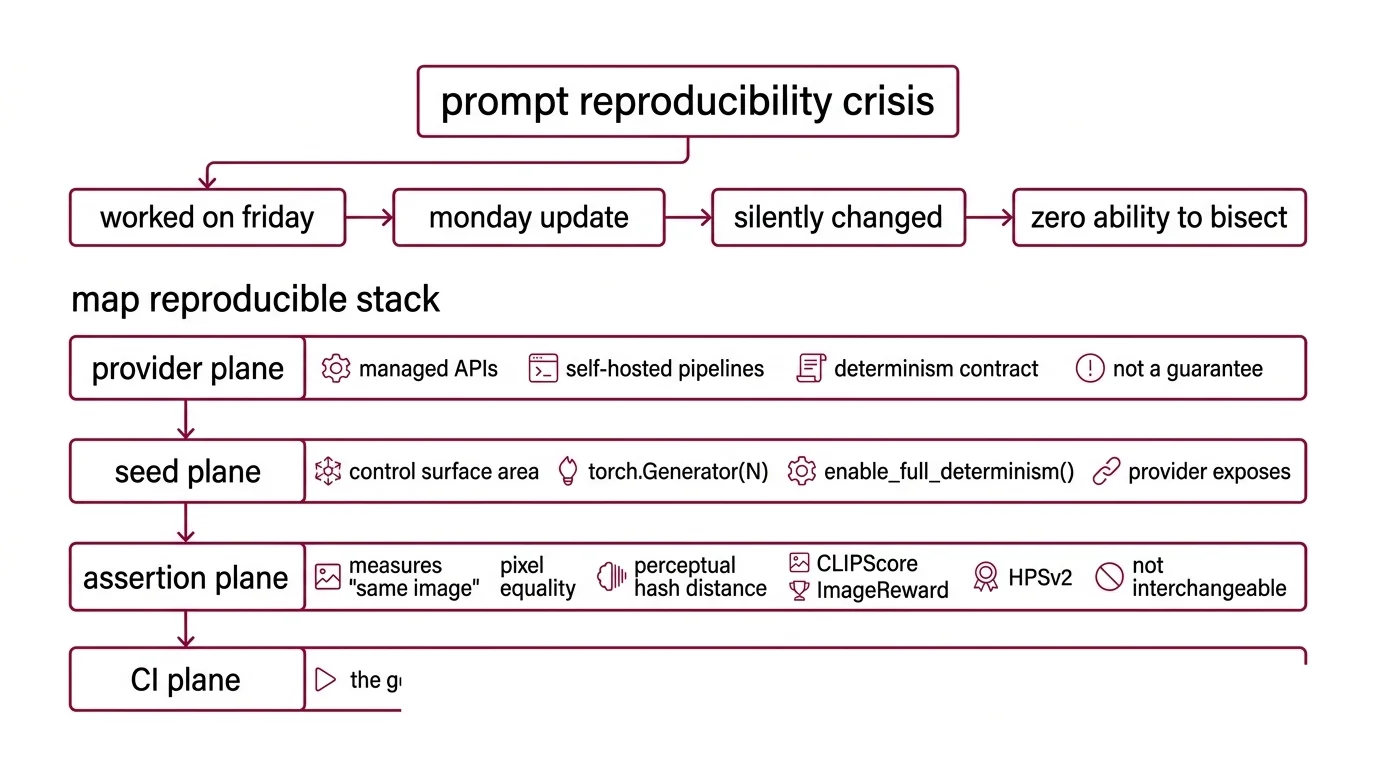
This guide teaches you: how to decompose an image-prompt eval into four planes — provider contracts, seed control, assertion suite, and CI gate — so “reproducible” becomes a measurable property of your pipeline instead of a hopeful adjective.
The Hero Shot That Stopped Reproducing on a Tuesday
Most image-gen teams test prompts the way they test landing pages — eyeball the result, screenshot the good ones, ship. That is not testing. That is curation. The first time a prompt drifts in production you have no baseline image, no recorded seed, no provider version pinned, and no assertion that would have caught the change. You have a Slack thread.
It worked on Friday. On Monday, Midjourney shipped a default-version flip, an OpenAI backend update rotated system_fingerprint, and a teammate bumped Promptfoo from one patch release to the next. Three silent changes, one composite “the image looks different now,” zero ability to bisect.
Step 1: Map What “Reproducible” Actually Means in Your Stack
There is no universal definition of reproducibility for image generation in 2026. There is a stack of tiers, and you pick which one your contract holds against. Hugging Face Diffusers Docs put it bluntly: “you can try to limit randomness, but it is not guaranteed even with an identical seed” across releases, GPUs, and CUDA versions. Treat that sentence as the foundation of your spec, not a footnote.
Your pipeline has these parts:
- Provider plane — every image backend you call: managed APIs (FLUX.2 Pro/Flex, Midjourney V8.1 Alpha, gpt-image-2, Imagen, Veo) and self-hosted Diffusers pipelines. Each has a different determinism contract, and the contract is a property of the provider, not of your code.
- Seed plane — the deterministic surface area you actually control. For Diffusers, that is
torch.Generator(device="cpu").manual_seed(N)plusenable_full_determinism(). For managed APIs, it is whatever the provider exposes — and “exposes” is not the same as “guarantees.” - Assertion plane — what counts as “the same image.” Pixel equality, perceptual hash distance, CLIPScore against a reference caption, ImageReward, or HPSv2. Each measures a different thing; none of them are interchangeable.
- CI plane — the gate that runs the matrix on every prompt change, every provider bump, every model upgrade. Promptfoo owns this layer and posts the diff on the PR.
The Architect’s Rule: “Reproducible” is a tier you declare, not a property you assume. Pick the tier first; everything else follows.
Step 2: Lock the Contract for Every Provider You Test
This is where most image-prompt test suites quietly fall apart. A team writes one Promptfoo config, points it at three providers, and assumes “seed: 42” means the same thing everywhere. It does not. The contract for each provider is different, the failure modes are different, and the right assertions are different.
Context checklist:
- Promptfoo as the harness — open-source CLI and library for evaluating and red-teaming LLM apps, per Promptfoo Docs. Install via
npx promptfoo@latest initthennpx promptfoo@latest eval. Pin the version in CI: the project shipped five patch releases in April 2026 alone (0.121.4 through 0.121.8 as of April 24, 2026, per Promptfoo’s GitHub releases). A floating@latestis a third source of drift on top of the providers and the models. - Promptfoo image-gen providers in scope — Google Imagen has been wired in since June 2025; gpt-image-1 and gpt-image-2 plus Veo via Google AI Studio and Vertex landed in v0.121.7 in April 2026; OpenAI Sora and Google Veo support arrived in December 2025 (Promptfoo’s release notes). If your stack uses a provider Promptfoo does not yet wrap, you write a custom provider — do not pretend the matrix view covers it.
- FLUX.2 (Pro / Flex / Dev) — Black Forest Labs released FLUX.2 on November 25, 2025 as a 32-billion-parameter latent flow-matching transformer with seed support for deterministic outputs (Black Forest Labs Blog). Pro and Flex are managed endpoints; Dev is open-weight. Spec which variant a given test row targets — “FLUX.2” alone is not a contract.
- Midjourney V7 / V8.1 Alpha — V7 became default on June 17, 2025 after its April 3, 2025 release; V8.1 Alpha shipped in 2026, and Midjourney Docs describe seeded reruns as “99% identical,” not pixel-identical. The seed parameter is
--seed <n>with an integer range of 0 to 4,294,967,295. Treat Midjourney as a similar-image provider, not an identical-image provider, in any assertion you write. - OpenAI gpt-image-1 / gpt-image-2 — OpenAI API Docs describe seed as “best effort to sample deterministically… repeated requests with the same seed and parameters should return the same result, though determinism is not guaranteed.” Pair every seeded request with the returned
system_fingerprint; when the fingerprint changes, the backend changed and your baseline is invalid. Community reports indicate that adding an image input on top of a seeded request — typical for edit-style flows — breaks determinism further. - Diffusers self-host — Pass
torch.Generator(device="cpu").manual_seed(N)to the pipeline; the CPU generator is recommended even when running on GPU (Hugging Face Diffusers Docs). For tighter control, callenable_full_determinism()— this setsCUBLAS_WORKSPACE_CONFIG=:16:8, disables cuDNN benchmark, and disables TF32. Even then,AttnProcessor2_0is documented to produce different outputs with the same seed across consecutive runs (Hugging Face Diffusers Issue #3061), and CUDA Graphs requireCUDAGraph.register_generator_state()for RNG capture.
The Spec Test: Trace one prompt with seed 42 through FLUX.2 Pro, gpt-image-2, and a self-hosted Diffusers SDXL pipeline. If your config does not record provider version, exact seed semantics, expected determinism tier, and the assertion threshold for each leg, you are not testing — you are sampling.
Step 3: Wire the Seed Plane, the Matrix, and the Assertions
Your build order matters because the matrix only earns trust once the layer underneath it is sound. Build seed control first, then the matrix view, then the assertion suite — never the other way around.
Build order:
- Seed control per provider — because every other plane reads from this one. Specify, for each provider, exactly how the seed is set, what its range is, and what the documented determinism tier is (pixel-identical, similar, or best-effort). Record the seed and any backend fingerprint with every output. No seed control, no reproducibility — at any tier.
- Provider-fan-out matrix — because the cross-product of prompts × providers × seeds is the actual unit of test. Promptfoo Docs describe the harness as producing “matrix views that let you quickly evaluate outputs across many prompts.” Use the matrix to compare a single prompt against multiple providers, and a single provider against multiple prompt variants. Both axes catch different bugs.
- Assertion suite — because a green matrix without assertions is theater. Pick a determinism tier per provider and a metric per tier. For pixel-identical claims (Diffusers with
enable_full_determinism()on a frozen environment): SHA-256 of the output, or zero perceptual-hash distance. For similar-image providers (Midjourney, gpt-image-2 with seed): perceptual hash distance under a documented threshold, plus CLIPScore against a reference caption. Use ImageReward or HPSv2 only as supplementary signals — arXiv 2507.19002 reports that both are biased toward large guidance scales, meaning you can game the score by raising CFG without improving image quality. Do not let either be the gate. - CI gate via the GitHub Action — because human review at PR time is where the previous three planes either pay off or get bypassed. The Promptfoo GitHub Action posts a before/after diff as a PR comment with a link to the web viewer; key inputs are
config,github-token, provider API keys, andfail-on-threshold(Promptfoo’s GitHub Action repo). Wirefail-on-thresholdso a regression below the assertion floor blocks the merge.
For each provider in your matrix, your context must specify:
- What it receives (prompt template, resolved variables, seed, model variant)
- What it returns (image URL or bytes, plus any backend fingerprint or version field)
- What it must NOT do (silently retry, fall back to a different model, drop the seed)
- How to handle failure (timeout, rate limit, fingerprint rotation, missing seed support)
Step 4: Prove the Pipeline Catches the Drift It Was Built to Catch
Validation here is not “did the test suite run?” — it is “did the test suite refuse to ship the regressions you actually fear?” Drive a known-bad change through the pipeline before you trust it.
Validation checklist:
- Seed-respect check — failure looks like: same seed, same prompt, same provider version producing two outputs whose perceptual-hash distance exceeds your declared threshold. If this passes silently, your provider’s seed is not behaving as documented and your contract is wrong.
- Provider-version drift check — failure looks like: gpt-image-2 returns a different
system_fingerprintbetween runs and the matrix shows green anyway. If this passes silently, your assertion suite is not reading the fingerprint. - Prompt-paraphrase consistency — failure looks like: a paraphrased prompt that should produce a similar image (same composition, same intent) produces an image that fails the CLIPScore threshold. This is metamorphic testing applied to image generation; it catches prompt-template regressions that a single golden seed cannot.
- Cross-environment drift check (Diffusers only) — failure looks like: same seed, same model, same Diffusers version, different CUDA or GPU generation, output diverges beyond the perceptual-hash threshold. This is expected behavior — the assertion is whether your spec acknowledges the tier downgrade or pretends the pipeline is portable.
- License and provider-mode check — failure looks like: a test row that targeted FLUX.2 Pro silently fell back to FLUX.2 Dev, or a LoRA for Image Generation variant attached to a base-model assertion. The matrix should fail closed when a row’s contract is not met.
Security & compatibility notes:
- Promptfoo version drift: No CVEs known as of April 2026, but the project shipped five patches in a single month. Pin a specific version in CI; do not float
@latest.- OpenAI seed parameter: Documented as best-effort, not guaranteed. Adding image inputs on top of a seeded request degrades determinism further. Do not promise pixel-identical outputs in test names.
- Diffusers determinism:
AttnProcessor2_0can produce different outputs with the same seed across consecutive runs (HF issue #3061); CUDA Graphs needCUDAGraph.register_generator_state()for RNG capture.enable_full_determinism()reduces but does not eliminate cross-hardware drift.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
One config, every provider, single seed: 42 | “Seed” means different things across FLUX.2, Midjourney, OpenAI, and Diffusers; the matrix runs but the contract is fictional | Spec a determinism tier per provider; pick a per-tier assertion |
| Eyeballing thumbnails on the matrix view | A reviewer cannot detect a perceptual-hash drift below their visual threshold; subtle regressions ship | Wire CLIPScore + perceptual-hash assertions and let fail-on-threshold block the merge |
Floating promptfoo@latest in CI | Five patch releases in a month means the harness itself is a moving baseline | Pin a specific Promptfoo version; bump deliberately, with a recorded diff |
| HPSv2 or ImageReward as the gate | Both are biased toward large guidance scales — raising CFG raises the score regardless of quality (arXiv 2507.19002) | Use them as supplementary signals only; gate on CLIPScore + perceptual hash |
No system_fingerprint recorded | OpenAI backend updates rotate the fingerprint; your “same seed, same output” claim quietly becomes false | Log system_fingerprint with every response; assert it has not changed since the baseline |
Pro Tip
Treat every assertion as a mini-spec the AI coding tool can extend. Promptfoo Docs describe assertions for JSON structure, semantic similarity, and custom validation functions — and assertions are also where most teams stop. The leverage is not in adding a fifth metric. It is in writing each assertion as a contract that names what the metric measures, what threshold it holds against, and what it does not protect against. An assertion without a stated boundary is just a number with confidence.
Frequently Asked Questions
Q: How to build a systematic prompt testing workflow for image models step by step?
A: Spec the four planes in order — provider contracts, seed plane, assertion suite, CI gate — then wire Promptfoo’s matrix view as the runner and its GitHub Action as the gate. The detail most teams miss: log the provider version and any backend fingerprint with every output and assert it has not rotated since the baseline. Without that field, “same seed, same image” is a hypothesis, not a test.
Your Spec Artifact
By the end of this guide, you should have:
- A four-plane map (provider contracts, seed plane, assertion suite, CI gate) for your specific stack
- A determinism-tier table — pixel-identical, similar, or best-effort — declared per provider, with the metric and threshold that gates each tier
- A Promptfoo config plus GitHub Action wiring with
fail-on-thresholdset, a pinned harness version, and recorded provider versions and fingerprints
Your Implementation Prompt
Paste the prompt below into your AI coding tool (Claude Code, Cursor, Codex) once you have filled the bracketed values from the four steps above. The structure mirrors the decomposition — provider contracts, seed plane, assertion suite, CI gate — so the generated module ends up shaped like the pipeline you specified, not whichever tutorial the model saw last.
You are scaffolding a reproducible image-prompt testing pipeline.
Follow this decomposition exactly: provider contracts -> seed plane
-> assertion suite -> CI gate. Do not deviate.
PROVIDER CONTRACTS (one block per provider in scope)
- Provider + model: [e.g., FLUX.2 Pro | Midjourney V8.1 Alpha |
gpt-image-2 | Diffusers SDXL self-host]
- Pinned version / model variant: [exact endpoint or checkpoint]
- Determinism tier: [pixel-identical | similar | best-effort]
- Seed parameter name and range: [Diffusers torch.Generator manual_seed |
Midjourney --seed 0..4,294,967,295 | OpenAI seed (best-effort) |
FLUX.2 seed]
- Required logged fields: [seed, system_fingerprint or equivalent,
Promptfoo version, provider version]
- MUST NOT: silently fall back to another model; drop the seed; mix
image-edit inputs into a seeded request without flagging tier downgrade
SEED PLANE
- Diffusers: [torch.Generator(device="cpu").manual_seed(N);
call enable_full_determinism() yes/no]
- Managed APIs: [seed pass-through rules; fingerprint capture;
edit-mode determinism downgrade rules]
- Storage: [seed + fingerprint recorded with every output]
ASSERTION SUITE (per determinism tier)
- Pixel-identical: [SHA-256 equality | perceptual-hash distance == 0]
- Similar: [perceptual-hash distance < threshold T1; CLIPScore vs.
reference caption > threshold T2]
- Best-effort: [CLIPScore floor only; record drift as warning]
- Supplementary (non-gating): [HPSv2 | ImageReward — never as sole signal]
- Metamorphic check: [paraphrased prompt -> similar-tier assertion]
CI GATE (Promptfoo GitHub Action)
- Pinned Promptfoo version: [e.g., 0.121.8]
- Inputs: config, github-token, provider API keys, fail-on-threshold
- fail-on-threshold value: [numeric; per-tier]
- Output: PR comment with before/after diff and web-viewer link
ERROR HANDLING
- Provider timeout -> [retry policy; fail-closed on second timeout]
- Fingerprint rotation -> [warn; flag baseline as stale]
- Determinism-tier downgrade detected -> [block merge; require spec update]
- Seed unsupported by provider -> [hard-stop; the row does not run]
Generate the Promptfoo config, the assertion module, the CI workflow,
and a short README explaining how to add a new provider without
touching the assertion suite or the CI gate.
Ship It
You now have a pipeline that treats reproducibility as a contract per provider, not a hope per prompt. When FLUX.3 lands, when Midjourney V9 changes the seed semantics, when OpenAI rotates system_fingerprint again, when Diffusers ships a new attention processor — you record the new contract, you re-baseline the assertion suite, and the rest of the system does not move. The providers change. The four planes do not.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors