RAG Evaluation Harness with RAGAS, DeepEval, and TruLens in 2026
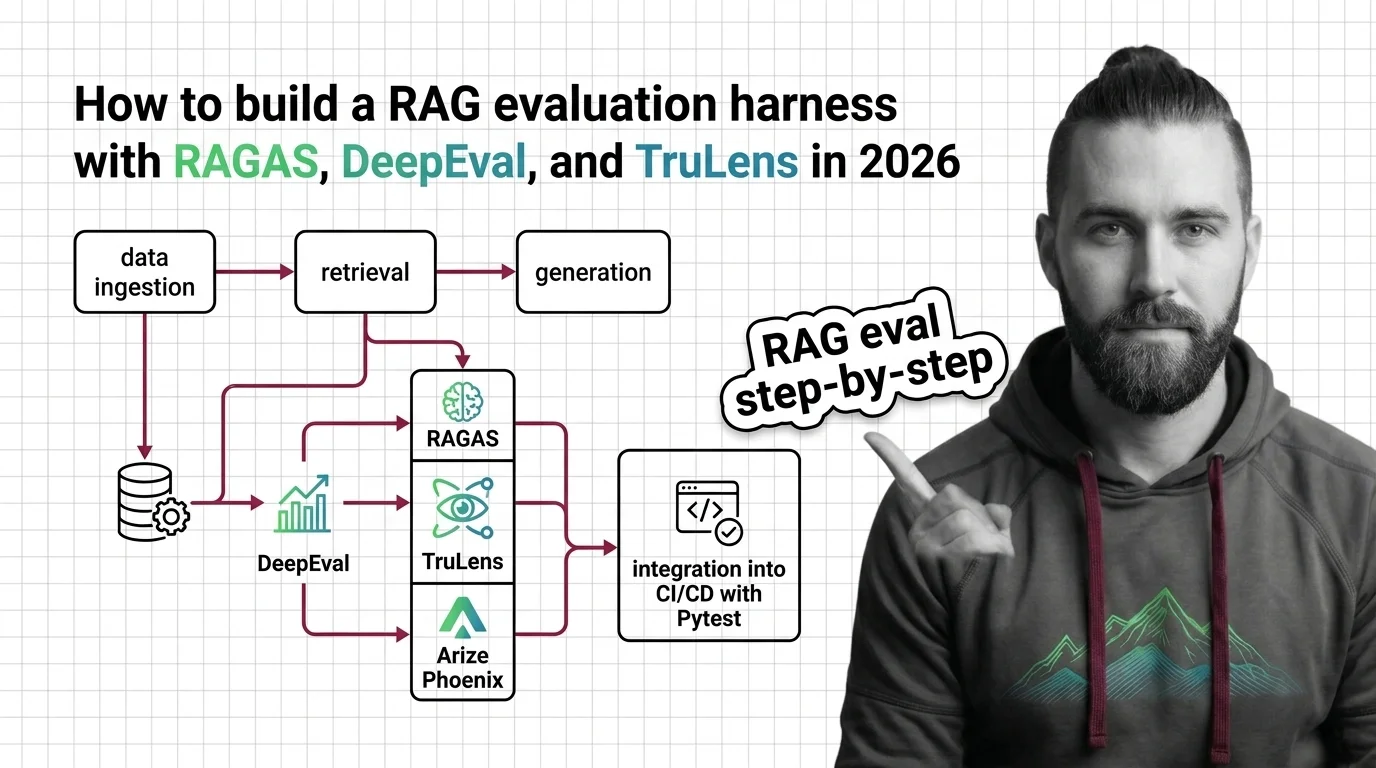
Table of Contents
TL;DR
- A RAG evaluation harness is a spec, not a script — name the metrics, the thresholds, and the failure modes before you pick a tool.
- The 2026 stack splits cleanly: RAGAS for metric science, DeepEval for CI/CD gates, TruLens for trace-aware observability, Phoenix for retrieval visualization.
- Treat retrieval and generation as separate scoring contracts. Mixing them is the #1 reason teams ship a “passing” RAG pipeline that hallucinates in production.
You shipped the RAG demo. The CEO loved it. Three weeks later, a user pastes a screenshot into Slack — wrong citation, confident wrong answer, no idea when it started failing. Nobody owns the regression because nobody owns the score. That’s not a model problem. That’s a missing harness.
Before You Start
You’ll need:
- A working RAG pipeline (any framework — LangChain, LlamaIndex, Haystack, or hand-rolled)
- Python 3.10+ environment (TruLens requires it; RAGAS and DeepEval allow 3.9+)
- A judge LLM endpoint (OpenAI, Anthropic, Bedrock, or a local model — all three libraries are model-agnostic)
- Familiarity with RAG evaluation concepts and the difference between retrieval and generation failure modes
This guide teaches you: How to decompose RAG quality into a five-component scoring contract, then assemble a harness that runs locally, in CI, and as a drift monitor in production.
The “It Works on My Laptop” RAG Disaster
Most RAG teams ship without an Evaluation Harness because the early demo felt right. That’s the failure mode. You eyeball five queries, the answers look fluent, and you push to staging. By the time a user reports a hallucinated citation, your retrieval index has drifted, your prompt template has mutated through three PRs, and you have no baseline to diff against.
It worked on Friday. On Monday, the answer to “What’s our refund policy?” cited a deprecated wiki page because the new ingestion job replaced the chunk and nobody re-scored the eval set.
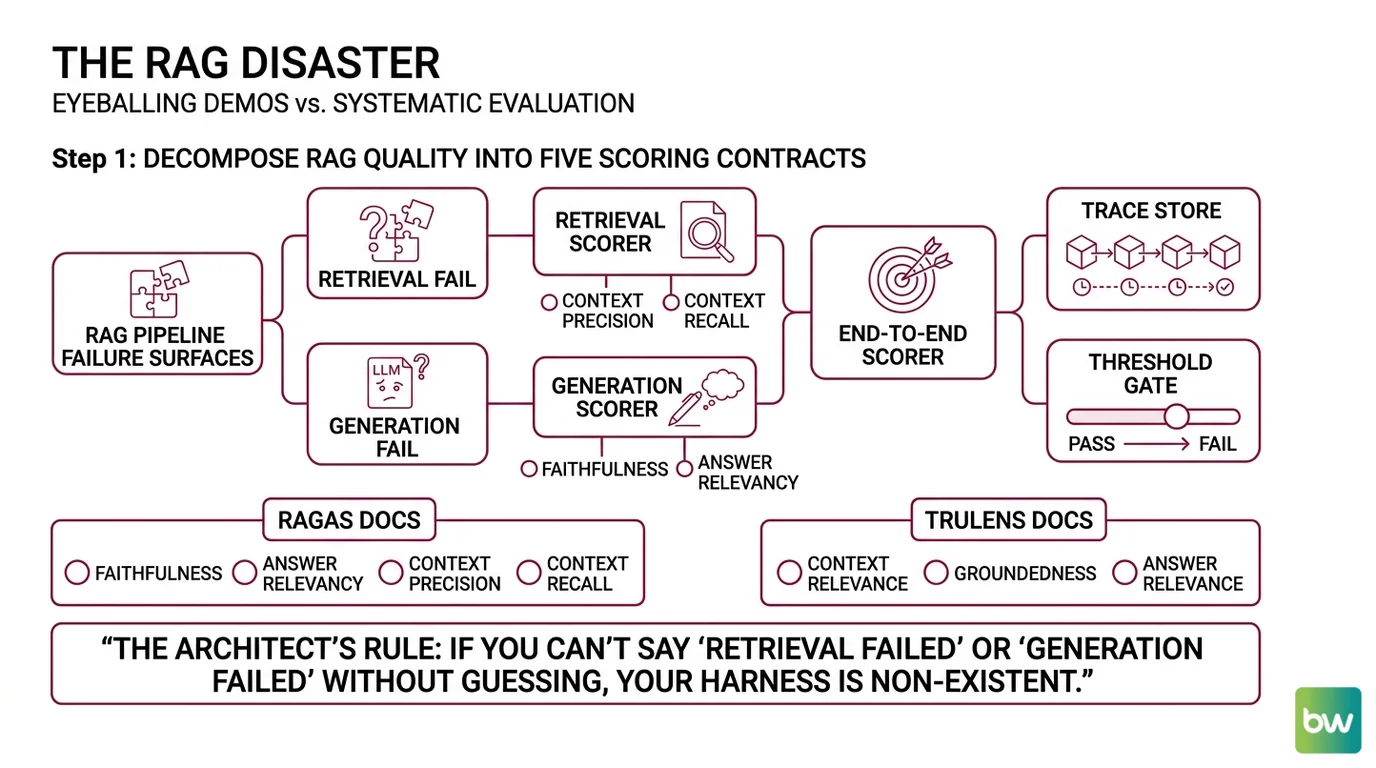
Step 1: Decompose RAG Quality Into Five Scoring Contracts
A RAG pipeline has two distinct failure surfaces. Retrieval can fail (wrong chunks fetched). Generation can fail (right chunks ignored or misread). Mixing them into one “answer quality” number hides which side broke.
Your harness has these parts:
- Retrieval scorer — judges what came back from the vector store before the LLM saw it. Owns Context Precision and Context Recall.
- Generation scorer — judges the answer given the retrieved context. Owns Faithfulness and Answer Relevancy.
- End-to-end scorer — judges the user-facing answer against ground truth. Catches gaps the component scores miss.
- Trace store — captures every retrieval call, prompt, and response as structured spans. Without this, you can score but not debug.
- Threshold gate — turns a score into a pass/fail decision. The score is data; the threshold is policy.
The RAGAS Docs put the same four core metrics at the heart of the library — Faithfulness, Answer Relevancy, Context Precision, Context Recall. The TruLens Docs name a tighter version the “RAG Triad” — Context Relevance, Groundedness, Answer Relevance. The metric names differ. The decomposition is the same.
The Architect’s Rule: If you can’t say “retrieval failed” or “generation failed” without re-running the query, your harness is undercooked.
Step 2: Lock Down the Scoring Contract
Before you wire any tool, write down what each metric scores and what threshold ships. This is the spec the harness enforces. Without it, you’ll tune scores after the fact to make the build green.
Scoring contract checklist:
- Each metric named with the exact library it comes from (RAGAS Faithfulness ≠ DeepEval Faithfulness — same name, different judge prompt)
- Judge LLM and version pinned (a metric scored by
gpt-4o-miniis not the same metric scored byclaude-3-5-sonnet) - Threshold per metric defined (e.g., faithfulness ≥ 0.85, context recall ≥ 0.75)
- Eval dataset versioned in git, separate from training data
- Failure mode mapped per metric: faithfulness drop → prompt or hallucination; context recall drop → ingestion or chunking; answer relevancy drop → query rewrite or routing
- Sampling rate for production traces specified (you cannot score 100% of traffic affordably)
The Spec Test: If your harness reports “score: 0.82” and nobody on the team can say what fails first when that number drops to 0.74, you’re collecting telemetry, not running an evaluation.
The breaking change to watch for: RAGAS v0.4 removed LangchainLLMWrapper, LlamaIndexLLMWrapper, AspectCritic, and SimpleCriteriaScore, and metrics now return a MetricResult object (score plus reasoning) instead of a raw float. Snippets from v0.1–v0.3 will not run on 0.4.x without migration to llm_factory(). Bake this into the spec so the harness pins a known-good RAGAS line.
Security & compatibility notes:
- RAGAS v0.4 breaking change:
LangchainLLMWrapper,LlamaIndexLLMWrapper,AspectCritic, andSimpleCriteriaScoreremoved; metrics now returnMetricResult. Migrate viallm_factory()(RAGAS Docs migration guide). Pin to RAGAS 0.4.3+.- TruLens API deprecation: The
FeedbackAPI is replaced by the newMetricclass (TruLens 2.7.0+). Old code still runs with deprecation warnings — new harness code should useMetricwith explicitselectors={}(TruLens’s GitHub repository).- TruLens Python floor: TruLens 2.8.0 requires Python ≥3.10, <4.0 (TruLens on PyPI). Older 3.8/3.9 setups will not install.
Step 3: Wire the Harness in Three Layers
Build order matters because each layer depends on the one below it. Skip a layer and the harness either misses regressions or fails noisily without telling you why.
Build order:
- Layer 1 — Local metrics with RAGAS (no infrastructure dependencies). RAGAS 0.4.3 is the metric science layer (RAGAS on PyPI). It computes Faithfulness, Answer Relevancy, Context Precision, and Context Recall on a static eval set with a judge LLM. This is your baseline — the score you measure against on every PR.
- Layer 2 — Test runner with
Deepeval (depends on Layer 1’s score definitions). DeepEval 3.9.9 is the Pytest-style framework with 50+ metrics across RAG, agentic, multi-turn, MCP, multimodal, and safety (DeepEval Docs). Install via
pip install -U deepevaland run withdeepeval test run test_rag.py(parallelize with-n 4). DeepEval is what makes a metric a CI gate. - Layer 3 — Trace-aware observability with TruLens or Phoenix. TruLens 2.8.0 is OpenTelemetry-native and self-hostable under Snowflake (Snowflake Engineering Blog). Phoenix is the alternative — open-source LLM tracing with OpenInference, UMAP retrieval visualization, and native integration with RAGAS and DeepEval (Phoenix Docs).
For each layer, your spec must specify:
- What it receives (query, retrieved chunks, generated answer, ground truth)
- What it returns (per-metric score, threshold pass/fail, reasoning trace)
- What it must NOT do (judge across layers — keep retrieval and generation scoring separate)
- How to handle failure (judge LLM rate-limited → retry with backoff; metric returns None → log and treat as fail, never as pass)
A reasonable starting split: RAGAS for the metric definitions, DeepEval as the harness runner, Phoenix or TruLens for traces. The three integrate cleanly.
Step 4: Prove the Harness Catches What You Care About
A harness that always passes is worse than no harness. Prove it catches regressions on a known-bad pipeline before you trust the green light on a real one.
Validation checklist:
- Inject a retrieval regression — swap in a worse reranker, confirm Context Precision and Context Recall both drop. If scores stay flat, your eval set isn’t exercising the affected query class.
- Inject a generation regression — change the prompt to “answer briefly” with no grounding instruction. Faithfulness should fall while Context Precision stays flat. If faithfulness stays flat, the judge LLM is too lenient — pin a stricter one.
- Run the same eval twice with different judge models — scores should agree within a tight band. A wide swing means the metric is noisy, not the pipeline. Average across multiple judge runs or switch to a more deterministic metric.
- Pull a production trace into the harness — every span should be reproducible offline. A missing context field means your tracer isn’t capturing the retrieval payload. Fix the instrumentation before trusting any score.
- Trigger the CI gate on a deliberately broken PR — the build must fail, the failed metric must be named, and the PR comment must point at the specific test case. The Confident AI Blog walks through this pattern with faithfulness threshold gates failing the GitHub Actions build.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Single “answer quality” score | Hides whether retrieval or generation broke | Score retrieval and generation separately; use the RAG Triad or RAGAS’s four-metric split |
| Eval set built from prompts you already passed | Scores are inflated; harness misses real failure modes | Add adversarial queries, edge cases, and historical user complaints to the eval set |
| Different judge LLMs across runs | Score variance is judge drift, not pipeline drift | Pin the judge model and version in the harness spec |
| No threshold defined upfront | Team retrofits thresholds to make the build green | Set thresholds before tuning the pipeline; treat them as a contract, not a slider |
| Tracing only the final answer | You can score but not debug | Capture every retrieval call, rerank, and prompt as a structured span via TruLens or Phoenix |
Pro Tip
The harness is a system, not a script. The score is the easy part — the hard part is making the score actionable. Every metric in your harness should map to a single team that owns the fix when it drops. Faithfulness drops? Prompt team. Context Recall drops? Retrieval team. Answer Relevancy drops? Query routing team. If two metrics map to the same owner, you’ve under-decomposed. If a metric maps to nobody, delete it — an unowned score is noise.
Frequently Asked Questions
Q: How to build a RAG evaluation harness step by step in 2026? A: Decompose quality into the five contracts above, write the threshold spec before you pick a tool, and wire RAGAS for metrics, DeepEval for the test runner, and TruLens or Phoenix for traces. The non-obvious step: rebuild your eval set from production traces every quarter — the queries users actually send drift faster than your code does, and a stale eval set lets new failure modes through.
Q: How to use RAGAS to evaluate a production RAG pipeline?
A: Pin RAGAS 0.4.3+, run the four core metrics (Faithfulness, Answer Relevancy, Context Precision, Context Recall) over a versioned eval set with a fixed judge LLM, and store every MetricResult (score plus reasoning) — not just the float. Watch out for the v0.4 breaking change: anywhere your old code passed a LangchainLLMWrapper you now need llm_factory(), and metrics now return objects, not floats.
Q: When to choose DeepEval vs TruLens vs Arize Phoenix for RAG evaluation? A: DeepEval if your team writes Pytest already and wants CI/CD gates with the least glue code. TruLens if you need OpenTelemetry-native traces and the RAG Triad as your scoring contract — it’s now backed by Snowflake and self-hostable. Phoenix if observability and UMAP-style retrieval visualization matter more than out-of-box metrics — Phoenix integrates with RAGAS and DeepEval, so it’s not strictly either/or.
Q: How to integrate RAG evaluation into CI/CD with Pytest and DeepEval?
A: Write tests with DeepEval’s metric assertions, set a threshold per metric, and run deepeval test run test_rag.py (parallelize with -n 4) in your GitHub Actions workflow. Treat the build as failed if any threshold misses. The Confident AI blog has a working recipe — note that DeepEval’s official docs do not publish a turnkey GitHub Actions YAML, so frame any sample workflow as illustrative, not canonical.
Your Spec Artifact
By the end of this guide, you should have:
- A scoring contract document naming the four-to-five metrics, their judge LLM, their thresholds, and the team that owns each failure mode
- A versioned eval dataset in git, with adversarial cases and at least one example per failure mode
- A validation log proving the harness catches deliberate regressions in retrieval, generation, and tracing — before you trust it on real PRs
Your Implementation Prompt
Use this in Cursor, Claude Code, or Codex when you’re scaffolding the harness. It encodes the four-step decomposition above so the AI builds against your contract, not its training bias.
You are scaffolding a RAG evaluation harness for [your project name].
Build it in four layers, in this exact order:
1. SCORING CONTRACT (Layer 0 — write before code)
- Metrics: [pick from RAGAS Faithfulness, Answer Relevancy,
Context Precision, Context Recall, or TruLens RAG Triad]
- Judge LLM: [model name and version, e.g., gpt-4o-2024-08-06]
- Thresholds: [per-metric, e.g., faithfulness >= 0.85]
- Eval dataset path: [path/to/eval_set.jsonl, versioned in git]
- Failure-mode owner per metric: [team name]
2. METRICS LAYER (RAGAS 0.4.3+)
- Pin ragas>=0.4.3 in requirements
- Use llm_factory() — NOT LangchainLLMWrapper (removed in v0.4)
- Persist MetricResult objects (score + reasoning), not floats
- Treat None or judge errors as fail, never as pass
3. TEST RUNNER LAYER (DeepEval 3.9.9+)
- Write Pytest-style tests asserting each metric against threshold
- Command: deepeval test run test_rag.py -n 4
- On CI failure: surface the failing metric name and reasoning
in the PR comment
4. TRACE LAYER (TruLens 2.8.0 or Phoenix)
- If TruLens: use the Metric class with selectors={} (NOT the
deprecated Feedback API), Python >=3.10
- Capture every retrieval call, rerank, and prompt as an
OpenTelemetry span
- Make every offline-scored trace reproducible from the trace store
5. VALIDATION (run before trusting the harness)
- Inject a retrieval regression — confirm Context Precision/Recall drop
- Inject a generation regression — confirm Faithfulness drops
- Run twice with different judge models — confirm scores agree
- Trigger a deliberately failing PR — confirm CI blocks the merge
Constraints:
- Keep retrieval and generation scoring separate. Do NOT collapse to
one number.
- Do NOT invent metric thresholds. Use [the values from my contract].
- Do NOT default to a judge model. Use [my pinned model].
- Code must run on a fresh checkout with no manual setup beyond
`pip install -r requirements.txt` and an API key env var.
Ship It
You now have a five-component decomposition that turns “is the RAG good?” into five answerable questions, each with an owner and a threshold. The harness isn’t the tools — it’s the scoring contract. The tools just enforce it. Pick the stack that fits your team’s CI muscle memory, write the contract before you write the test, and re-score on every PR.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors